Li Xi, Chang Jui-Hsuan, Venkatesan Mythreye, Wang Zhiping Paul, Moore Jason H
Department of Computational Biomedicine, Cedars-Sinai Medical Center, Los Angeles, CA, 90069, USA.
BioData Min. 2025 Apr 15;18(1):30. doi: 10.1186/s13040-025-00446-9.
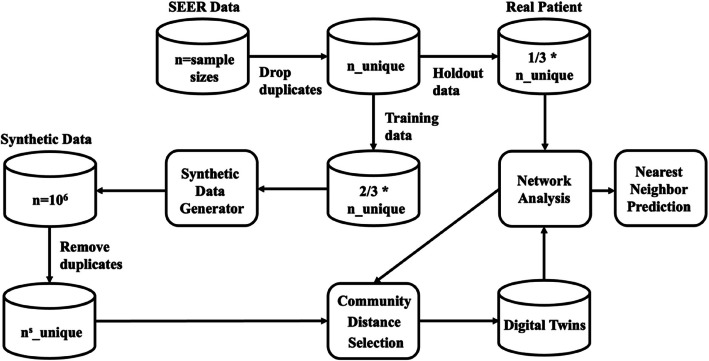
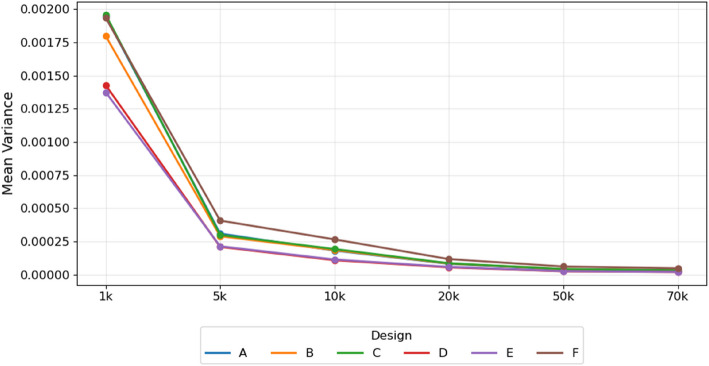
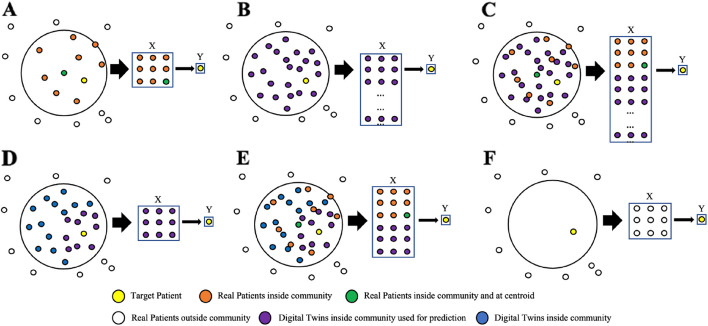
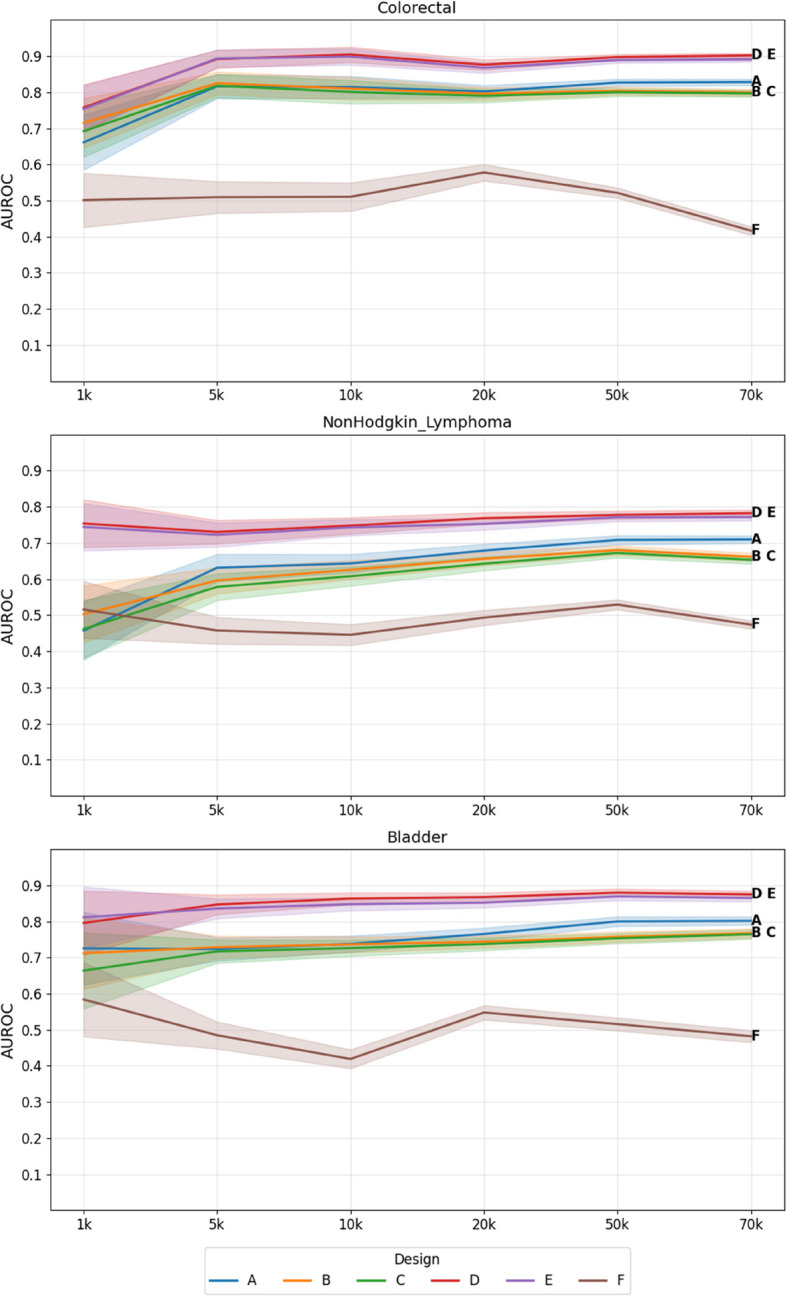
Digital twins in healthcare offer an innovative approach to precision diagnosis, prognosis, and treatment. SynTwin, a novel computational methodology to generate digital twins using synthetic data and network science, has previously shown promise for improving prediction of breast cancer mortality. In this study, we validate SynTwin using population-level data for different cancer types from the Surveillance, Epidemiology, and End Results (SEER) program from the National Cancer Institute (USA). We assess its predictive accuracy across cancer types of varying sample sizes (n = 1,000 to 30,000 records), mortality rates (35% to 60%), and study designs, revealing insights into the strengths and limitations of digital twins derived from synthetic data in mortality prediction. We also evaluate the effect of sample size (n = 1,000 to 70,000 records) on predictive accuracy for selected cancers (non-Hodgkin lymphoma, bladder, and colorectal cancers). Our results indicate that for larger datasets (n > 10,000) including digital twins in the nearest network neighbor prediction model significantly improves the performance compared to using real patients alone. Specifically, AUROCs ranged from 0.828 to 0.884 for cancers such as cervix uteri and ovarian cancer with digital twins, compared to 0.720 to 0.858 when using real patient data. Similarly, among the selected three cancers, AUROCs using digital twins exceeded AUROCs using real patients alone by at least 0.06 with narrowing variance in performance as the sample size increased. These results highlight the benefit of network-based digital twins, while emphasizing the importance of considering effective sample size when developing predictive models like SynTwin.
医疗保健领域的数字孪生技术为精准诊断、预后评估和治疗提供了一种创新方法。SynTwin是一种利用合成数据和网络科学生成数字孪生的新型计算方法,此前已显示出改善乳腺癌死亡率预测的潜力。在本研究中,我们使用美国国立癌症研究所监测、流行病学和最终结果(SEER)计划中不同癌症类型的人群水平数据对SynTwin进行验证。我们评估了其在不同样本量(n = 1000至30000条记录)、死亡率(35%至60%)和研究设计的癌症类型中的预测准确性,揭示了合成数据衍生的数字孪生在死亡率预测中的优势和局限性。我们还评估了样本量(n = 1000至70000条记录)对选定癌症(非霍奇金淋巴瘤、膀胱癌和结直肠癌)预测准确性的影响。我们的结果表明,对于较大的数据集(n > 10000),在最近网络邻居预测模型中纳入数字孪生相比仅使用真实患者可显著提高性能。具体而言,对于子宫颈癌和卵巢癌等癌症,使用数字孪生时的曲线下面积(AUROC)范围为0.828至0.884,而使用真实患者数据时为0.720至0.858。同样,在选定的三种癌症中,使用数字孪生的AUROC比仅使用真实患者的AUROC至少高出0.06,并且随着样本量增加性能差异缩小。这些结果突出了基于网络的数字孪生的益处,同时强调了在开发像SynTwin这样的预测模型时考虑有效样本量的重要性。