Rhein Frank, Sehn Timo, Meier Michael A R
Institute of Mechanical Process Engineering and Mechanics (MVM), Karlsruhe Institute of Technology (KIT), Karlsruhe, 76131, Germany.
Institute of Biological and Chemical Systems - Functional Molecular Systems (IBCS-FMS), Karlsruhe Institute of Technology (KIT), Karlsruhe, 76344, Germany.
Sci Rep. 2025 Jan 23;15(1):2904. doi: 10.1038/s41598-025-86378-0.
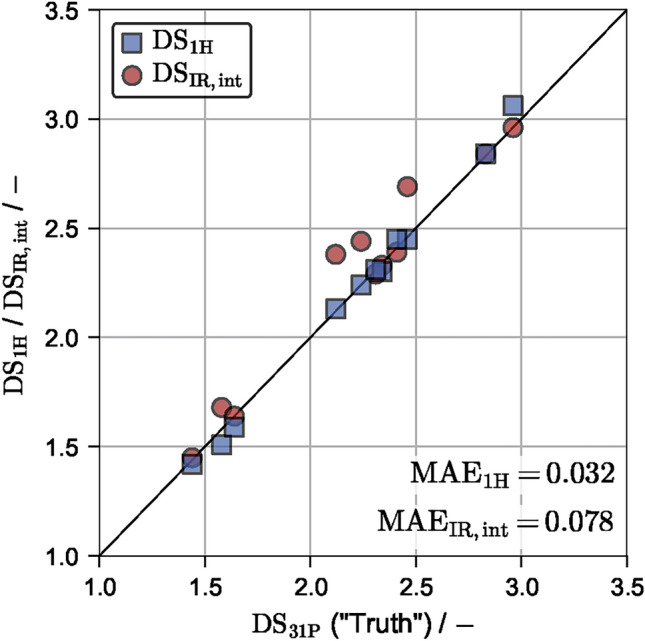
Multiple linear regression models were trained to predict the degree of substitution (DS) of cellulose acetate based on raw infrared (IR) spectroscopic data. A repeated k-fold cross validation ensured unbiased assessment of model accuracy. Using the DS obtained from H NMR data as reference, the machine learning model achieved a mean absolute error (MAE) of 0.069 in DS on test data, demonstrating higher accuracy compared to the manual evaluation based on peak integration. Limiting the model to physically relevant areas unexpectedly showed the [Formula: see text] peak to be the strongest predictor of DS. By applying a n-best feature selection algorithm based on the F-statistic of the Pearson correlation coefficient, several relevant areas were identified and the optimized model achieved an improved MAE of 0.052. Predicting the DS of other cellulose acetate data sets yielded similar accuracy, demonstrating that the developed models are robust and suitable for efficient and accurate routine evaluations. The model solely trained on cellulose acetate was further able to predict the DS of other cellulose esters with an accuracy of [Formula: see text] in DS and model architectures for a more general analysis of cellulose esters were proposed.
基于原始红外(IR)光谱数据,训练了多个线性回归模型来预测醋酸纤维素的取代度(DS)。重复的k折交叉验证确保了对模型准确性的无偏评估。以从1H NMR数据获得的DS作为参考,机器学习模型在测试数据上的DS平均绝对误差(MAE)为0.069,与基于峰积分的人工评估相比,显示出更高的准确性。将模型限制在物理相关区域意外地表明,[公式:见正文]峰是DS的最强预测因子。通过应用基于皮尔逊相关系数F统计量的n最佳特征选择算法,确定了几个相关区域,优化后的模型MAE提高到0.052。对其他醋酸纤维素数据集的DS预测也得到了类似的准确性,表明所开发的模型具有鲁棒性,适用于高效准确的常规评估。仅在醋酸纤维素上训练的模型进一步能够以DS为[公式:见正文]的准确性预测其他纤维素酯的DS,并提出了用于纤维素酯更通用分析的模型架构。