Liang Ye, Wang Ru, Wang Yuchen, Liu Tieming
Department of Statistics, Oklahoma State University, Stillwater, OK, USA.
Dell Technologies, Round Rock, TX, USA.
Intell Based Med. 2024;10. doi: 10.1016/j.ibmed.2024.100154. Epub 2024 Jul 5.
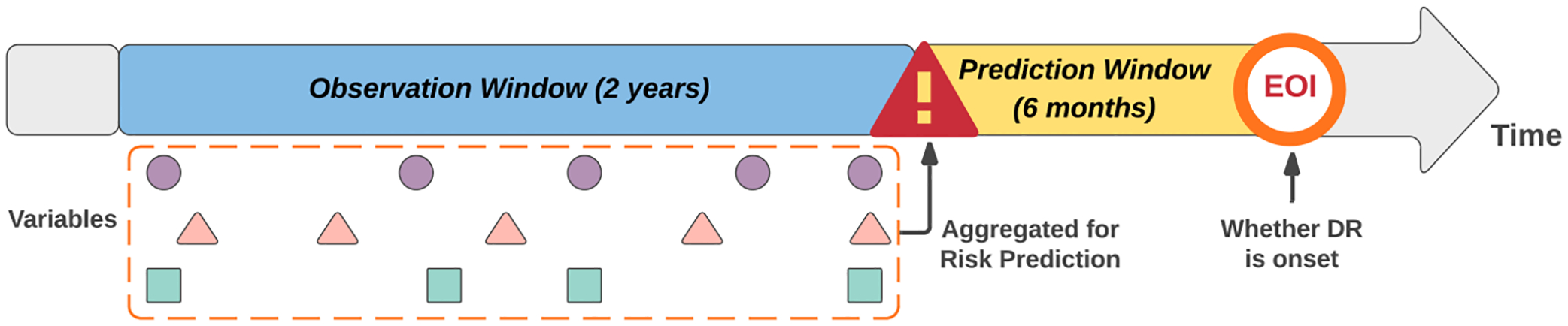
The paper aims to address the problem of massive unlabeled patients in electronic health records (EHR) who potentially have undiagnosed diabetic retinopathy (DR). It is desired to estimate the actual DR prevalence in EHR with 96 % missing labels.
The Cerner Health Facts data are used in the study, with 3749 labeled DR patients and 97,876 unlabeled diabetic patients. This extensive dataset spans the demographics of the United States over the past two decades. We implemented state-of-art positive-unlabeled learning methods, including ensemble-based support vector machine, ensemble-based random forest, and Bayesian finite mixture modeling.
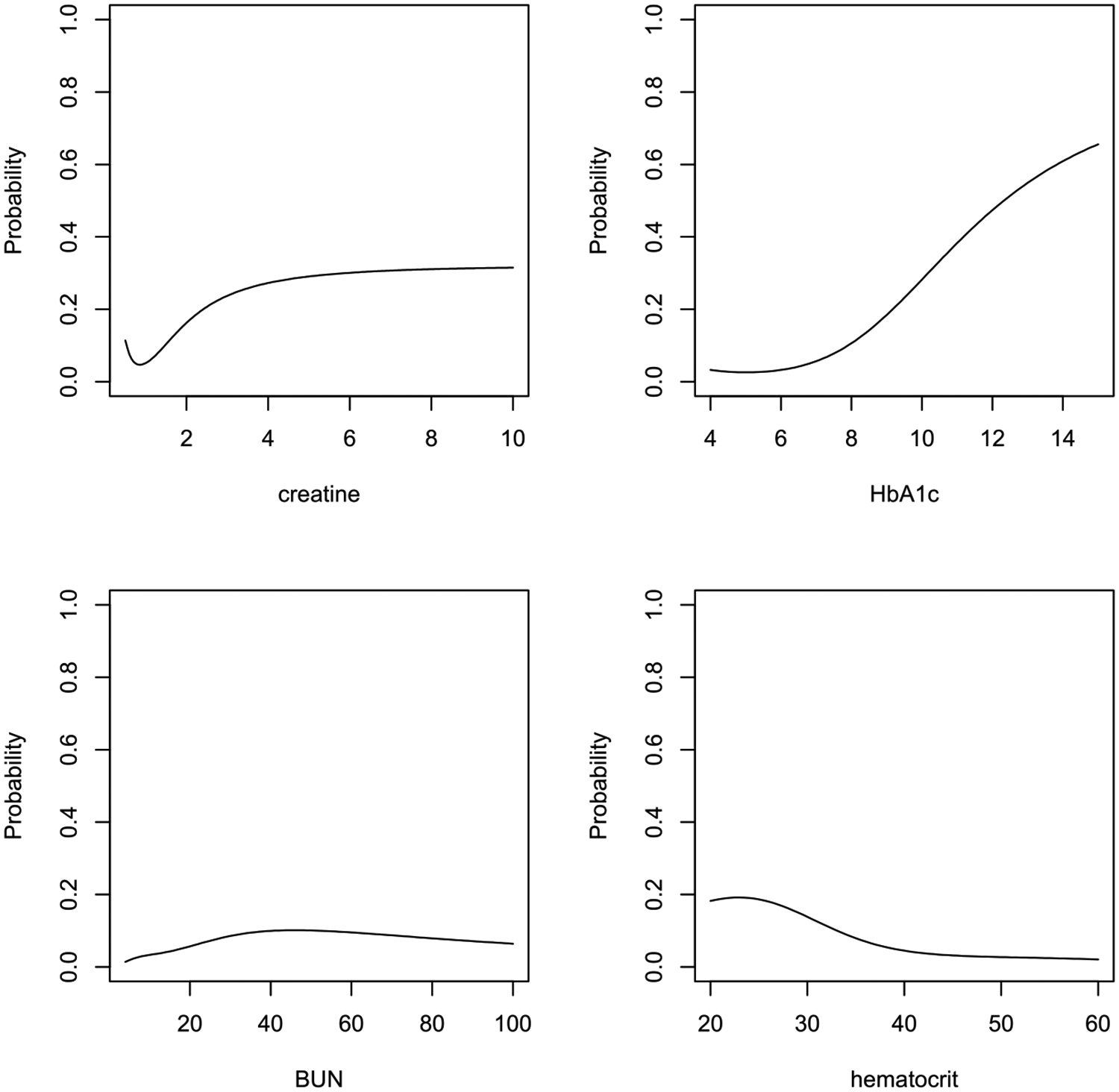
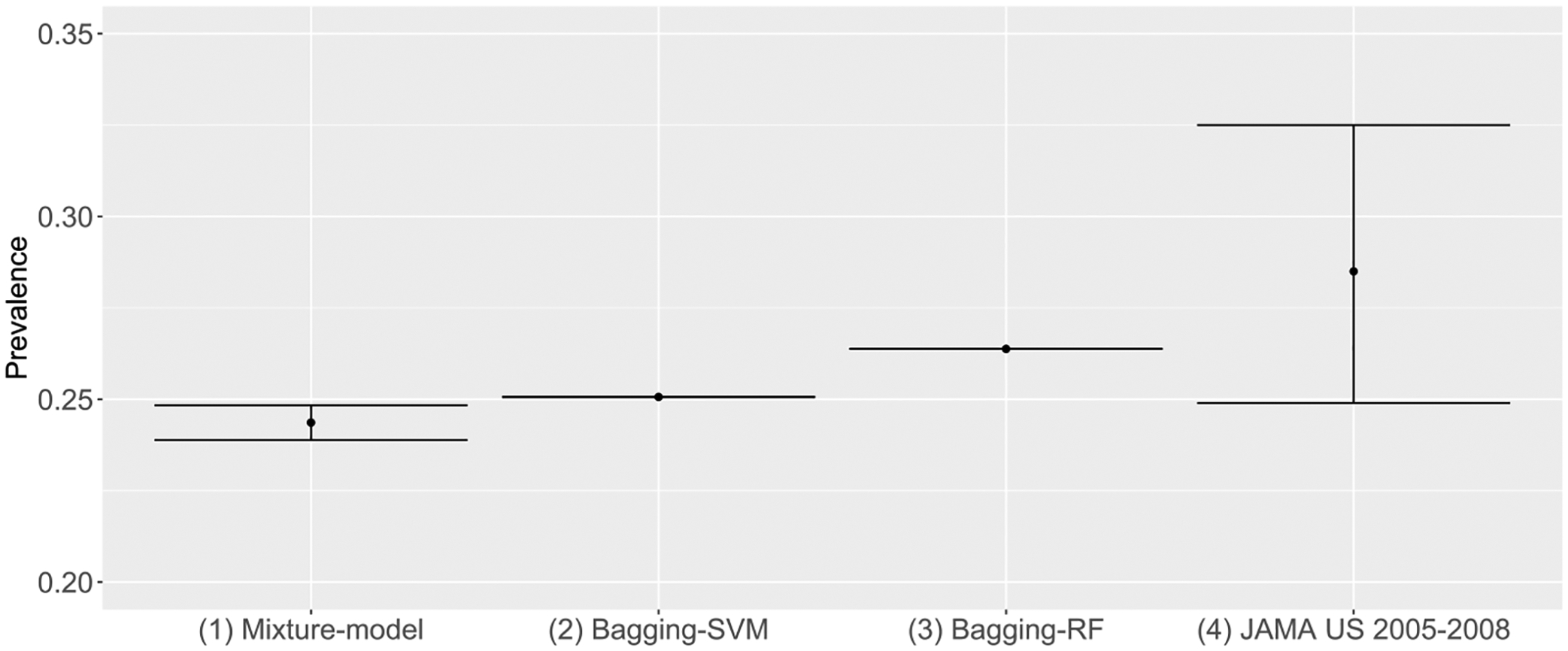
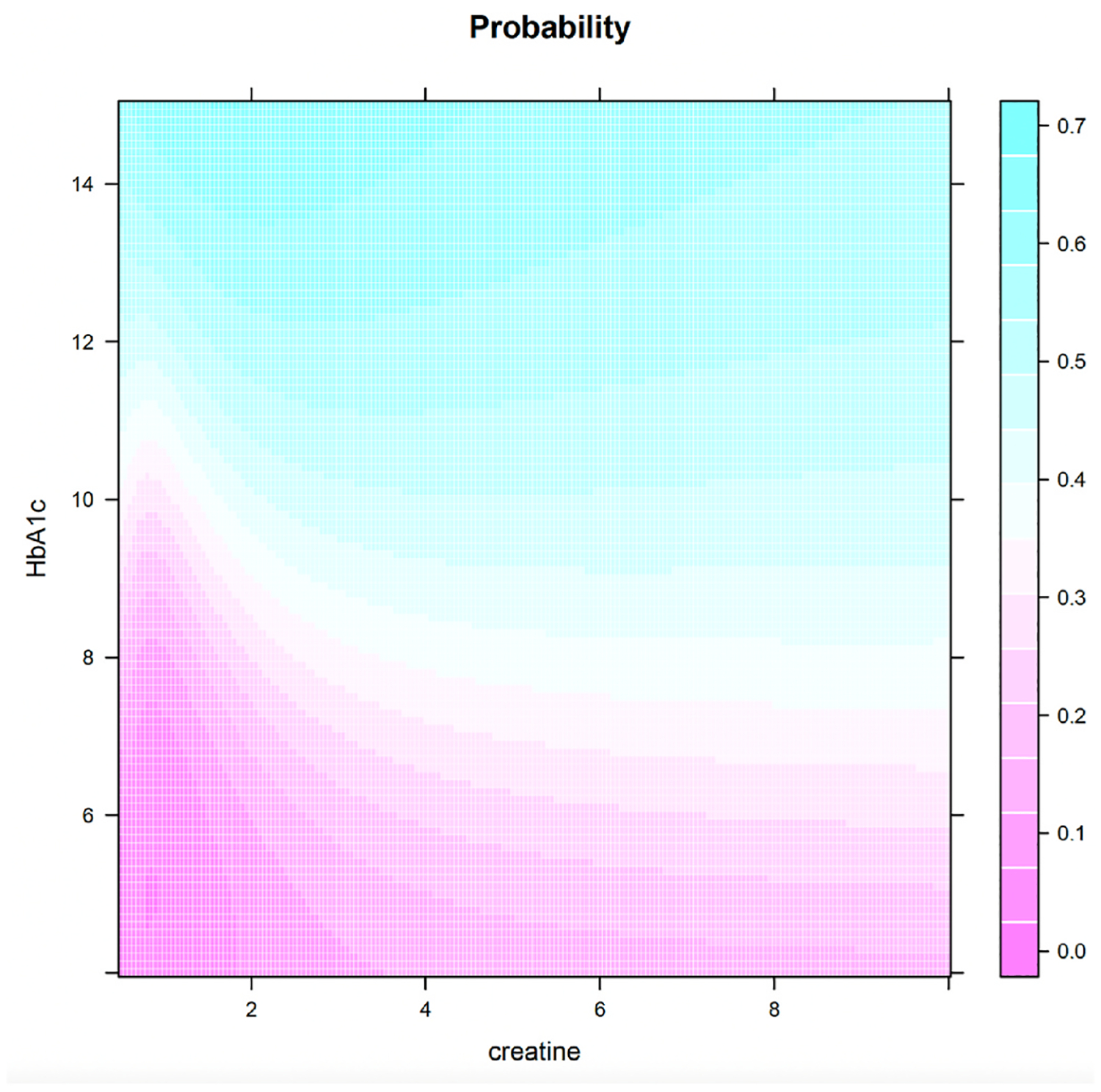
The estimated DR prevalence in the population represented by Cerner EHR is approximately 25 % and the classification techniques generally achieve an AUC of around 87 %. As a by-product, a predictive inference on the risk of DR based on a patient's personalized medical information is derived.
Missing labels is a common issue for EHR data quality. Ignoring these missing labels can lead to biased results in the analyses of EHR data. The problem is especially severe in the context of DR. It is thus important to use machine learning or statistical tools to identify the unlabeled patients. The tool in this paper helps both data analysts and clinicians in their practices.
本文旨在解决电子健康记录(EHR)中大量未标记患者的问题,这些患者可能患有未确诊的糖尿病视网膜病变(DR)。期望在96%标签缺失的情况下估计EHR中DR的实际患病率。
本研究使用了Cerner健康事实数据,其中有3749名标记了DR的患者和97876名未标记的糖尿病患者。这个庞大的数据集涵盖了过去二十年美国的人口统计数据。我们实施了先进的正无标记学习方法,包括基于集成的支持向量机、基于集成的随机森林和贝叶斯有限混合模型。
Cerner EHR所代表的人群中估计的DR患病率约为25%,分类技术通常实现的曲线下面积(AUC)约为87%。作为副产品,基于患者的个性化医疗信息得出了对DR风险的预测推断。
标签缺失是EHR数据质量的常见问题。在EHR数据分析中忽略这些缺失标签会导致有偏差的结果。在DR的背景下,这个问题尤其严重。因此,使用机器学习或统计工具来识别未标记患者很重要。本文中的工具对数据分析师和临床医生的实践都有帮助。