Graduate Institute of Biomedical Informatics, College of Medical Science and Technology, Taipei Medical University, Taipei, Taiwan.
Institute of Information Science, Academia Sinica, Taipei, Taiwan.
J Cheminform. 2015 Jan 19;7(Suppl 1 Text mining for chemistry and the CHEMDNER track):S14. doi: 10.1186/1758-2946-7-S1-S14. eCollection 2015.
The functions of chemical compounds and drugs that affect biological processes and their particular effect on the onset and treatment of diseases have attracted increasing interest with the advancement of research in the life sciences. To extract knowledge from the extensive literatures on such compounds and drugs, the organizers of BioCreative IV administered the CHEMical Compound and Drug Named Entity Recognition (CHEMDNER) task to establish a standard dataset for evaluating state-of-the-art chemical entity recognition methods.
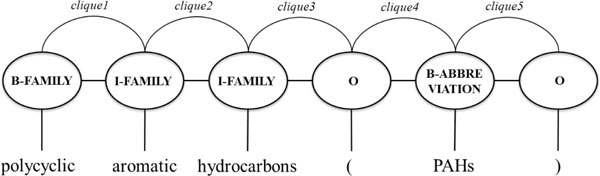
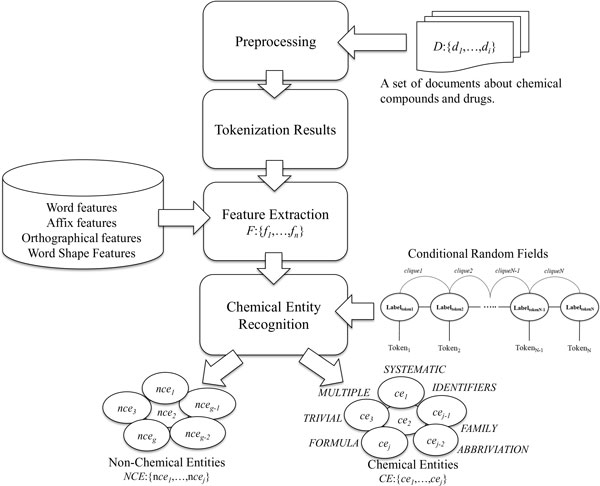
This study introduces the approach of our CHEMDNER system. Instead of emphasizing the development of novel feature sets for machine learning, this study investigates the effect of various tag schemes on the recognition of the names of chemicals and drugs by using conditional random fields. Experiments were conducted using combinations of different tokenization strategies and tag schemes to investigate the effects of tag set selection and tokenization method on the CHEMDNER task.
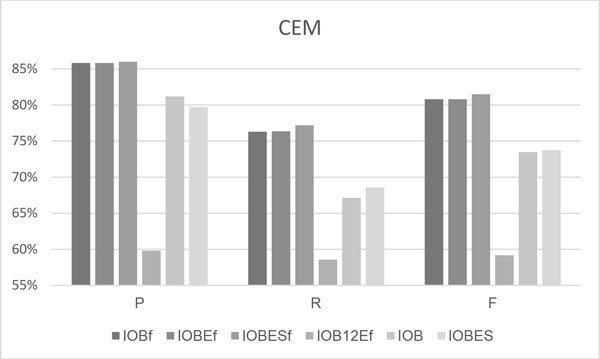
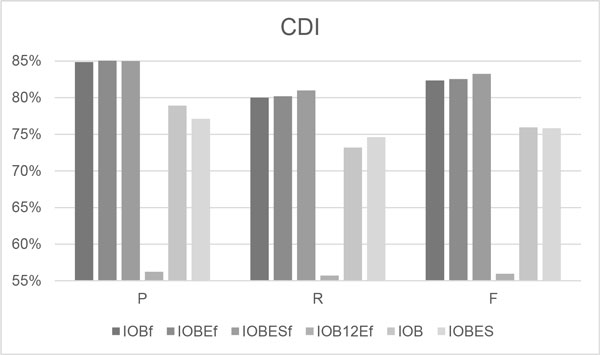
This study presents the performance of CHEMDNER of three more representative tag schemes-IOBE, IOBES, and IOB12E-when applied to a widely utilized IOB tag set and combined with the coarse-/fine-grained tokenization methods. The experimental results thus reveal that the fine-grained tokenization strategy performance best in terms of precision, recall and F-scores when the IOBES tag set was utilized. The IOBES model with fine-grained tokenization yielded the best-F-scores in the six chemical entity categories other than the "Multiple" entity category. Nonetheless, no significant improvement was observed when a more representative tag schemes was used with the coarse or fine-grained tokenization rules. The best F-scores that were achieved using the developed system on the test dataset of the CHEMDNER task were 0.833 and 0.815 for the chemical documents indexing and the chemical entity mention recognition tasks, respectively.
The results herein highlight the importance of tag set selection and the use of different tokenization strategies. Fine-grained tokenization combined with the tag set IOBES most effectively recognizes chemical and drug names. To the best of the authors' knowledge, this investigation is the first comprehensive investigation use of various tag set schemes combined with different tokenization strategies for the recognition of chemical entities.
随着生命科学研究的进展,影响生物过程的化合物和药物的功能及其对疾病的发生和治疗的特殊作用引起了越来越多的关注。为了从广泛的化合物和药物文献中提取知识,BioCreative IV 的组织者开展了 CHEMical Compound and Drug Named Entity Recognition(CHEMDNER)任务,以建立一个用于评估最先进的化学实体识别方法的标准数据集。
本研究介绍了我们的 CHEMDNER 系统的方法。本研究不是强调为机器学习开发新的特征集,而是调查了各种标记方案对使用条件随机场识别化学物质和药物名称的影响。实验使用不同的标记策略和标记方案组合进行,以研究标记集选择和标记方法对 CHEMDNER 任务的影响。
本研究提出了在广泛使用的 IOB 标记集上应用三种更具代表性的标记方案(IOBE、IOBES 和 IOB12E)时的 CHEMDNER 性能,并结合了粗粒度/细粒度标记方法。实验结果表明,在使用 IOBES 标记集时,细粒度标记策略在精度、召回率和 F 分数方面表现最佳。在“Multiple”实体类别之外的其他六个化学实体类别中,具有细粒度标记的 IOBES 模型获得了最佳的 F 分数。然而,当使用更具代表性的标记方案和粗粒度或细粒度标记规则时,并没有观察到显著的改进。在 CHEMDNER 任务的测试数据集上,开发系统获得的最佳 F 分数分别为化学文献索引任务的 0.833 和化学实体提及识别任务的 0.815。
结果强调了标记集选择和使用不同标记策略的重要性。细粒度标记与 IOBES 标记集相结合,最有效地识别化学物质和药物名称。据作者所知,这是首次使用各种标记集方案与不同的标记策略相结合进行化学实体识别的全面调查。