Nazir Shahzad, Asif Muhammad, Rehman Mariam, Ahmad Shahbaz
Department of Computer Science, National Textile University, Faisalabad, Pakistan.
Department of Information Technology, Government College University, Faisalabad, Faisalabad, Pakistan.
PeerJ Comput Sci. 2024 Jan 31;10:e1704. doi: 10.7717/peerj-cs.1704. eCollection 2024.
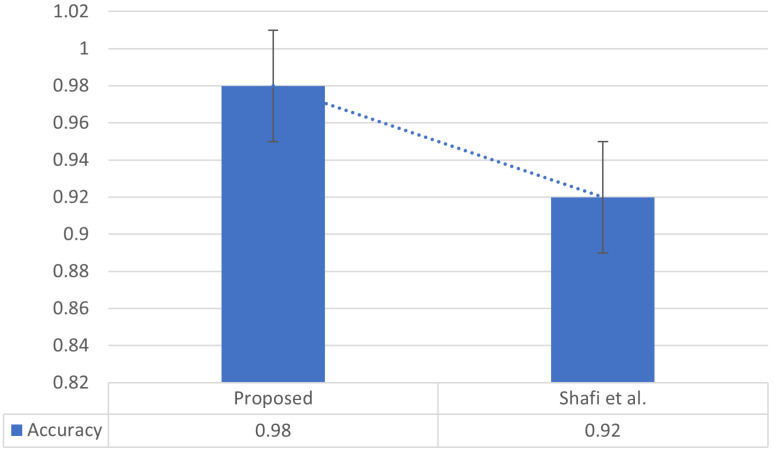
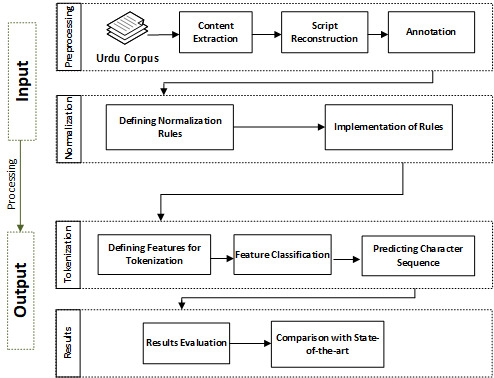
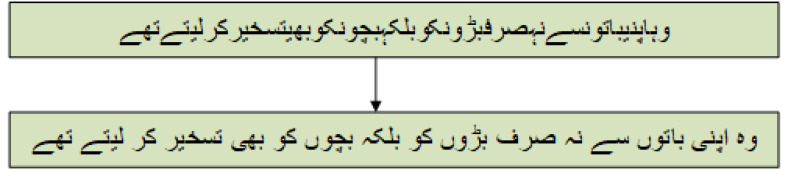
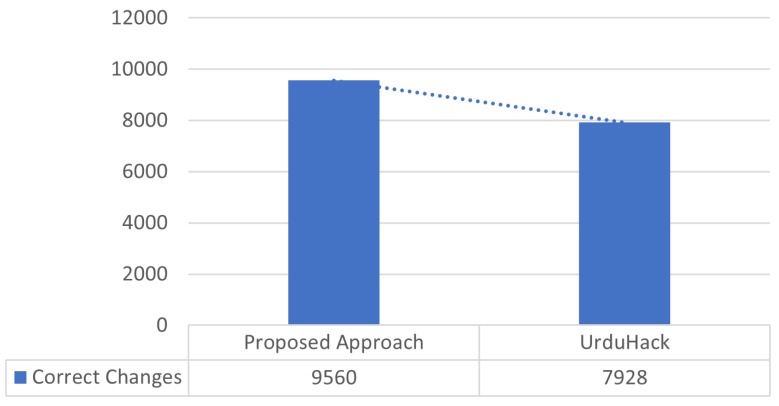
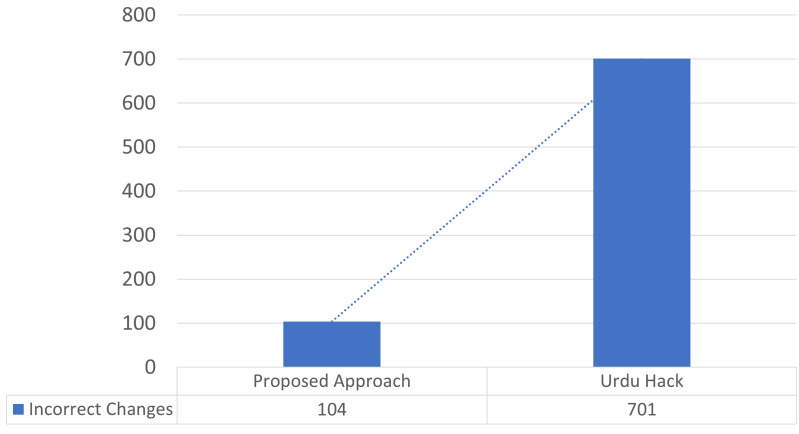
In text applications, pre-processing is deemed as a significant parameter to enhance the outcomes of natural language processing (NLP) chores. Text normalization and tokenization are two pivotal procedures of text pre-processing that cannot be overstated. Text normalization refers to transforming raw text into scriptural standardized text, while word tokenization splits the text into tokens or words. Well defined normalization and tokenization approaches exist for most spoken languages in world. However, the world's 10th most widely spoken language has been overlooked by the research community. This research presents improved text normalization and tokenization techniques for the Urdu language. For Urdu text normalization, multiple regular expressions and rules are proposed, including removing diuretics, normalizing single characters, separating digits, . While for word tokenization, core features are defined and extracted against each character of text. Machine learning model is considered with specified handcrafted rules to predict the space and to tokenize the text. This experiment is performed, while creating the largest human-annotated dataset composed in Urdu script covering five different domains. The results have been evaluated using precision, recall, F-measure, and accuracy. Further, the results are compared with state-of-the-art. The normalization approach produced 20% and tokenization approach achieved 6% improvement.
在文本应用中,预处理被视为提升自然语言处理(NLP)任务结果的一个重要参数。文本规范化和词元化是文本预处理的两个关键步骤,其重要性再怎么强调也不为过。文本规范化是指将原始文本转换为符合书写规范的标准化文本,而词元化则是将文本拆分为词元或单词。对于世界上大多数口语语言,都存在定义明确的规范化和词元化方法。然而,世界上第十大使用最广泛的语言却被研究界忽视了。本研究提出了改进的乌尔都语文本规范化和词元化技术。对于乌尔都语文本规范化,提出了多个正则表达式和规则,包括去除利尿剂、规范化单个字符、分隔数字等。而对于词元化,针对文本的每个字符定义并提取核心特征。考虑使用具有特定手工制作规则的机器学习模型来预测空格并对文本进行词元化。在创建由乌尔都语脚本编写的涵盖五个不同领域的最大人工标注数据集的同时进行了该实验。使用精确率、召回率、F1值和准确率对结果进行了评估。此外,还将结果与现有最佳技术进行了比较。规范化方法产生了20%的提升,词元化方法实现了6%的提升。