Meldau Eva-Lisa, Bista Shachi, Melgarejo-González Carlos, Norén G Niklas
Uppsala Monitoring Centre, Uppsala, Sweden.
BMC Med Inform Decis Mak. 2024 Dec 23;24(1):401. doi: 10.1186/s12911-024-02785-9.
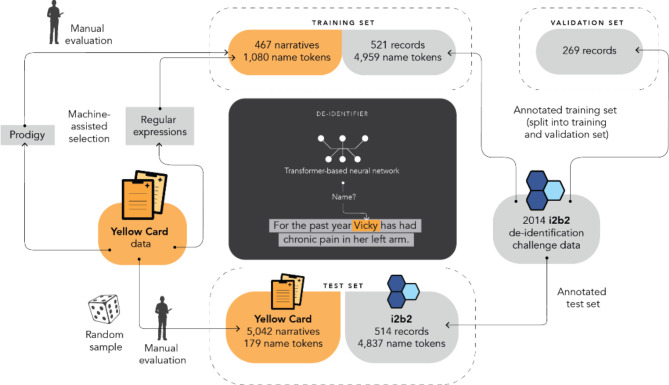
Automated recognition and redaction of personal identifiers in free text can enable organisations to share data while protecting privacy. This is important in the context of pharmacovigilance since relevant detailed information on the clinical course of events, differential diagnosis, and patient-reported reflections may often only be conveyed in narrative form. The aim of this study is to develop and evaluate a method for automated redaction of person names in English narrative text on adverse event reports. The target domain for this study was case narratives from the United Kingdom's Yellow Card scheme, which collects and monitors information on suspected side effects to medicines and vaccines.
We finetuned BERT - a transformer-based neural network - for recognising names in case narratives. Training data consisted of newly annotated records from the Yellow Card data and of the i2b2 2014 deidentification challenge. Because the Yellow Card data contained few names, we used predictive models to select narratives for training. Performance was evaluated on a separate set of annotated narratives from the Yellow Card scheme. In-depth review determined whether (parts of) person names missed by the de-identification method could enable re-identification of the individual, and whether de-identification reduced the clinical utility of narratives by collaterally masking relevant information.
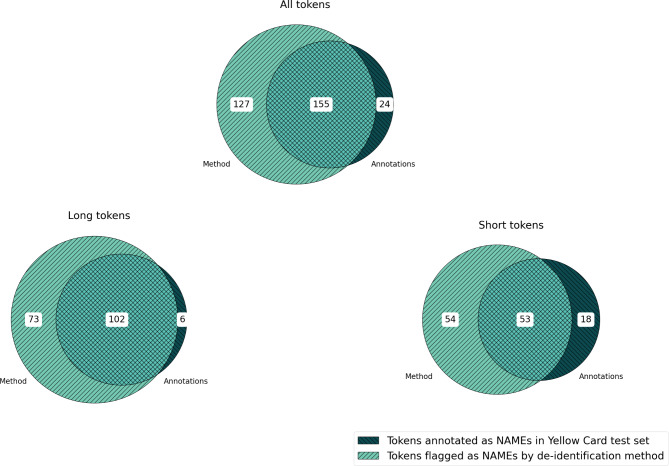
Recall on held-out Yellow Card data was 87% (155/179) at a precision of 55% (155/282) and a false-positive rate of 0.05% (127/ 263,451). Considering tokens longer than three characters separately, recall was 94% (102/108) and precision 58% (102/175). For 13 of the 5,042 narratives in Yellow Card test data (71 with person names), the method failed to flag at least one name token. According to in-depth review, the leaked information could enable direct identification for one narrative and indirect identification for two narratives. Clinically relevant information was removed in less than 1% of the 5,042 processed narratives; 97% of the narratives were completely untouched.
Automated redaction of names in free-text narratives of adverse event reports can achieve sufficient recall including shorter tokens like patient initials. In-depth review shows that the rare leaks that occur tend not to compromise patient confidentiality. Precision and false positive rates are acceptable with almost all clinically relevant information retained.
在自由文本中自动识别和编辑个人标识符,可使组织在保护隐私的同时共享数据。这在药物警戒背景下很重要,因为关于事件临床过程、鉴别诊断以及患者报告的想法等相关详细信息通常只能以叙述形式传达。本研究的目的是开发并评估一种对英文叙述性不良事件报告中的人名进行自动编辑的方法。本研究的目标领域是英国黄卡计划中的病例叙述,该计划收集并监测有关药品和疫苗疑似副作用的信息。
我们对基于变换器的神经网络BERT进行微调,以识别病例叙述中的人名。训练数据包括来自黄卡数据的新注释记录以及i2b2 2014去识别挑战数据。由于黄卡数据中人名较少,我们使用预测模型来选择用于训练的叙述。在另一组来自黄卡计划的注释叙述上评估性能。深入审查确定去识别方法遗漏的(部分)人名是否会导致个人被重新识别,以及去识别是否因附带掩盖相关信息而降低了叙述的临床实用性。
在保留的黄卡数据上,召回率为87%(155/179),精确率为55%(155/282),假阳性率为0.05%(127/263451)。分别考虑长度超过三个字符的词元,召回率为94%(102/108),精确率为58%(102/175)。在黄卡测试数据的5042条叙述(其中71条有人名)中,该方法未能标记至少一个人名词元的有13条。根据深入审查,泄露的信息能够直接识别一条叙述,间接识别两条叙述。在处理的5042条叙述中,不到1%的叙述中临床相关信息被删除;97%的叙述完全未受影响。
在不良事件报告的自由文本叙述中自动编辑人名能够实现足够的召回率,包括像患者姓名首字母这样较短的词元。深入审查表明,出现的罕见信息泄露往往不会损害患者的保密性。精确率和假阳性率是可接受的,几乎所有临床相关信息都得以保留。