Jiang Chenhao, Dong Chuan, Wu Zhenzhen, Shi Chenyi, Ye Qiannan, Wu Xiaopei, Ma Siyi, Wen Yuming, Yu Guoping, Wu Jiasheng, Zhang Chengjun
National Key Laboratory for Development and Utilization of Forest Food Resources, Zhejiang A & F University, Hangzhou, Zhejiang, 311300, China.
Germplasm Bank of Wild Species & Yunnan Key Laboratory of Crop Wild Relatives Omics, Kunming Institute of Botany, Chinese Academy of Sciences, Kunming, Yunnan, 650201, China.
Plant Methods. 2025 May 16;21(1):61. doi: 10.1186/s13007-025-01380-x.
Simple sequence repeats (SSRs) are widely used as molecular markers; however, traditional development of SSR molecular markers heavily relies on experimental methods. The advancement of modern sequencing technology has provided the possibility of directly extracting SSR characteristics from sequencing data and using them for variety identification.
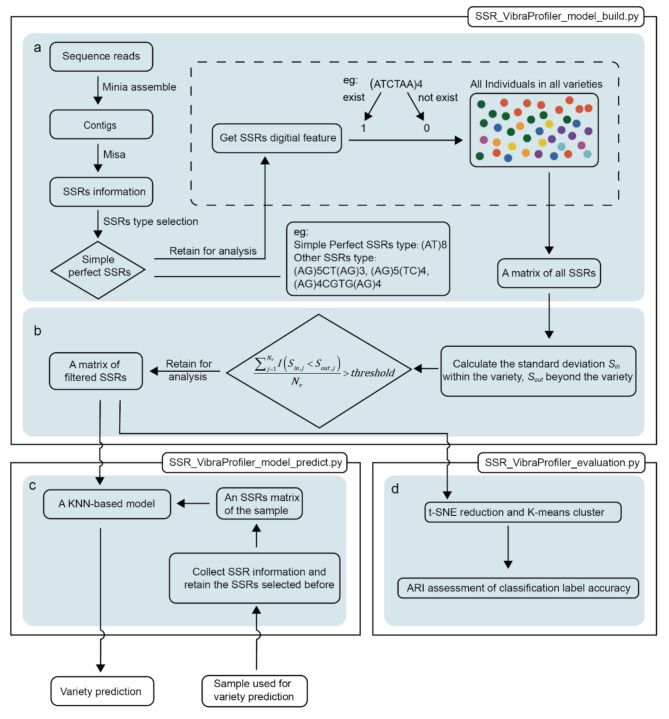
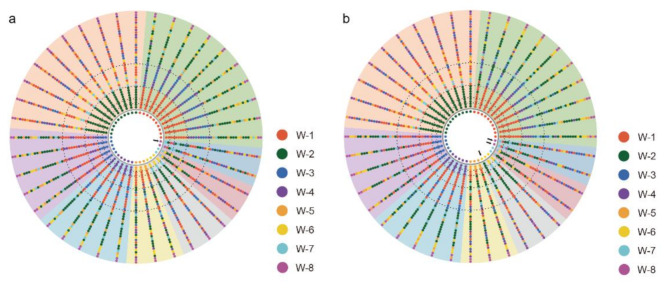
We have developed a computational framework for variety identification, treating the presence or absence of each SSR in sequencing data as a numerical characteristic while ignoring specific loci, flanking sequences, and occurrence counts. Therefore, subsequent variety identification does not rely on experimental validation but is directly performed based on the numerical characteristic matrix. Using a formula, we measure the variance of these numerical characteristics both within and among varieties, and select SSRs that exhibit intra-variety specificity and inter-variety polymorphism, forming a 0,1 matrix. We use t-SNE (t-distributed Stochastic Neighbor Embedding) to project the matrix onto a two-dimensional plane, followed by K-means clustering of the individuals. The classification performance of the matrix is preliminarily assessed by comparing the cluster labels with the true labels, providing an initial evaluation of its effectiveness in variety detection. Ultimately, we construct a recognition model based on the SSRs matrix and apply it for variety identification. The process has been encapsulated into the package SSR_VibraProfiler, which can serve as a tool for constructing an SSR variety DNA fingerprint database. We tested this package on a Rhododendron dataset that included 40 individuals from 8 varieties. The accuracy achieved through t-SNE dimensionality reduction and K-means clustering was 100%. Furthermore, we used the leave-one-out method to validate the accuracy of our method in predicting variety, and confirmed the reliability of our method in detecting varieties. The package is freely available at https://github.com/Olcat35412/SSR_VibraProfiler .
We introduced SSR_VibraProfiler, a Python package for distinguishing and predicting individual varieties without a reference genome by extracting SSR numerical characteristics from next-generation sequencing data. This tool will contribute to the development, identification, and protection of new varieties.
简单序列重复(SSRs)被广泛用作分子标记;然而,传统的SSR分子标记开发严重依赖实验方法。现代测序技术的进步为直接从测序数据中提取SSR特征并将其用于品种鉴定提供了可能性。
我们开发了一个用于品种鉴定的计算框架,将测序数据中每个SSR的存在与否视为一个数值特征,而忽略特定位点、侧翼序列和出现次数。因此,后续的品种鉴定不依赖实验验证,而是直接基于数值特征矩阵进行。我们使用一个公式来测量这些数值特征在品种内和品种间的方差,并选择表现出品种内特异性和品种间多态性的SSR,形成一个0,1矩阵。我们使用t-SNE(t分布随机邻域嵌入)将矩阵投影到二维平面上,然后对个体进行K均值聚类。通过将聚类标签与真实标签进行比较,初步评估矩阵的分类性能,为其在品种检测中的有效性提供初步评价。最终,我们基于SSR矩阵构建识别模型并将其应用于品种鉴定。该过程已被封装到SSR_VibraProfiler软件包中,该软件包可作为构建SSR品种DNA指纹数据库的工具。我们在一个包含来自8个品种的40个个体的杜鹃花数据集上测试了这个软件包。通过t-SNE降维和K均值聚类实现的准确率为100%。此外,我们使用留一法验证了我们的方法在预测品种方面的准确性,并证实了我们的方法在检测品种方面的可靠性。该软件包可在https://github.com/Olcat35412/SSR_VibraProfiler上免费获取。
我们介绍了SSR_VibraProfiler,这是一个Python软件包,通过从下一代测序数据中提取SSR数值特征来区分和预测个体品种,而无需参考基因组。该工具将有助于新品种的开发、鉴定和保护。