Department of Computer and Network Engineering, The University of Electro-Communications, Chofu, Tokyo, Japan.
Institute of Education, Tokyo Medical and Dental University, Bunkyo-ku, Tokyo, Japan.
PLoS One. 2024 Sep 6;19(9):e0309887. doi: 10.1371/journal.pone.0309887. eCollection 2024.
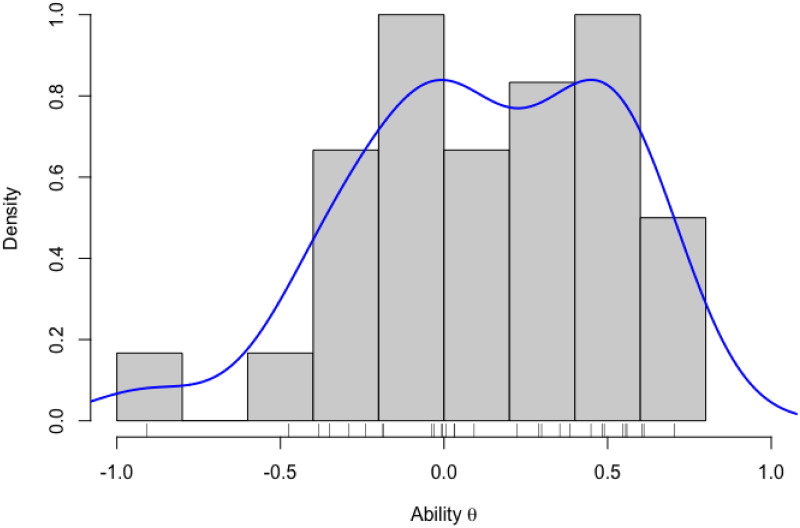
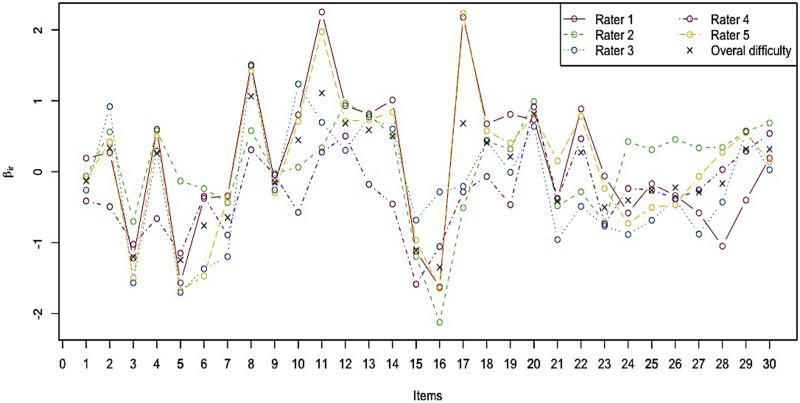
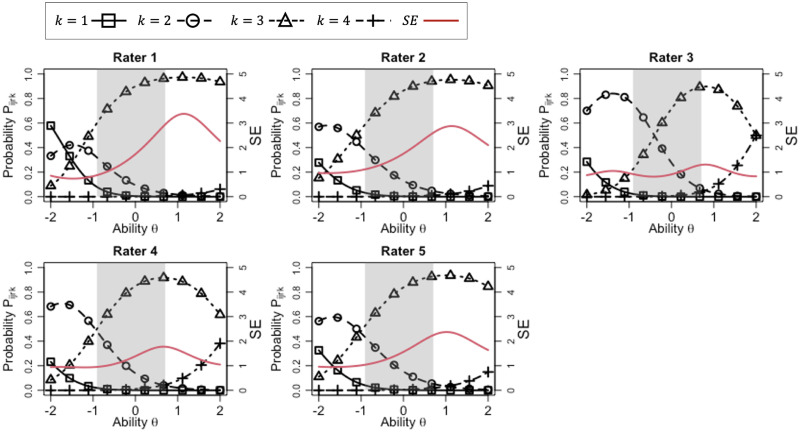
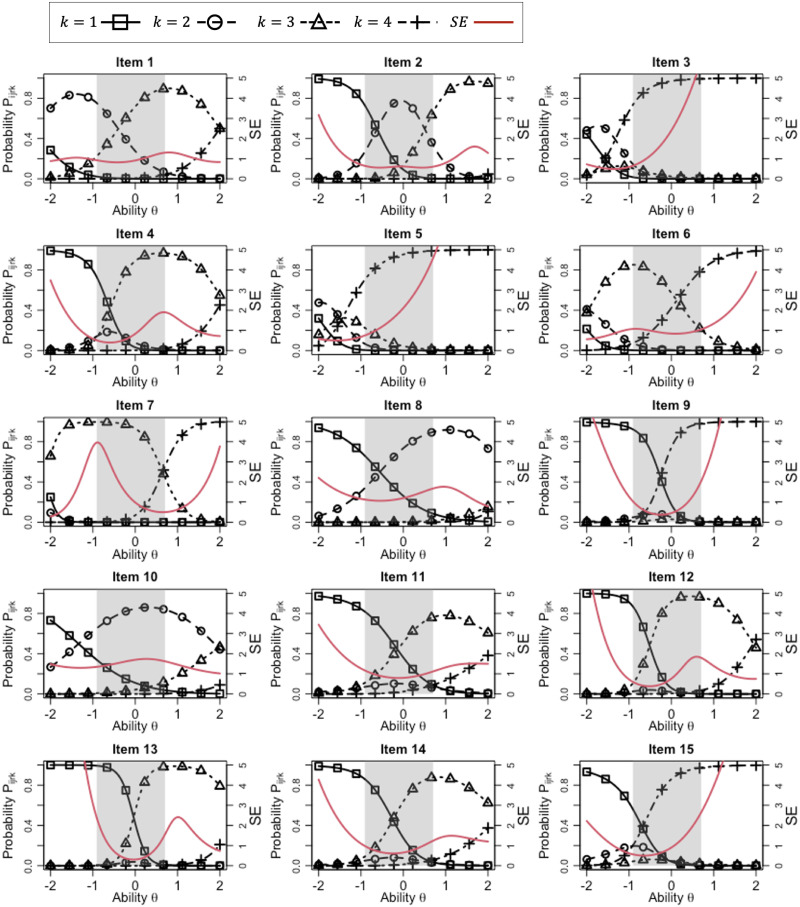
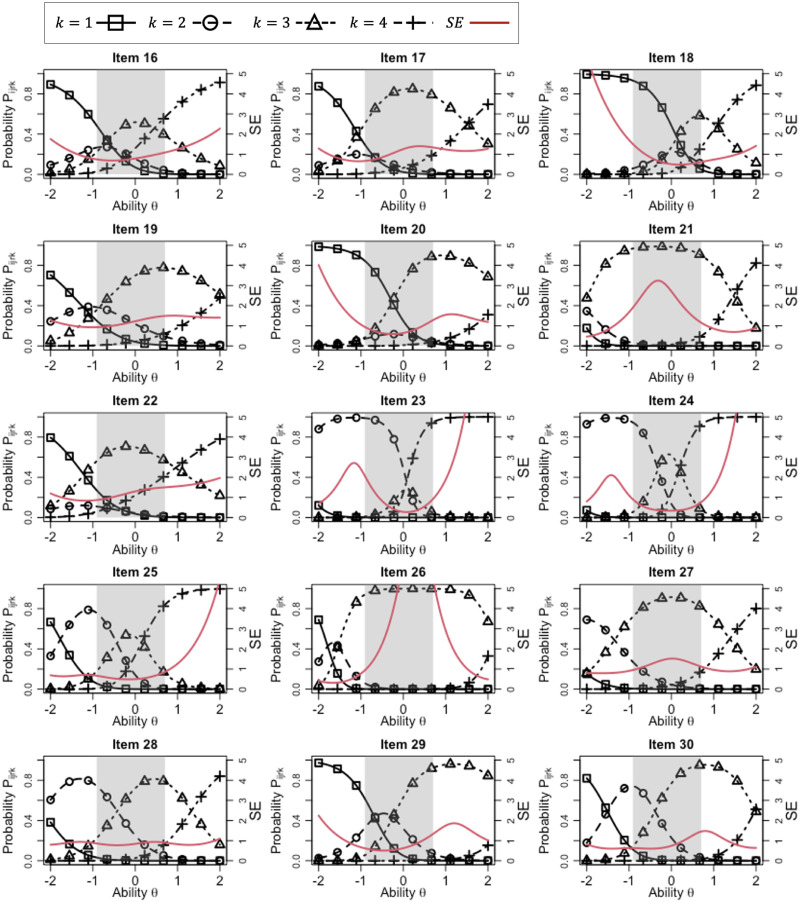
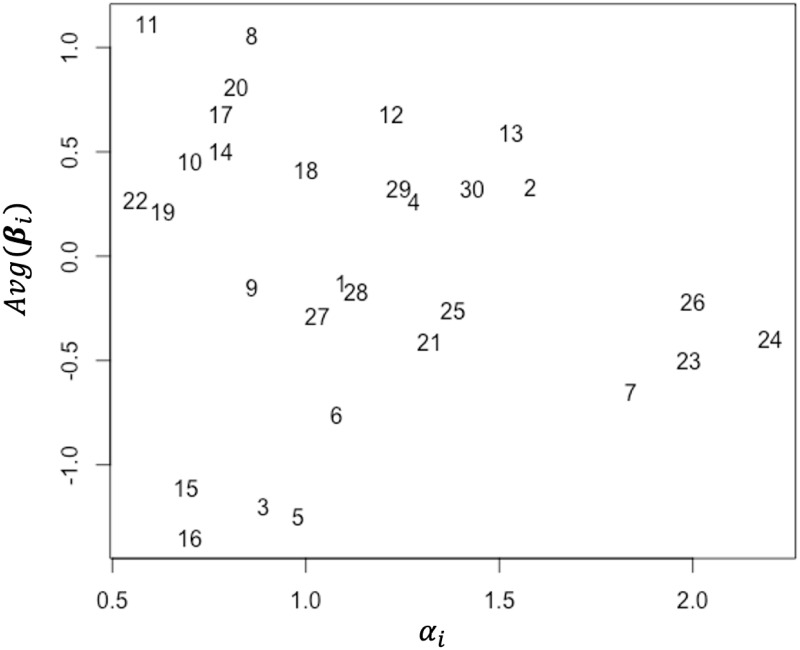
Objective structured clinical examinations (OSCEs) are a widely used performance assessment for medical and dental students. A common limitation of OSCEs is that the evaluation results depend on the characteristics of raters and a scoring rubric. To overcome this limitation, item response theory (IRT) models such as the many-facet Rasch model have been proposed to estimate examinee abilities while taking into account the characteristics of raters and evaluation items in a rubric. However, conventional IRT models have two impractical assumptions: constant rater severity across all evaluation items in a rubric and an equal interval rating scale among evaluation items, which can decrease model fitting and ability measurement accuracy. To resolve this problem, we propose a new IRT model that introduces two parameters: (1) a rater-item interaction parameter representing the rater severity for each evaluation item and (2) an item-specific step-difficulty parameter representing the difference in rating scales among evaluation items. We demonstrate the effectiveness of the proposed model by applying it to actual data collected from a medical interview test conducted at Tokyo Medical and Dental University as part of a post-clinical clerkship OSCE. The experimental results showed that the proposed model was well-fitted to our OSCE data and measured ability accurately. Furthermore, it provided abundant information on rater and item characteristics that conventional models cannot, helping us to better understand rater and item properties.
客观结构化临床考试(OSCE)是一种广泛用于医学生和牙科学员的绩效评估方法。OSCE 的一个常见局限性是,评估结果取决于评分者的特征和评分标准。为了克服这一局限性,已经提出了项目反应理论(IRT)模型,如多方面 Rasch 模型,以在考虑评分标准中评分者和评估项目的特征的情况下估计考生的能力。然而,传统的 IRT 模型有两个不切实际的假设:评分者在评分标准中的所有评估项目中的严格程度不变,以及评估项目之间的等距评分量表,这会降低模型拟合度和能力测量精度。为了解决这个问题,我们提出了一个新的 IRT 模型,该模型引入了两个参数:(1)代表每个评估项目的评分者-项目交互参数,以及(2)代表评估项目之间评分量表差异的项目特定步难度参数。我们通过将其应用于东京医科齿科大学在临床后实习 OSCE 中进行的医学面试测试中收集的实际数据来证明该模型的有效性。实验结果表明,该模型很好地适用于我们的 OSCE 数据,并且能够准确地测量能力。此外,它提供了有关评分者和项目特征的丰富信息,而传统模型无法提供这些信息,有助于我们更好地理解评分者和项目属性。