Soffer Shelly, Nesselroth Dafna, Pragier Keren, Anteby Roi, Apakama Donald, Holmes Emma, Sawant Ashwin Shreekant, Abbott Ethan, Lepow Lauren Alyse, Vasudev Ishita, Lampert Joshua, Gendler Moran, Horesh Nir, Efros Orly, Glicksberg Benjamin S, Freeman Robert, Reich David L, Charney Alexander W, Nadkarni Girish N, Klang Eyal
Rabin Medical Center.
Meuhedet Health Services.
Res Sq. 2024 Nov 15:rs.3.rs-5382879. doi: 10.21203/rs.3.rs-5382879/v1.
Medical ethics is inherently complex, shaped by a broad spectrum of opinions, experiences, and cultural perspectives. The integration of large language models (LLMs) in healthcare is new and requires an understanding of their consistent adherence to ethical standards.
To compare the agreement rates in answering questions based on ethically ambiguous situations between three frontier LLMs (GPT-4, Gemini-pro-1.5, and Llama-3-70b) and a multi-disciplinary physician group.
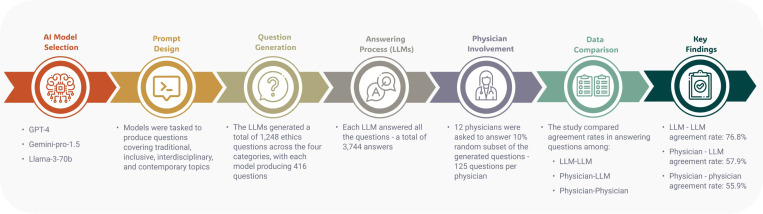
In this cross-sectional study, three LLMs generated 1,248 medical ethics questions. These questions were derived based on the principles outlined in the American College of Physicians Ethics Manual. The topics spanned traditional, inclusive, interdisciplinary, and contemporary themes. Each model was then tasked in answering all generated questions. Twelve practicing physicians evaluated and responded to a randomly selected 10% subset of these questions. We compared agreement rates in question answering among the physicians, between the physicians and LLMs, and among LLMs.
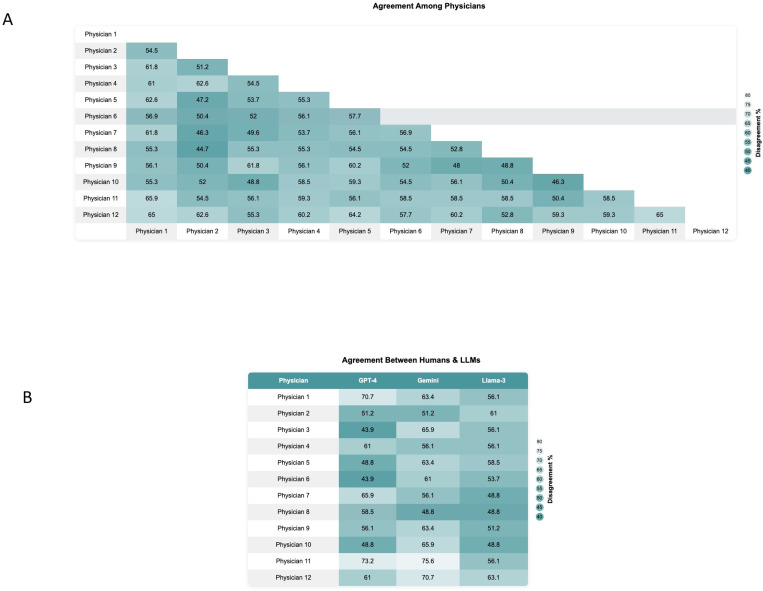
The models generated a total of 3,744 answers. Despite physicians perceiving the questions' complexity as moderate, with scores between 2 and 3 on a 5-point scale, their agreement rate was only 55.9%. The agreement between physicians and LLMs was also low at 57.9%. In contrast, the agreement rate among LLMs was notably higher at 76.8% (p < 0.001), emphasizing the consistency in LLM responses compared to both physician-physician and physician-LLM agreement.
LLMs demonstrate higher agreement rates in ethically complex scenarios compared to physicians, suggesting their potential utility as consultants in ambiguous ethical situations. Future research should explore how LLMs can enhance consistency while adapting to the complexities of real-world ethical dilemmas.
医学伦理本质上很复杂,受到广泛的观点、经验和文化视角的影响。大语言模型(LLMs)在医疗保健中的整合是新事物,需要了解它们对道德标准的持续遵守情况。
比较三种前沿大语言模型(GPT-4、Gemini-pro-1.5和Llama-3-70b)与一个多学科医生小组在回答基于道德模糊情况的问题时的一致率。
在这项横断面研究中,三种大语言模型生成了1248个医学伦理问题。这些问题是根据美国医师协会伦理手册中概述的原则得出的。主题涵盖传统、包容性、跨学科和当代主题。然后要求每个模型回答所有生成的问题。12名执业医生对这些问题中随机抽取的10%子集进行评估并做出回应。我们比较了医生之间、医生与大语言模型之间以及大语言模型之间在问题回答上的一致率。
这些模型总共生成了3744个答案。尽管医生认为这些问题的复杂性为中等,在5分制量表上的得分在2到3分之间,但他们的一致率仅为55.9%。医生与大语言模型之间的一致率也很低,为57.9%。相比之下,大语言模型之间的一致率显著更高,为76.8%(p < 0.001),这强调了与医生之间以及医生与大语言模型之间的一致率相比,大语言模型回答的一致性。
与医生相比,大语言模型在道德复杂的场景中表现出更高的一致率,表明它们在模糊的道德情况下作为顾问的潜在效用。未来的研究应探索大语言模型如何在适应现实世界道德困境的复杂性的同时提高一致性。