Department of Bioinformatics and Systems Biology, MOE Key Laboratory of Molecular Biophysics, Hubei Bioinformatics and Molecular Imaging Key Laboratory, College of Life Science and Technology, Huazhong University of Science and Technology, Wuhan 430074, China.
School of Artificial Intelligence and Automation, Huazhong University of Science and Technology, Wuhan 430074, China.
Cells. 2024 Nov 8;13(22):1854. doi: 10.3390/cells13221854.
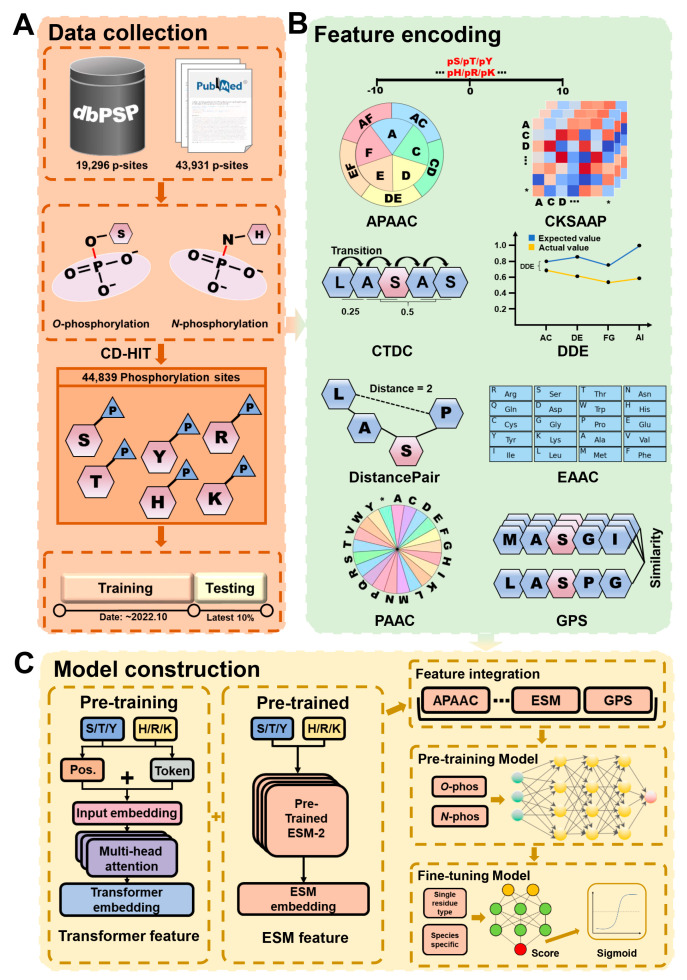
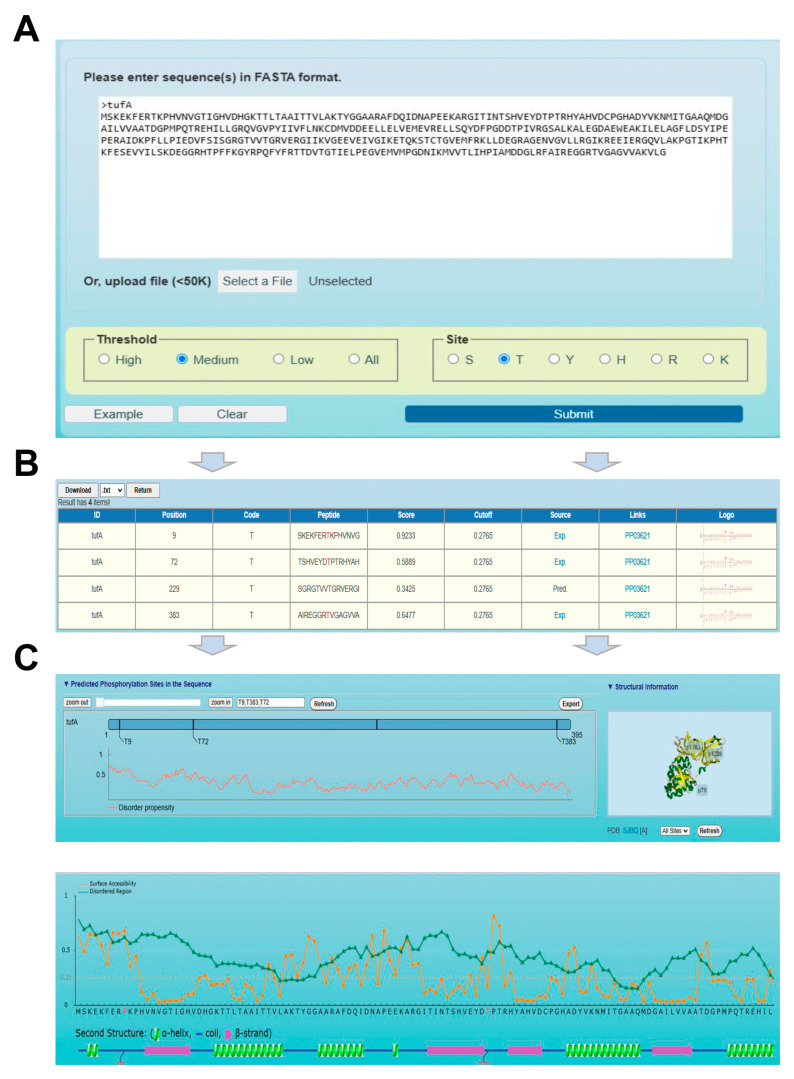
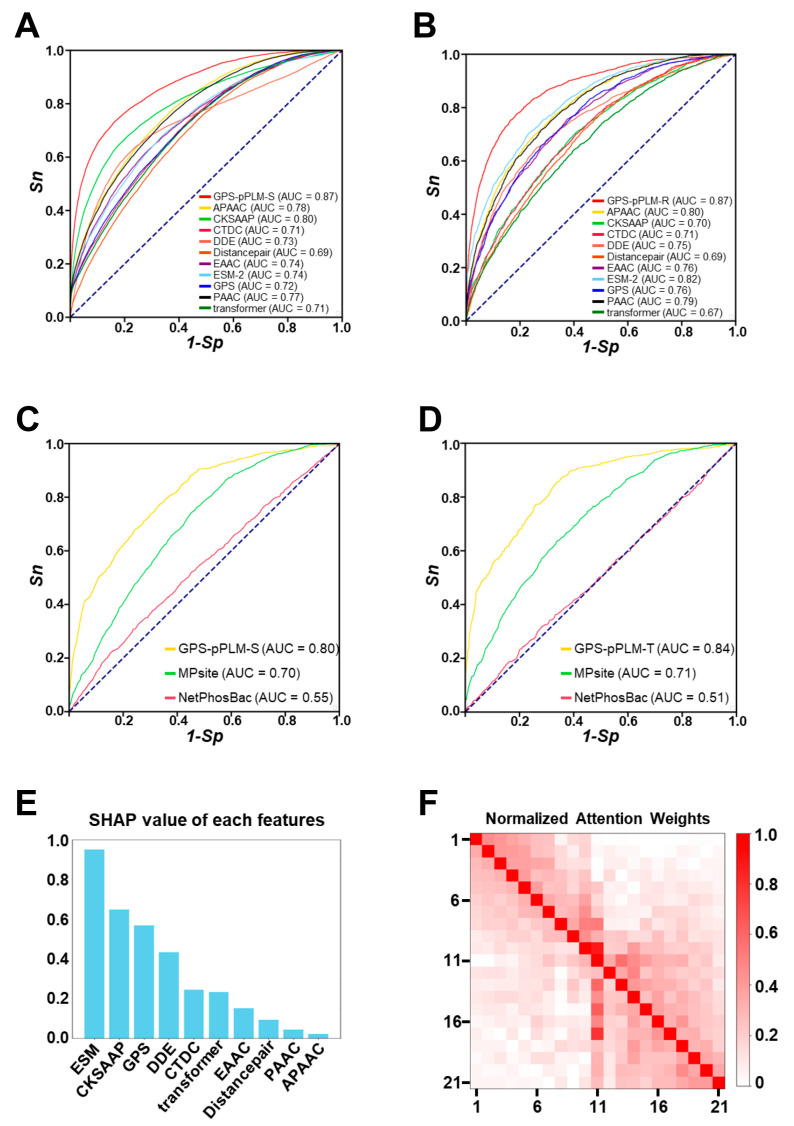
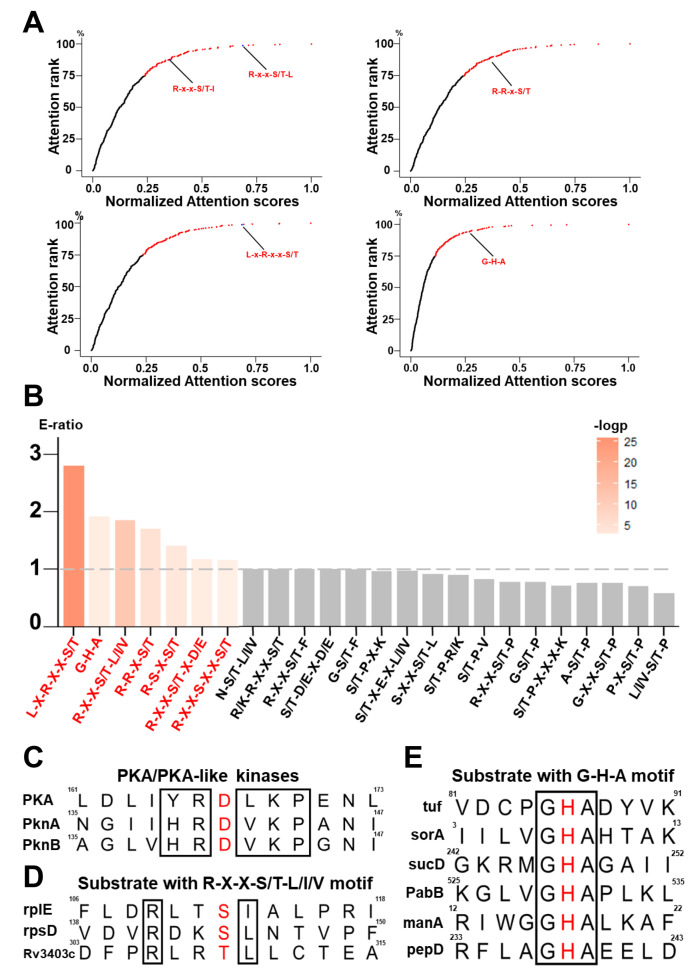
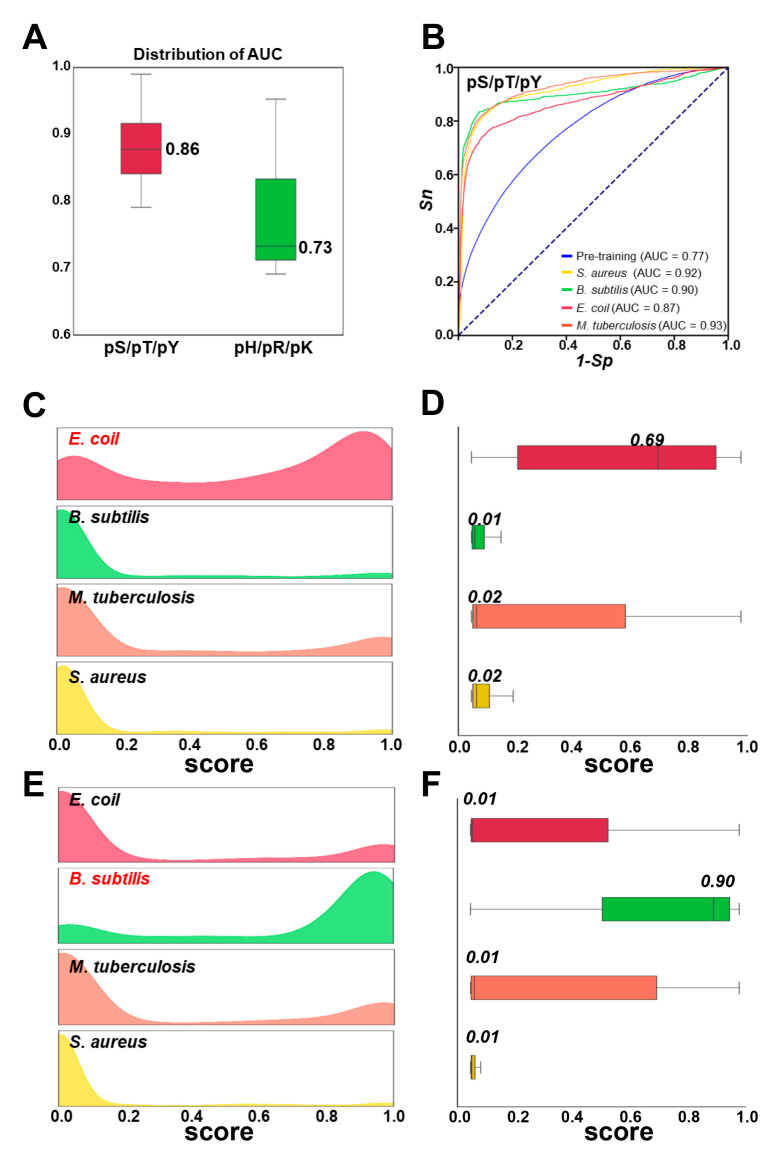
In the prokaryotic kingdom, protein phosphorylation serves as one of the most important posttranslational modifications (PTMs) and is involved in orchestrating a broad spectrum of biological processes. Here, we report an updated online server named the group-based prediction system for prokaryotic phosphorylation language model (GPS-pPLM), used for predicting phosphorylation sites (p-sites) in prokaryotes. For model training, two deep learning methods, a transformer and a deep neural network, were employed, and a total of 10 sequence features and contextual features were integrated. Using 44,839 nonredundant p-sites in 16,041 proteins from 95 prokaryotes, two general models for the prediction of -phosphorylation and -phosphorylation were first pretrained and then fine-tuned to construct 6 predictors specific for each phosphorylatable residue type as well as 134 species-specific predictors. Compared with other existing tools, the GPS-pPLM exhibits higher accuracy in predicting prokaryotic -phosphorylation p-sites. Protein sequences in FASTA format or UniProt accession numbers can be submitted by users, and the predicted results are displayed in tabular form. In addition, we annotate the predicted p-sites with knowledge from 22 public resources, including experimental evidence, 3D structures, and disorder tendencies. The online service of the GPS-pPLM is freely accessible for academic research.
在原核生物王国中,蛋白质磷酸化是最重要的翻译后修饰(PTMs)之一,参与调控广泛的生物过程。在这里,我们报告了一个名为基于组预测系统的原核磷酸化语言模型(GPS-pPLM)的更新在线服务器,用于预测原核生物中的磷酸化位点(p-sites)。在模型训练中,我们使用了两种深度学习方法,即转换器和深度神经网络,并整合了总共 10 种序列特征和上下文特征。使用来自 95 种原核生物的 16041 种蛋白质中的 44839 个非冗余 p-sites,我们首先对用于预测 -磷酸化和 -磷酸化的两个通用模型进行预训练,然后进行微调,以构建 6 个针对每个可磷酸化残基类型的预测器以及 134 个物种特异性预测器。与其他现有工具相比,GPS-pPLM 在预测原核 -磷酸化 p-sites 方面具有更高的准确性。用户可以提交 FASTA 格式的蛋白质序列或 UniProt 访问号,预测结果以表格形式显示。此外,我们还使用来自 22 个公共资源的知识注释预测的 p-sites,包括实验证据、3D 结构和无序趋势。GPS-pPLM 的在线服务可供学术研究免费使用。