Mswahili Medard Edmund, Jeong Young-Seob
Chungbuk National University, Department of Computer Engineering, Cheongju, 28644, South Korea.
Heliyon. 2024 Oct 9;10(20):e39038. doi: 10.1016/j.heliyon.2024.e39038. eCollection 2024 Oct 30.
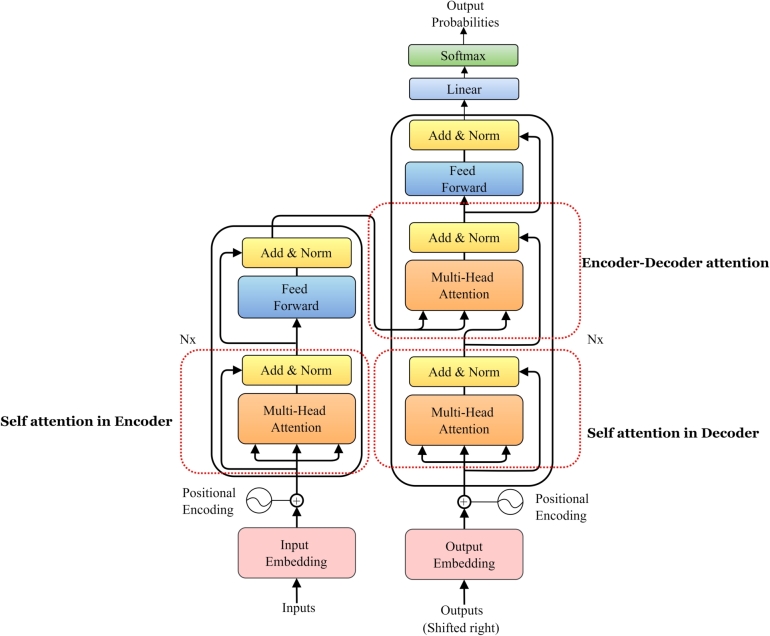
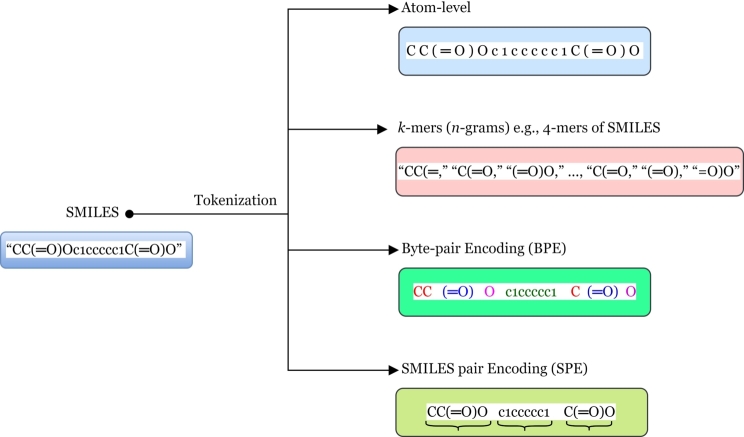
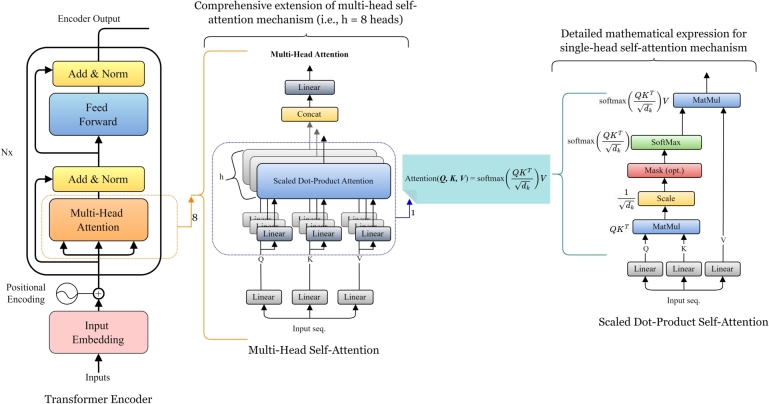
Pre-trained chemical language models (CLMs) have attracted increasing attention within the domains of cheminformatics and bioinformatics, inspired by their remarkable success in the natural language processing (NLP) domain such as speech recognition, text analysis, translation, and other objectives associated with language. Furthermore, the vast amount of unlabeled data associated with chemical compounds or molecules has emerged as a crucial research focus, prompting the need for CLMs with reasoning capabilities over such data. Molecular graphs and molecular descriptors are the predominant approaches to representing molecules for property prediction in machine learning (ML). However, Transformer-based LMs have recently emerged as de-facto powerful tools in deep learning (DL), showcasing outstanding performance across various NLP downstream tasks, particularly in text analysis. Within the realm of pre-trained transformer-based LMs such as, BERT (and its variants) and GPT (and its variants) have been extensively explored in the chemical informatics domain. Various learning tasks in cheminformatics such as the text analysis that necessitate handling of chemical SMILES data which contains intricate relations among elements or atoms, have become increasingly prevalent. Whether the objective is predicting molecular reactions or molecular property prediction, there is a growing demand for LMs capable of learning molecular contextual information within SMILES sequences or strings from text inputs (i.e., SMILES). This review provides an overview of the current state-of-the-art of chemical language Transformer-based LMs in chemical informatics for de novo design, and analyses current limitations, challenges, and advantages. Finally, a perspective on future opportunities is provided in this evolving field.
预训练化学语言模型(CLMs)在化学信息学和生物信息学领域受到了越来越多的关注,这得益于它们在自然语言处理(NLP)领域(如语音识别、文本分析、翻译以及与语言相关的其他目标)取得的显著成功。此外,与化合物或分子相关的大量未标记数据已成为关键的研究重点,这促使人们需要具有对这些数据进行推理能力的CLMs。分子图和分子描述符是机器学习(ML)中用于表示分子以进行性质预测的主要方法。然而,基于Transformer的语言模型(LMs)最近已成为深度学习(DL)中事实上的强大工具,在各种NLP下游任务中展现出卓越性能,尤其是在文本分析方面。在诸如BERT(及其变体)和GPT(及其变体)等基于Transformer的预训练LMs领域,已经在化学信息学领域进行了广泛探索。化学信息学中的各种学习任务,如需要处理包含元素或原子之间复杂关系的化学SMILES数据的文本分析,变得越来越普遍。无论目标是预测分子反应还是分子性质预测,对能够从文本输入(即SMILES)的SMILES序列或字符串中学习分子上下文信息的LMs的需求都在不断增长。本综述概述了基于化学语言Transformer的LMs在化学信息学中用于从头设计的当前技术水平,并分析了当前的局限性、挑战和优势。最后,对这个不断发展的领域的未来机会提供了一个展望。