Wang Xiaolan
The Higher Educational Key Laboratory for Flexible Manufacturing Equipment Integration of Fujian Province (Xiamen Institute of Technology), Xiamen, 361021, China.
Sci Rep. 2025 Jan 7;15(1):1079. doi: 10.1038/s41598-025-85602-1.
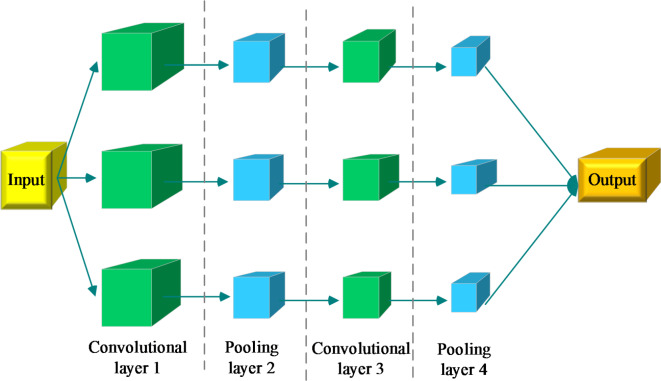
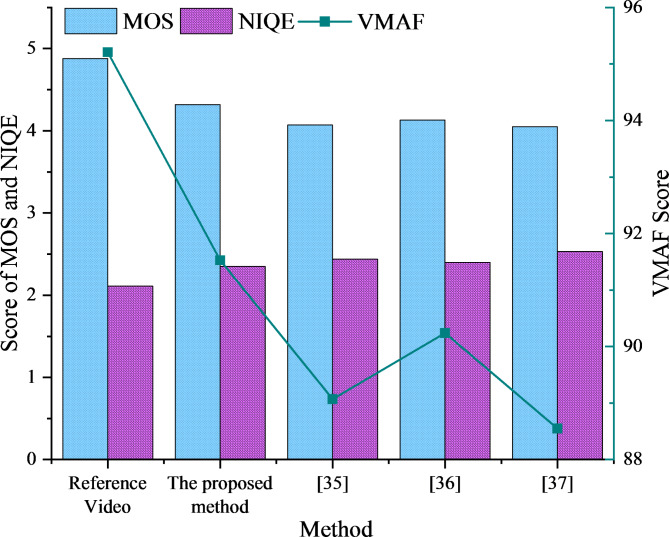
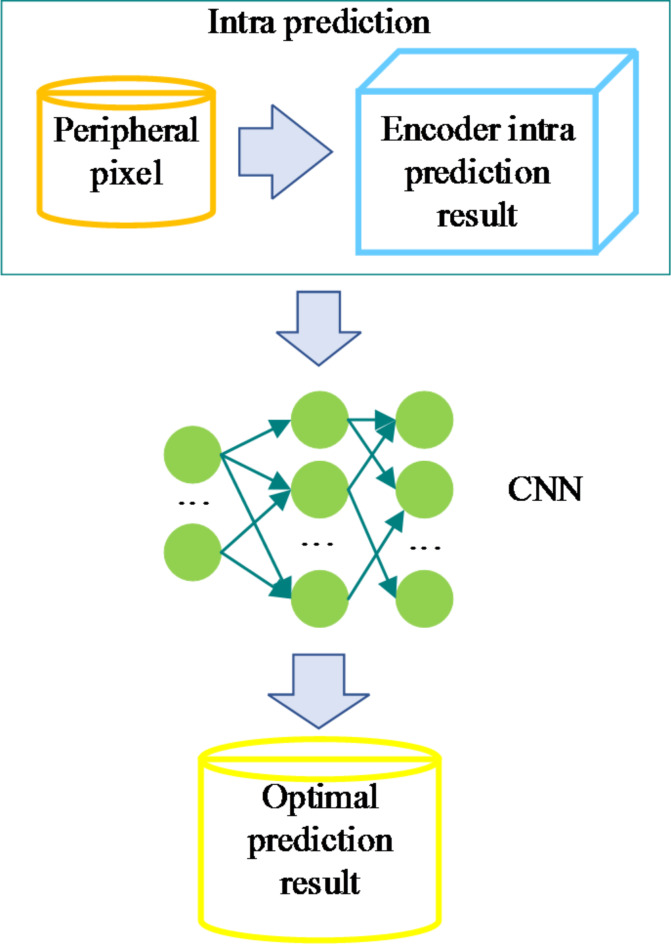
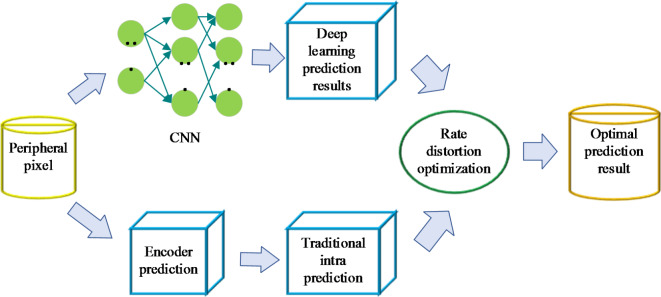
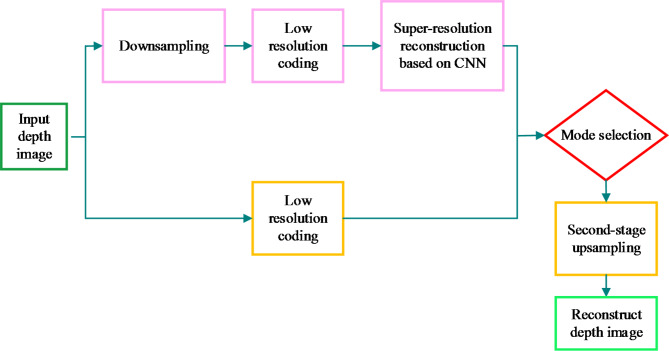
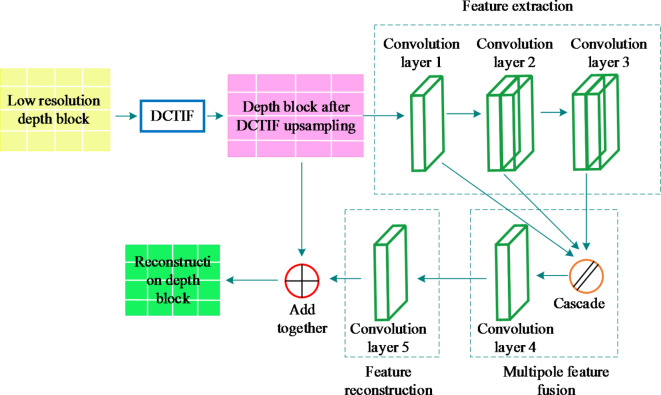
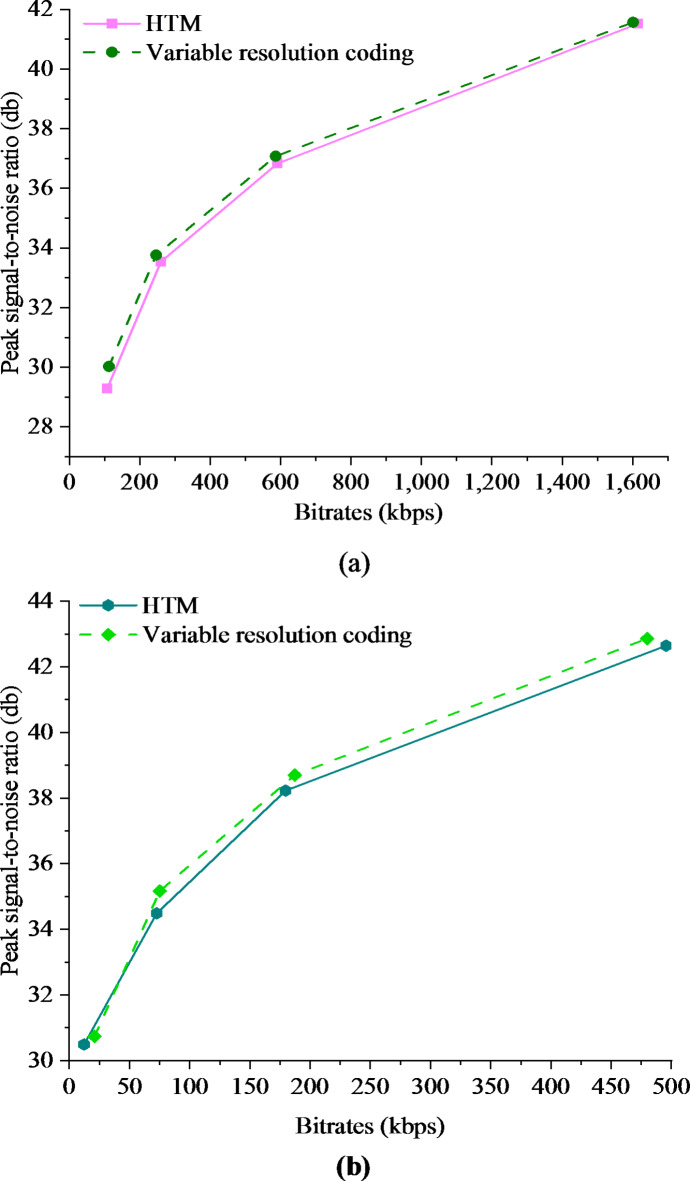
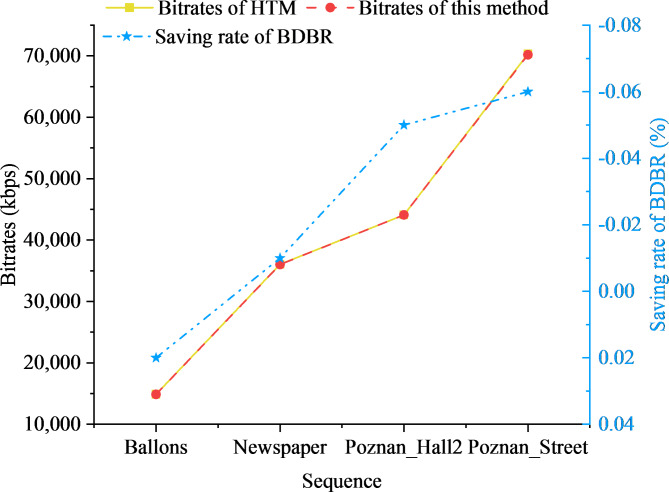
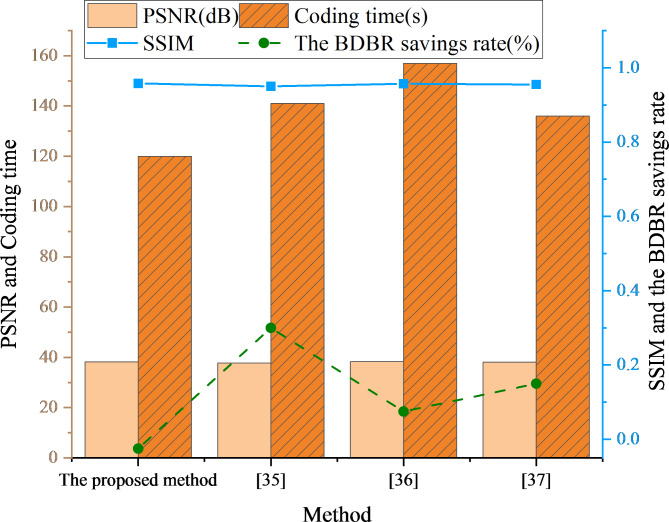
With ongoing social progress, three-dimensional (3D) video is becoming increasingly prevalent in everyday life. As a key component of 3D video technology, depth video plays a crucial role by providing information about the distance and spatial distribution of objects within a scene. This study focuses on deep video encoding and proposes an efficient encoding method that integrates the Convolutional Neural Network (CNN) with a hyperautomation mechanism. First, an overview of the principles underlying CNNs and the concept of hyperautomation is presented, and the application of CNNs in the intra-frame prediction module of video encoding is explored. By incorporating the hyperautomation mechanism, this study emphasizes the potential of Artificial Intelligence to enhance encoding efficiency. Next, a CNN-based method for variable-resolution intra-frame prediction of depth video is proposed. This method utilizes a multi-level feature fusion network to reconstruct coding units. The effectiveness of the proposed variable-resolution coding technique is then evaluated by comparing its performance against the original method on the high-efficiency video coding (HEVC) test platform. The results demonstrate that, compared to the original test platform method (HTM-16.2), the proposed method achieves an average Bjøntegaard delta bit rate (BDBR) savings of 8.12% across all tested video sequences. This indicates a significant improvement in coding efficiency. Furthermore, the viewpoint BDBR loss of the variable-resolution coding method is only 0.15%, which falls within an acceptable margin of error. This suggests that the method is both stable and reliable in viewpoint coding, and it performs well across a broad range of quantization parameter settings. Additionally, compared to other encoding methods, the proposed approach exhibits superior peak signal-to-noise ratio, structural similarity index, and perceptual quality metrics. This study introduces a novel and efficient approach to 3D video compression, and the integration of CNNs with hyperautomation provides valuable insights for future innovations in video encoding.
随着社会的不断进步,三维(3D)视频在日常生活中越来越普遍。作为3D视频技术的关键组成部分,深度视频通过提供场景中物体的距离和空间分布信息发挥着至关重要的作用。本研究聚焦于深度视频编码,并提出了一种将卷积神经网络(CNN)与超自动化机制相结合的高效编码方法。首先,介绍了CNN的基本原理和超自动化的概念,并探讨了CNN在视频编码帧内预测模块中的应用。通过纳入超自动化机制,本研究强调了人工智能提高编码效率的潜力。接下来,提出了一种基于CNN的深度视频可变分辨率帧内预测方法。该方法利用多级特征融合网络来重建编码单元。然后,通过在高效视频编码(HEVC)测试平台上与原始方法比较性能,评估了所提出的可变分辨率编码技术的有效性。结果表明,与原始测试平台方法(HTM - 16.2)相比,所提出的方法在所有测试视频序列上平均节省了8.12%的Bjøntegaard 增量比特率(BDBR)。这表明编码效率有显著提高。此外,可变分辨率编码方法的视点BDBR损失仅为0.15%,处于可接受的误差范围内。这表明该方法在视点编码中既稳定又可靠,并且在广泛的量化参数设置下表现良好。此外,与其他编码方法相比,所提出的方法在峰值信噪比、结构相似性指数和感知质量指标方面表现优异。本研究介绍了一种新颖且高效的3D视频压缩方法,CNN与超自动化的集成可为视频编码的未来创新提供有价值的见解。