Wang Xinhao, Ye Shisheng, Feng Jinwen, Feng Kaiyan, Yang Heng, Li Hao
Department of Neurology, Maoming People's Hospital, Maoming, Guangdong, China.
Digit Health. 2024 Nov 5;10:20552076241297127. doi: 10.1177/20552076241297127. eCollection 2024 Jan-Dec.
The management of acute ischemic stroke (AIS) is time-sensitive, yet prehospital delays remain prevalent. The application of large language models (LLMs) for medical text analysis may play a potential role in clinical decision support. We assess the performance of LLMs on prehospital AIS and large vessel occlusion (LVO) stroke screening.
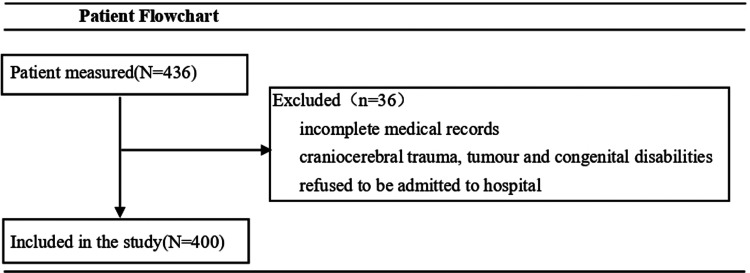
This retrospective study sourced cases from the electronic medical record database of the emergency department (ED) at Maoming People's Hospital, encompassing patients who presented to the ED between June and November 2023. We evaluate the diagnostic accuracy of GPT-3.5 and GPT-4 for the detection of AIS and LVO stroke by comparing the sensitivity, specificity, accuracy, positive predictive value, negative predictive value, and positive likelihood ratio and AUC of both LLMs. The neurological reasoning of LLMs was rated on a five-point Likert scale for factual correctness and the occurrence of errors.
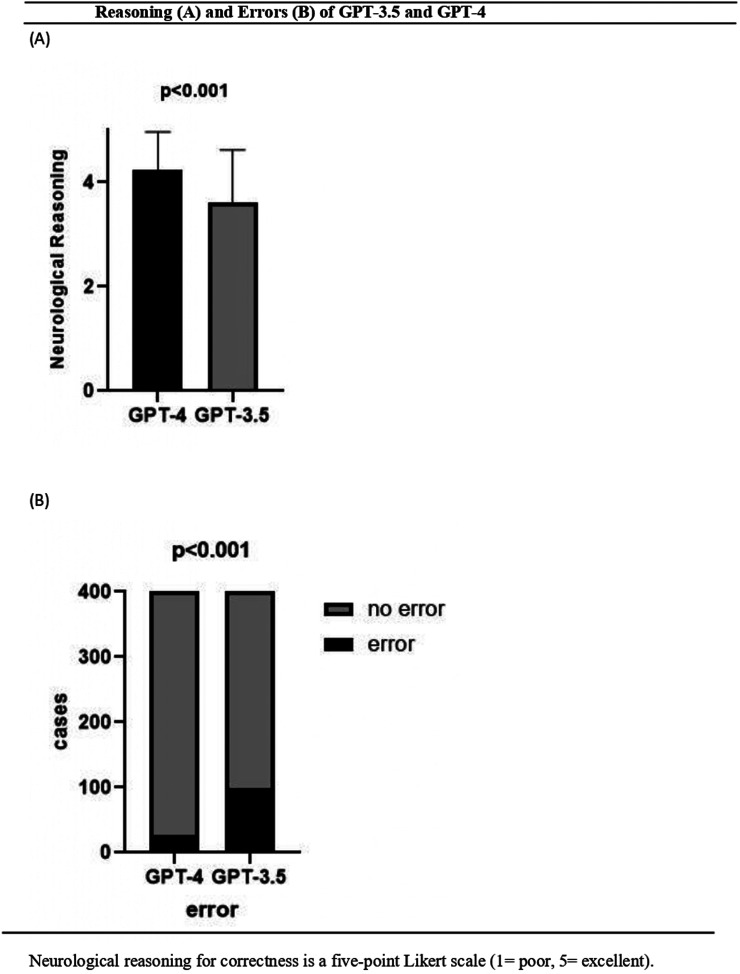
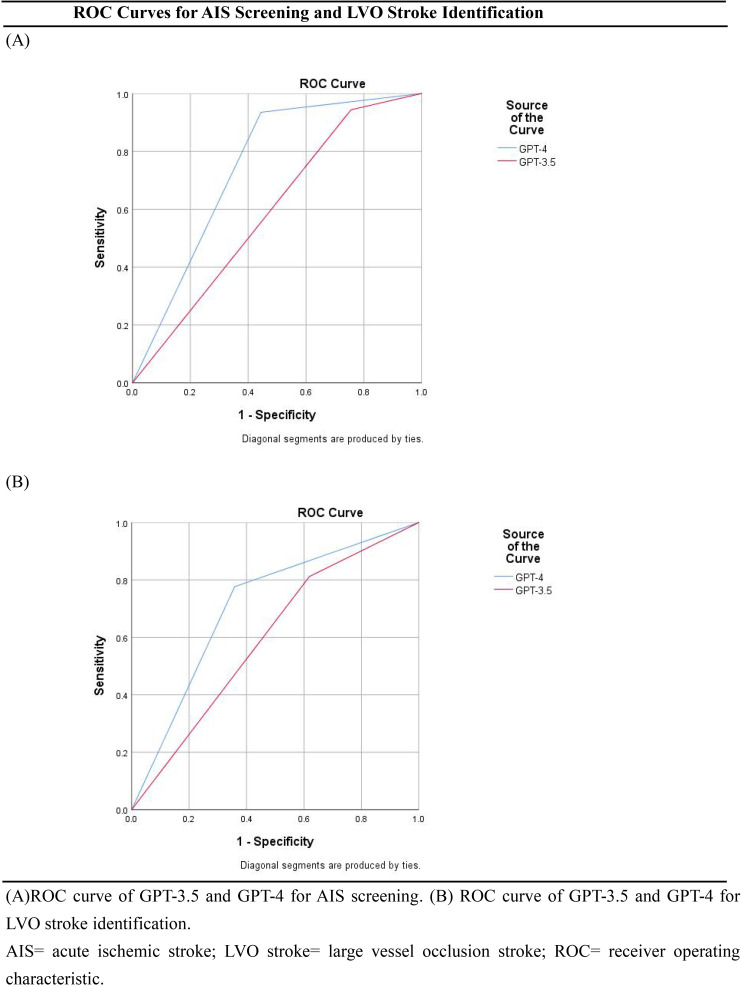
On 400 records from 400 patients (mean age, 70.0 years ± 12.5 [SD]; 273 male), GPT-4 outperformed GPT-3.5 in AIS screening (AUC 0.75 (0.65-0.84) vs 0.59 (0.50-0.69), P = 0.015) and LVO identification (AUC 0.71 (0.65-0.77) vs 0.60 (0.53-0.66), P < 0.001). GPT-4 achieved higher accuracy than GPT-3.5 in screening of AIS (89.3% [95% CI: 85.8, 91.9] vs 86.5% [95% CI: 82.8, 89.5]) and LVO stroke identification (67.0% [95% CI: 62.3%, 71.4%] vs 47.3% [95% CI: 42.4%, 52.2%]). In neurological reasoning, GPT-4 had higher Likert scale scores for factual correctness (4.24 vs 3.62), with a lower rate of error (6.8% vs 24.8%) than GPT-3.5 (all P < 0.001).
The result demonstrates that LLMs possess diagnostic capability in the prehospital identification of ischemic stroke, with the ability to exhibit neurologically informed reasoning processes. Notably, GPT-4 outperforms GPT-3.5 in the recognition of AIS and LVO stroke, achieving results comparable to prehospital scales. LLMs are supposed to become a promising supportive decision-making tool for EMS practitioners in screening prehospital stroke.
急性缺血性卒中(AIS)的治疗对时间敏感,但院前延误仍然普遍存在。大语言模型(LLMs)在医学文本分析中的应用可能在临床决策支持中发挥潜在作用。我们评估了大语言模型在院前AIS和大血管闭塞(LVO)性卒中筛查中的性能。
这项回顾性研究从茂名市人民医院急诊科的电子病历数据库中提取病例,涵盖2023年6月至11月期间到急诊科就诊的患者。我们通过比较GPT-3.5和GPT-4检测AIS和LVO性卒中的敏感性、特异性、准确性、阳性预测值、阴性预测值、阳性似然比和AUC,评估它们的诊断准确性。大语言模型的神经推理能力根据事实正确性和错误发生率在五点李克特量表上进行评分。
在400例患者的400份记录中(平均年龄70.0岁±12.5[标准差];男性273例),GPT-4在AIS筛查(AUC 0.75[0.65 - 0.84] vs 0.59[0.50 - 0.69],P = 0.015)和LVO识别(AUC 0.71[0.65 - 0.77] vs 0.60[0.53 - 0.66],P < 0.001)方面优于GPT-3.5。GPT-4在AIS筛查(89.3%[95%置信区间:85.8,91.9] vs 86.5%[95%置信区间:82.8,89.5])和LVO性卒中识别(67.0%[95%置信区间:62.3%,71.4%] vs 47.3%[95%置信区间:42.4%,52.2%])方面比GPT-3.5具有更高的准确性。在神经推理方面,GPT-4在事实正确性方面的李克特量表得分更高(4.24 vs 3.62),错误率低于GPT-3.5(6.8% vs 24.8%)(所有P < 0.001)。
结果表明,大语言模型在院前缺血性卒中识别中具有诊断能力,能够展现基于神经学的推理过程。值得注意的是,GPT-4在识别AIS和LVO性卒中方面优于GPT-3.5,其结果与院前量表相当。大语言模型有望成为急救医疗服务人员筛查院前卒中的一种有前景的辅助决策工具。