Chen Xiuying, Wang Tairan, Zhu Qingqing, Guo Taicheng, Gao Shen, Lu Zhiyong, Gao Xin, Zhang Xiangliang
King Abdullah University of Science & Technology.
National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, MD, USA.
ArXiv. 2024 Feb 22:arXiv:2402.14359v1.
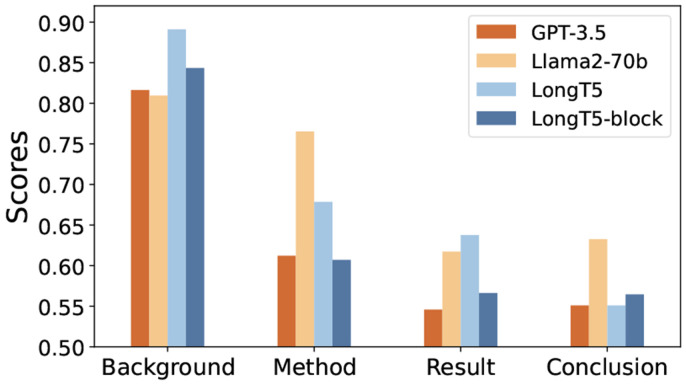
The summarization capabilities of pretrained and large language models (LLMs) have been widely validated in general areas, but their use in scientific corpus, which involves complex sentences and specialized knowledge, has been less assessed. This paper presents conceptual and experimental analyses of scientific summarization, highlighting the inadequacies of traditional evaluation methods, such as -gram, embedding comparison, and QA, particularly in providing explanations, grasping scientific concepts, or identifying key content. Subsequently, we introduce the Facet-aware Metric (FM), employing LLMs for advanced semantic matching to evaluate summaries based on different aspects. This facet-aware approach offers a thorough evaluation of abstracts by decomposing the evaluation task into simpler subtasks. Recognizing the absence of an evaluation benchmark in this domain, we curate a Facet-based scientific summarization Dataset (FD) with facet-level annotations. Our findings confirm that FM offers a more logical approach to evaluating scientific summaries. In addition, fine-tuned smaller models can compete with LLMs in scientific contexts, while LLMs have limitations in learning from in-context information in scientific domains. This suggests an area for future enhancement of LLMs.
预训练和大语言模型(LLMs)的总结能力在一般领域已得到广泛验证,但其在涉及复杂句子和专业知识的科学语料库中的应用评估较少。本文对科学总结进行了概念和实验分析,强调了传统评估方法(如 -gram、嵌入比较和问答)的不足之处,特别是在提供解释、理解科学概念或识别关键内容方面。随后,我们引入了方面感知度量(FM),利用大语言模型进行高级语义匹配,以基于不同方面评估总结。这种方面感知方法通过将评估任务分解为更简单的子任务,对摘要进行全面评估。鉴于该领域缺乏评估基准,我们精心策划了一个带有方面级注释的基于方面的科学总结数据集(FD)。我们的研究结果证实,FM为评估科学总结提供了一种更合理的方法。此外,经过微调的较小模型在科学背景下可以与大语言模型竞争,而大语言模型在从科学领域的上下文信息中学习方面存在局限性。这为大语言模型未来的改进指明了一个方向。