Bhushan Ram Chandra, Donthi Rakesh Kumar, Chilukuri Yojitha, Srinivasarao Ulligaddala, Swetha Polisetty
Software Architect, Alstom Transport India Limited, Bengaluru, India.
Department of CSE GITAM (Deemed to be) UNIVERSITY Hyderabad, Rudraram, India.
BMC Bioinformatics. 2025 Jan 30;26(1):34. doi: 10.1186/s12859-024-06008-w.
Biomedical text mining is a technique that extracts essential information from scientific articles using named entity recognition (NER). Traditional NER methods rely on dictionaries, rules, or curated corpora, which may not always be accessible. To overcome these challenges, deep learning (DL) methods have emerged. However, DL-based NER methods may need help identifying long-distance relationships within text and require significant annotated datasets.
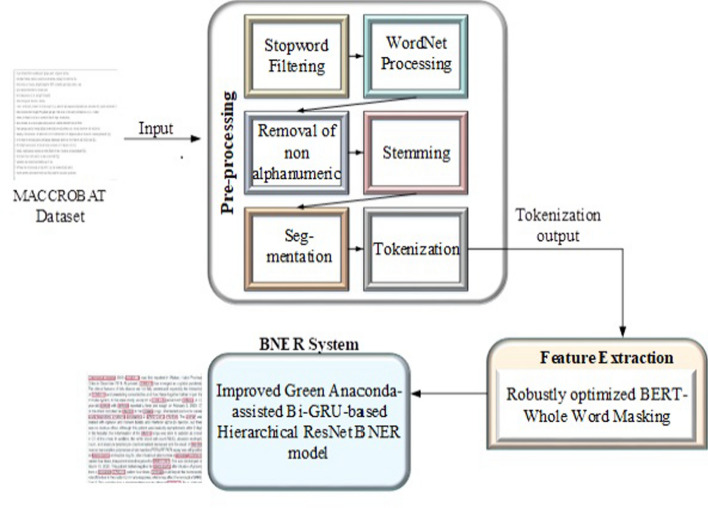
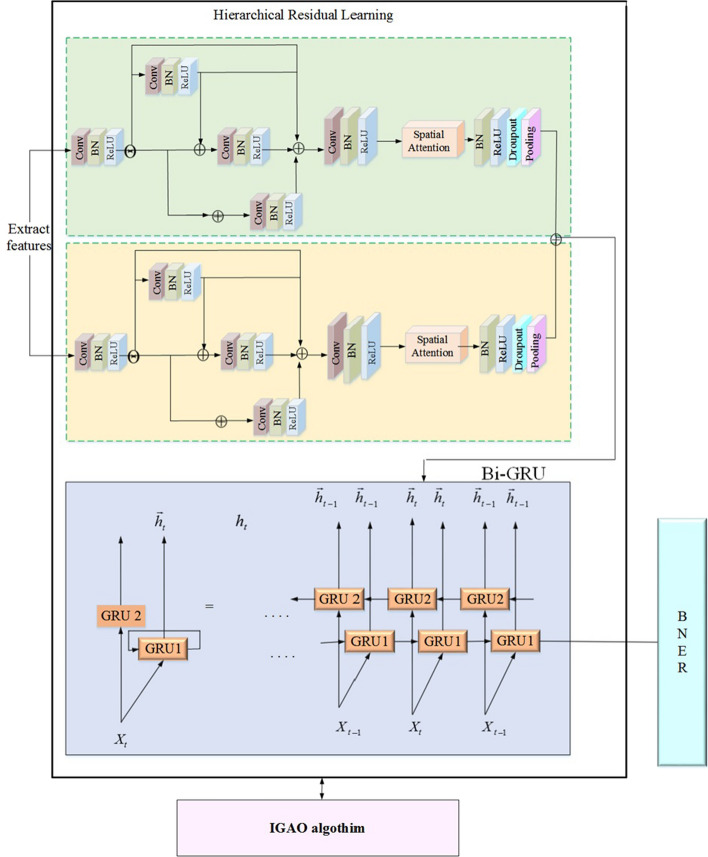
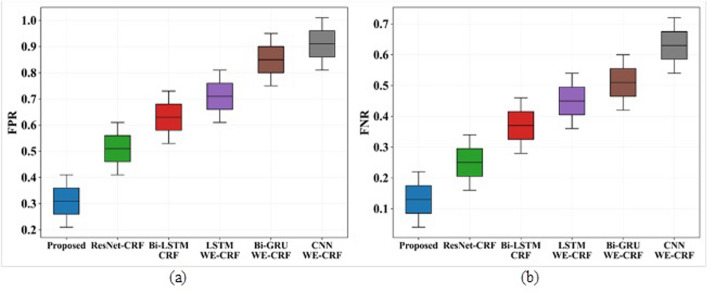
This research has proposed a novel model to address the challenges in natural language processing. The Improved Green anaconda-assisted Bi-GRU based Hierarchical ResNet BNER model (IGa-BiHR BNERM) is the model. IGa-BiHR BNERM model has shown promising results in accurately identifying named entities. The MACCROBAT dataset was obtained from Kaggle and underwent several pre-processing steps such as Stop Word Filtering, WordNet processing, Removal of non-alphanumeric characters, stemming Segmentation, and Tokenization, which is standardized and improves its quality. The pre-processed text was fed into a feature extraction model like the Robustly Optimized BERT -Whole Word Masking model. This model provides word embeddings with semantic information. Then, the BNER process utilized an Improved Green Anaconda-assisted Bi-GRU-based Hierarchical ResNet BNER model (IGa-BiHR BNERM).
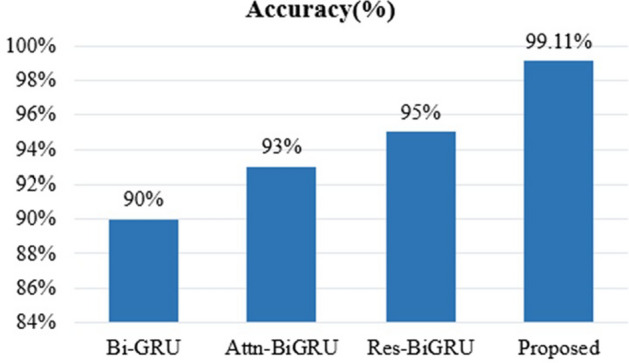
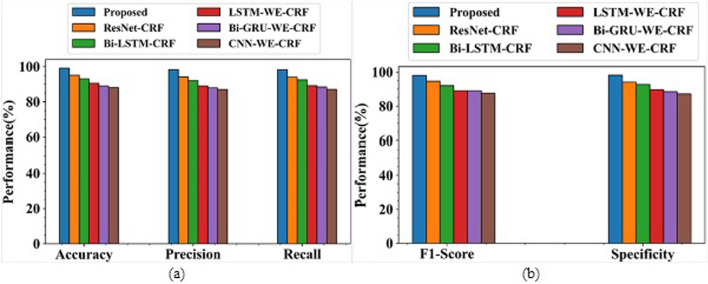
To improve the training phase of the IGa-BiHR BNERM, the Improved Green Anaconda Optimization technique was used to select optimal weight parameter coefficients for training the model parameters. After the model was tested using the MACCROBAT dataset, it outperformed previous models with a tremendous accuracy rate of 99.11%. This model effectively and accurately identifies biomedical names within the text, significantly advancing this field.
生物医学文本挖掘是一种使用命名实体识别(NER)从科学文章中提取关键信息的技术。传统的NER方法依赖于词典、规则或精选语料库,而这些可能并非总是可用。为了克服这些挑战,深度学习(DL)方法应运而生。然而,基于DL的NER方法在识别文本中的长距离关系时可能会遇到困难,并且需要大量的标注数据集。
本研究提出了一种新颖的模型来应对自然语言处理中的挑战。改进的绿森蚺辅助双向门控循环单元(Bi-GRU)分层残差网络(ResNet)生物医学命名实体识别模型(IGa-BiHR BNERM)就是该模型。IGa-BiHR BNERM模型在准确识别命名实体方面显示出了有前景的结果。MACCROBAT数据集从Kaggle获得,并经过了几个预处理步骤,如停用词过滤、WordNet处理、去除非字母数字字符、词干提取、分词和令牌化,这些步骤使其标准化并提高了质量。预处理后的文本被输入到一个特征提取模型,如稳健优化的BERT - 全词掩码模型。该模型提供带有语义信息的词嵌入。然后,生物医学命名实体识别过程使用了改进的绿森蚺辅助双向门控循环单元分层残差网络生物医学命名实体识别模型(IGa-BiHR BNERM)。
为了改进IGa-BiHR BNERM的训练阶段,使用了改进的绿森蚺优化技术来选择用于训练模型参数的最优权重参数系数。在使用MACCROBAT数据集对模型进行测试后,它以99.11%的极高准确率超越了先前的模型。该模型有效地且准确地识别了文本中的生物医学名称,极大地推动了该领域的发展。