Sela Alon, Neter Omer, Lohr Václav, Cihelka Petr, Wang Fan, Zwilling Moti, Phillip Sabou John, Ulman Miloš
Agricultural Engineering Department, The Volcani Agricultural Research Organization (ARO), Bet Dagan, Israel.
Department Industrial Engineering, Ariel University, Ariel, Israel.
PLoS One. 2025 Jan 30;20(1):e0309688. doi: 10.1371/journal.pone.0309688. eCollection 2025.
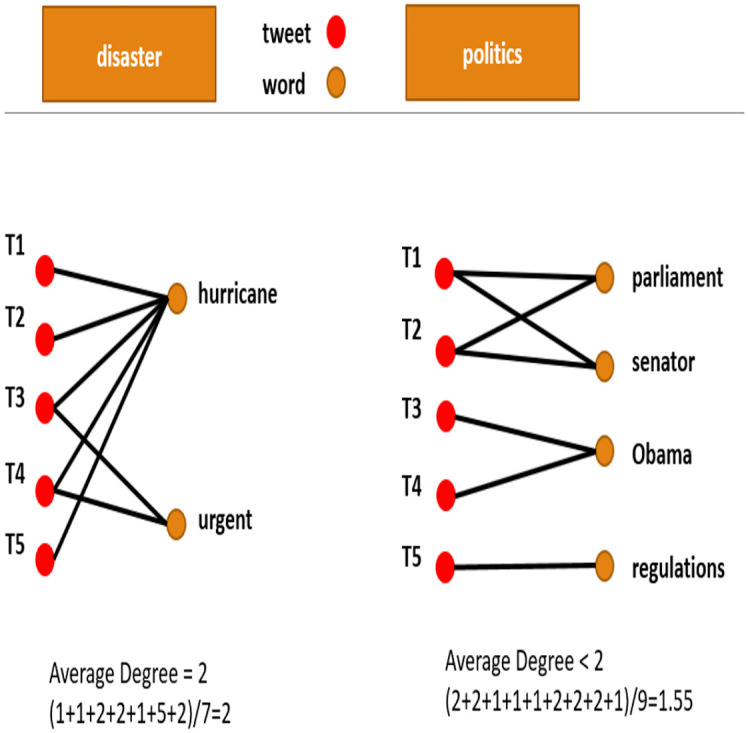
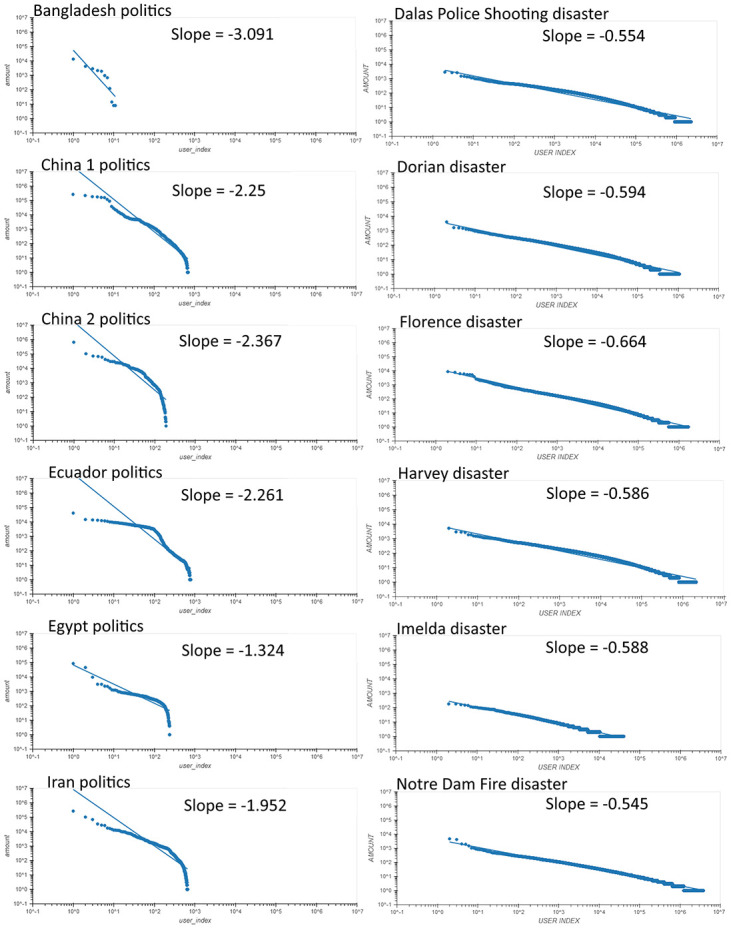
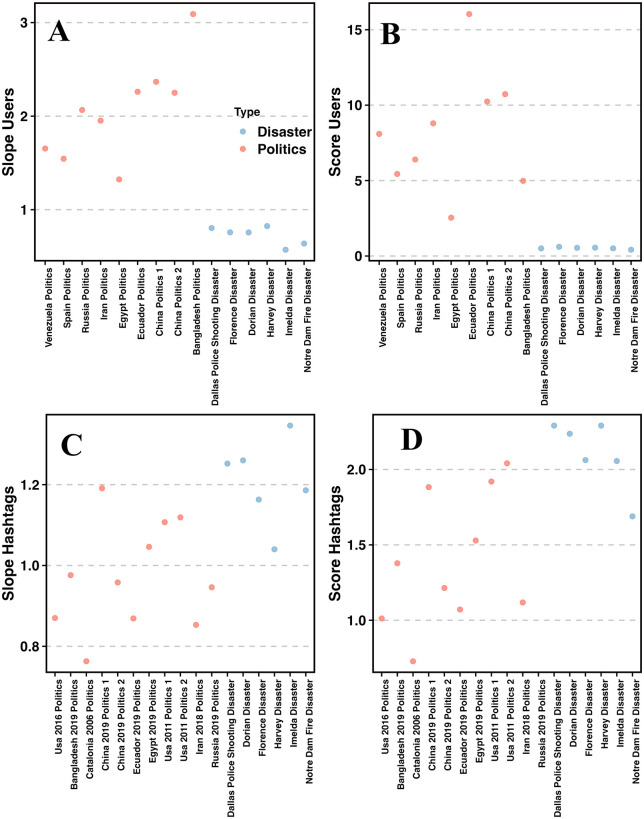
Social networks are a battlefield for political propaganda. Protected by the anonymity of the internet, political actors use computational propaganda to influence the masses. Their methods include the use of synchronized or individual bots, multiple accounts operated by one social media management tool, or different manipulations of search engines and social network algorithms, all aiming to promote their ideology. While computational propaganda influences modern society, it is hard to measure or detect it. Furthermore, with the recent exponential growth in large language models (L.L.M), and the growing concerns about information overload, which makes the alternative truth spheres more noisy than ever before, the complexity and magnitude of computational propaganda is also expected to increase, making their detection even harder. Propaganda in social networks is disguised as legitimate news sent from authentic users. It smartly blended real users with fake accounts. We seek here to detect efforts to manipulate the spread of information in social networks, by one of the fundamental macro-scale properties of rhetoric-repetitiveness. We use 16 data sets of a total size of 13 GB, 10 related to political topics and 6 related to non-political ones (large-scale disasters), each ranging from tens of thousands to a few million of tweets. We compare them and identify statistical and network properties that distinguish between these two types of information cascades. These features are based on both the repetition distribution of hashtags and the mentions of users, as well as the network structure. Together, they enable us to distinguish (p - value = 0.0001) between the two different classes of information cascades. In addition to constructing a bipartite graph connecting words and tweets to each cascade, we develop a quantitative measure and show how it can be used to distinguish between political and non-political discussions. Our method is indifferent to the cascade's country of origin, language, or cultural background since it is only based on the statistical properties of repetitiveness and the word appearance in tweets bipartite network structures.
社交网络是政治宣传的战场。在互联网匿名性的保护下,政治行为者利用计算宣传来影响大众。他们的手段包括使用同步或单个机器人程序、由一个社交媒体管理工具操作的多个账户,或对搜索引擎和社交网络算法进行不同的操纵,所有这些都是为了宣扬他们的意识形态。虽然计算宣传影响着现代社会,但却很难对其进行衡量或检测。此外,随着最近大语言模型(LLM)呈指数级增长,以及人们对信息过载的担忧日益增加,这使得虚假信息领域比以往任何时候都更加嘈杂,计算宣传的复杂性和规模预计也会增加,使其检测变得更加困难。社交网络中的宣传被伪装成真实用户发送的合法新闻。它巧妙地将真实用户与虚假账户混在一起。我们在此试图通过修辞的一个基本宏观属性——重复性,来检测在社交网络中操纵信息传播的行为。我们使用了16个数据集,总大小为13GB,其中10个与政治话题相关,6个与非政治话题(大规模灾难)相关,每个数据集包含从数万到数百万条推文。我们对它们进行比较,并识别出区分这两种信息传播的统计和网络属性。这些特征既基于主题标签的重复分布和用户提及情况,也基于网络结构。它们共同使我们能够区分(p值 = 0.0001)这两种不同类型的信息传播。除了构建一个将单词和推文连接到每个传播的二分图之外,我们还开发了一种定量测量方法,并展示了如何用它来区分政治和非政治讨论。我们的方法对传播的来源国、语言或文化背景不敏感,因为它仅基于重复性的统计属性以及推文中单词在二分网络结构中的出现情况。