Ramirez-Diaz Ana M, Diaz-Zuluaga Ana M, Stroud Rocky E, Vreeker Annabel, Bitta Mary, Ivankovic Franjo, Wootton Olivia, Whiteman Cole A, Mountcastle Hayden, Jha Shaili C, Georgakopoulos Penelope, Kaur Ishpreet, Mena Laura, Asaaf Sandi, de Souza Rodrigues André Luiz, Ziebold Carolina, Newton Charles R J C, Stein Dan J, Akena Dickens, Valencia-Echeverry Johanna, Kyebuzibwa Joseph, Palacio-Ortiz Juan D, McMahon Justin, Ongeri Linnet, Chibnik Lori B, Quarantini Lucas C, Atwoli Lukoye, Santoro Marcos L, Baker Mark, Diniz Mateus J A, Castaño-Ramirez Mauricio, Alemayehu Melkam, Holanda Nayana, Ayola-Serrano Nohora C, Lorencetti Pedro G, Mwema Rehema M, James Roxanne, Albuquerque Saulo, Sharma Shivangi, Chapman Sinéad B, Belangero Sintia I, Teferra Solomon, Gichuru Stella, Service Susan K, Kariuki Symon M, Freitas Thiago H, Zingela Zukiswa, Gadelha Ary, Bearden Carrie E, Ophoff Roel A, Neale Benjamin M, Martin Alicia R, Koenen Karestan C, Pato Carlos N, Lopez-Jaramillo Carlos, Reus Victor, Freimer Nelson, Pato Michele T, Gelaye Bizu, Loohuis Loes Olde
Center for Neurobehavioral Genetics, Semel Institute for Neuroscience and Human Behavior, University of California Los Angeles, Los Angeles, USA.
Department of Epidemiology, Harvard T.H. Chan School of Public Health, Boston, USA.
medRxiv. 2024 Oct 4:2024.10.02.24314732. doi: 10.1101/2024.10.02.24314732.
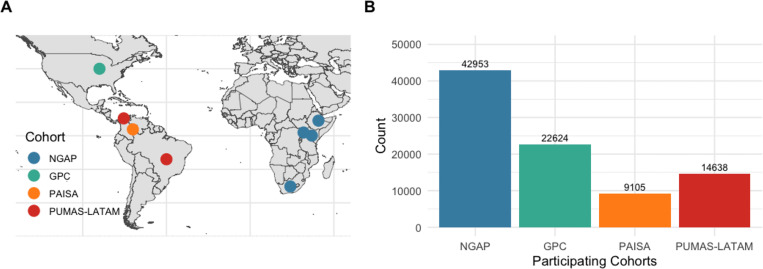
The Populations Underrepresented in Mental illness Association Studies (PUMAS) project is attempting to remediate the historical underrepresentation of African and Latin American populations in psychiatric genetics through large-scale genetic association studies of individuals diagnosed with a serious mental illness [SMI, including schizophrenia (SCZ), schizoaffective disorder (SZA) bipolar disorder (BP), and severe major depressive disorder (MDD)] and matched controls. Given growing evidence indicating substantial symptomatic and genetic overlap between these diagnoses, we sought to enable transdiagnostic genetic analyses of PUMAS data by conducting phenotype alignment and harmonization for 89,320 participants (48,165 cases and 41,155 controls) from four cohorts, each of which used different ascertainment and assessment methods: PAISA n=9,105; PUMAS-LATAM n=14,638; NGAP n=42,953 and GPC n=22,624. As we describe here, these efforts have yielded harmonized datasets enabling us to analyze PUMAS genetic variation data at three levels: SMI overall, diagnoses, and individual symptoms.
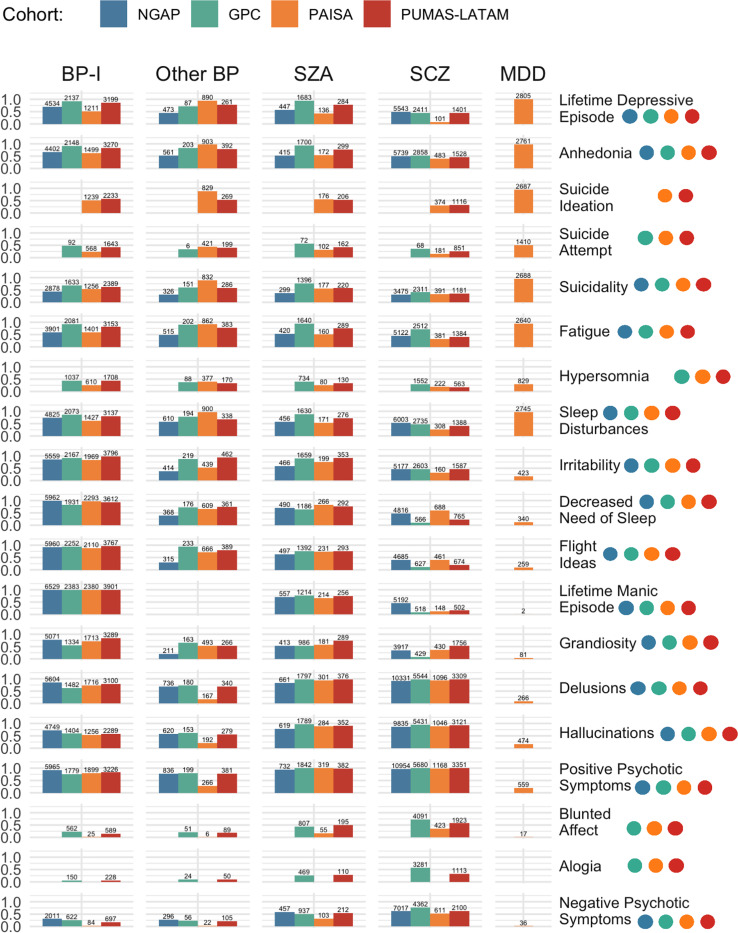
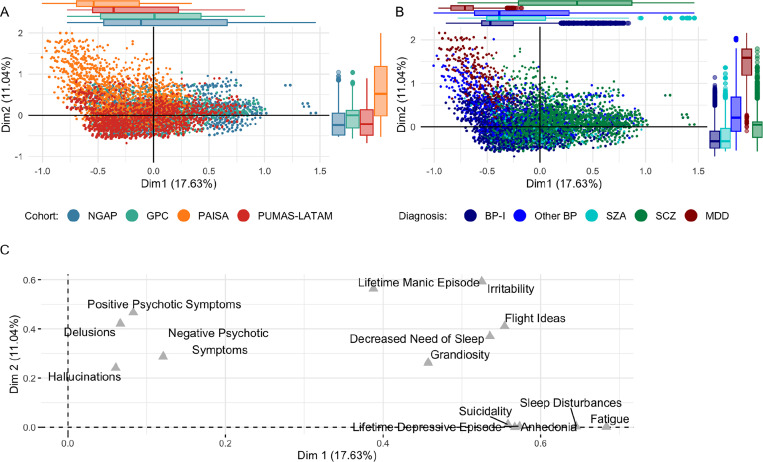
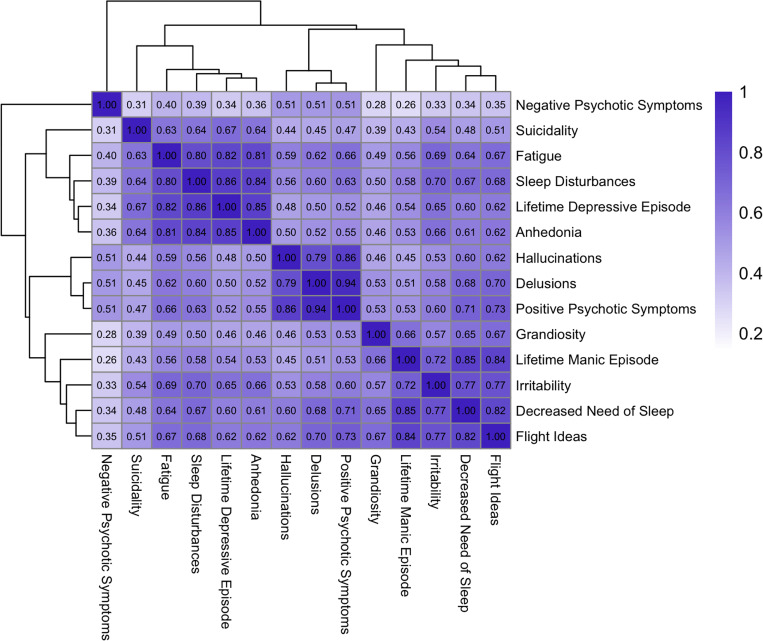
In aligning item-level phenotypes obtained from 14 different clinical instruments, we incorporated content, branching nature, and time frame for each phenotype; standardized diagnoses; and selected 19 core SMI item-level phenotypes for analyses. The harmonization was evaluated in PUMAS cases using multiple correspondence analysis (MCA), co-occurrence analyses, and item-level endorsement.
We mapped >6,895 item-level phenotypes in the aggregated PUMAS data, in which SCZ (44.97%) and severe BP (BP-I, 31.53%) were the most common diagnoses. Twelve of the 19 core item-level phenotypes occurred at frequencies of > 10% across all diagnoses, indicating their potential utility for transdiagnostic genetic analyses. MCA of the 14 phenotypes that were present for all cohorts revealed consistency across cohorts, and placed MDD and SCZ into separate clusters, while other diagnoses showed no significant phenotypic clustering.
Our alignment strategy effectively aggregated extensive phenotypic data obtained using diverse assessment tools. The MCA yielded dimensional scores which we will use for genetic analyses along with the item level phenotypes. After successful harmonization, residual phenotypic heterogeneity between cohorts reflects differences in branching structure of diagnostic instruments, recruitment strategies, and symptom interpretation (due to cultural variation).
精神疾病协会研究中代表性不足人群(PUMAS)项目正试图通过对被诊断患有严重精神疾病[SMI,包括精神分裂症(SCZ)、分裂情感性障碍(SZA)、双相情感障碍(BP)和重度重度抑郁症(MDD)]的个体以及匹配的对照组进行大规模基因关联研究,来纠正非洲和拉丁美洲人群在精神遗传学研究中长期以来代表性不足的问题。鉴于越来越多的证据表明这些诊断之间存在大量症状和基因重叠,我们试图通过对来自四个队列的89320名参与者(48165例患者和41155名对照)进行表型比对和协调,来实现对PUMAS数据的跨诊断基因分析,每个队列都使用了不同的确定和评估方法:PAISA(n = 9105);PUMAS - LATAM(n = 14638);NGAP(n = 42953)和GPC(n = 22624)。正如我们在此所描述的,这些努力已经产生了协调一致的数据集,使我们能够在三个层面分析PUMAS基因变异数据:总体SMI、诊断和个体症状。
在比对从14种不同临床工具获得的项目层面表型时,我们纳入了每种表型的内容、分支性质和时间框架;标准化诊断;并选择了19个核心SMI项目层面表型进行分析。使用多重对应分析(MCA)、共现分析和项目层面认可对PUMAS病例中的协调情况进行评估。
我们在汇总的PUMAS数据中绘制了>6895个项目层面表型,其中SCZ(44.97%)和重度BP(BP - I,31.53%)是最常见的诊断。19个核心项目层面表型中有12个在所有诊断中的出现频率>10%,表明它们在跨诊断基因分析中的潜在效用。对所有队列都存在的14种表型进行的MCA显示各队列之间具有一致性,并将MDD和SCZ分为不同的聚类,而其他诊断未显示出明显的表型聚类。
我们的比对策略有效地汇总了使用多种评估工具获得的广泛表型数据。MCA产生了维度分数,我们将把这些分数与项目层面表型一起用于基因分析。成功协调后,各队列之间残留的表型异质性反映了诊断工具的分支结构、招募策略和症状解释(由于文化差异)方面的差异。