Ren Ziliang, Xiao Xiongjiang, Nie Huabei
School of Computer Science and Technology, Dongguan University of Technology, Dongguan 523820, China.
School of Artificial Intelligence, Dongguan City University, Dongguan 523419, China.
Sensors (Basel). 2024 Nov 30;24(23):7682. doi: 10.3390/s24237682.
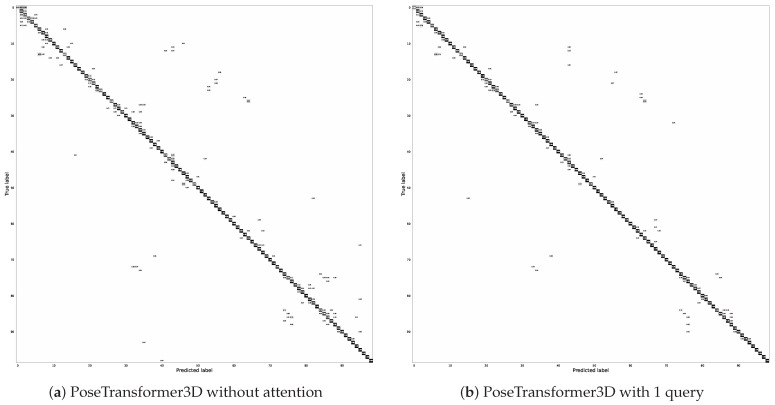
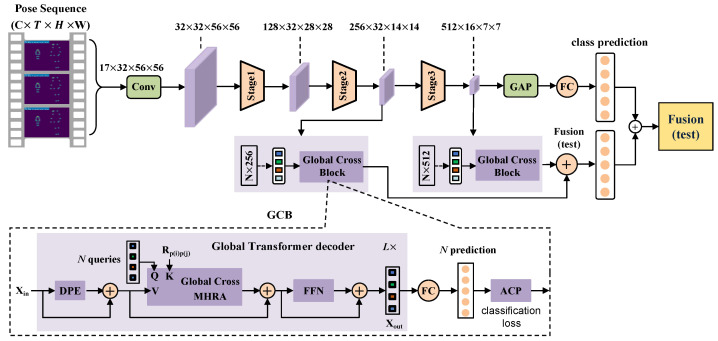
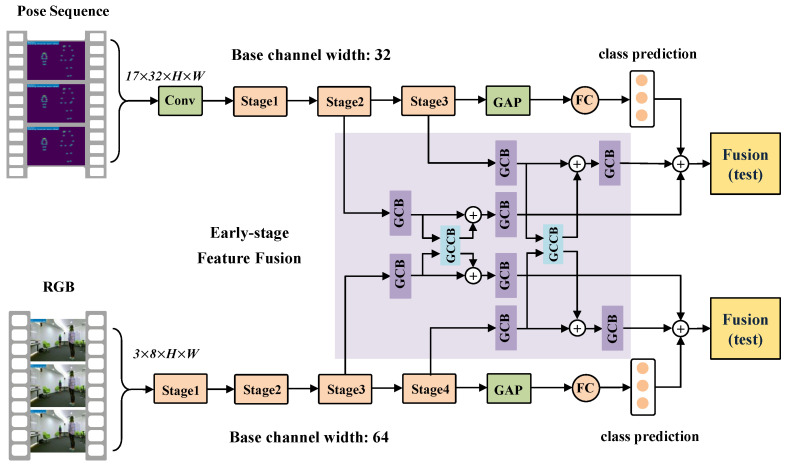
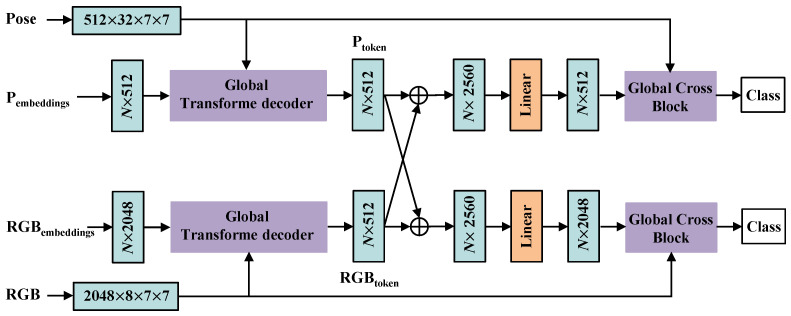
Action recognition based on 3D heatmap volumes has received increasing attention recently because it is suitable for application to 3D CNNs to improve the recognition performance of deep networks. However, it is difficult for models to capture global dependencies due to their restricted receptive field. To effectively capture long-range dependencies and balance computations, a novel model, PoseTransformer3D with Global Cross Blocks (GCBs), is proposed for pose-based action recognition. The proposed model extracts spatio-temporal features from processed 3D heatmap volumes. Moreover, we design a further recognition framework, RGB-PoseTransformer3D with Global Cross Complementary Blocks (GCCBs), for multimodality feature learning from both pose and RGB data. To verify the effectiveness of this model, we conducted extensive experiments on four popular video datasets, namely FineGYM, HMDB51, NTU RGB+D 60, and NTU RGB+D 120. Experimental results show that the proposed recognition framework always achieves state-of-the-art recognition performance, substantially improving multimodality learning through action recognition.
基于3D热图体的动作识别最近受到了越来越多的关注,因为它适用于3D卷积神经网络(3D CNN),以提高深度网络的识别性能。然而,由于模型的感受野有限,它们难以捕捉全局依赖性。为了有效地捕捉长距离依赖性并平衡计算量,我们提出了一种新颖的模型——带有全局交叉块(GCB)的PoseTransformer3D,用于基于姿态的动作识别。所提出的模型从处理后的3D热图体中提取时空特征。此外,我们还设计了一个进一步的识别框架——带有全局交叉互补块(GCCB)的RGB-PoseTransformer3D,用于从姿态和RGB数据中进行多模态特征学习。为了验证该模型的有效性,我们在四个流行的视频数据集上进行了广泛的实验,即FineGYM、HMDB51、NTU RGB+D 60和NTU RGB+D 120。实验结果表明,所提出的识别框架始终能达到当前最优的识别性能,通过动作识别显著改进了多模态学习。