Li Zexi, Yan Chunyi, Cao Ying, Gong Aobo, Li Fanghui, Zeng Rui
Department of Cardiology, West China Hospital, Sichuan University, Chengdu, 610041, Sichuan, China.
Department of Pediatric Cardiology, West China Second University Hospital, Sichuan University, Chengdu, 610041, Sichuan, China.
Sci Rep. 2025 May 30;15(1):19028. doi: 10.1038/s41598-025-04309-5.
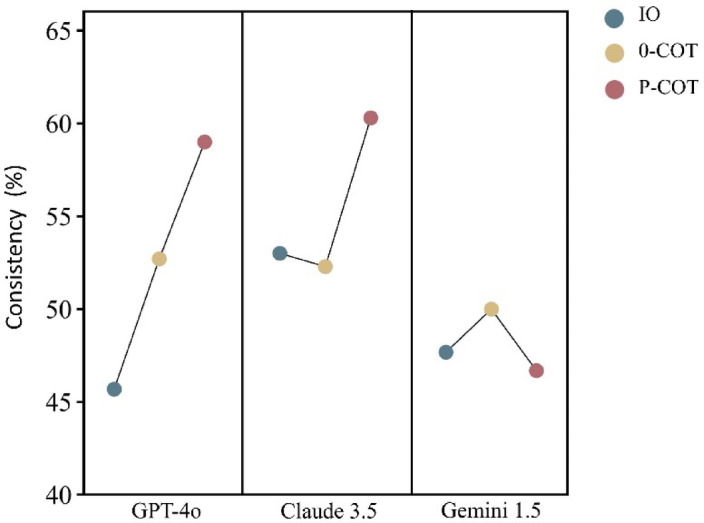
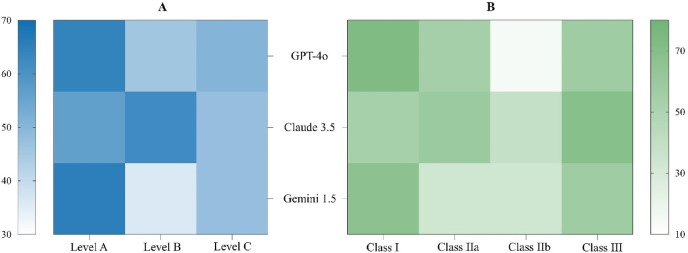
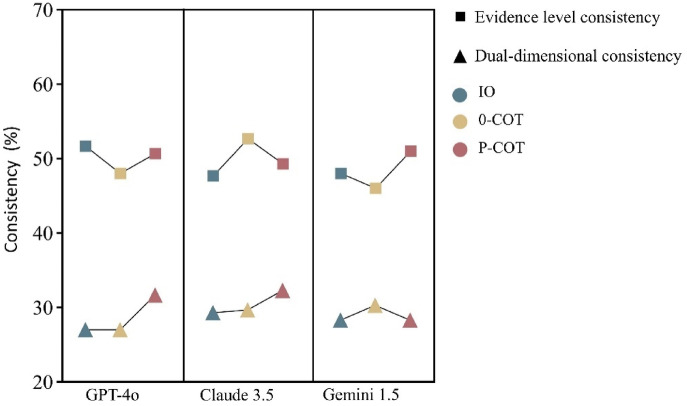
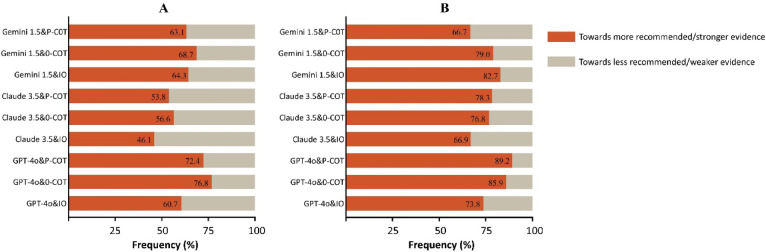
This study evaluated large language models (LLMs) using 30 questions, each derived from a recommendation in the 2024 European Society of Cardiology (ESC) guidelines for atrial fibrillation (AF) management. These recommendations were stratified by class of recommendation and level of evidence. The primary objective was to assess the reliability and consistency of LLM-generated classifications compared to those in the ESC guidelines. Additionally, the study assessed the impact of different prompting strategies and working languages on LLM performance. Three prompting strategies were tested: Input-output (IO), 0-shot-Chain of thought (0-COT) and Performed-Chain of thought (P-COT) prompting. Each question, presented in both English and Chinese, was input into three LLMs: ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro. The reliability of the different LLM-prompt combinations showed moderate to substantial agreement (Fleiss kappa ranged from 0.449 to 0.763). Claude 3.5 with P-COT prompting had the highest recommendation classification consistency (60.3%). No significant differences were observed between English and Chinese across most LLM-prompt combinations. Bias analysis of inconsistent outcomes revealed a propensity towards more recommended treatments and stronger evidence levels across most LLM-prompt combinations. The characteristics of clinical questions potentially influence LLM performance. This study highlights the limitations in the accuracy of LLM responses to AF-related questions. To gather more comprehensive insights, conducting repeated queries is advisable. Future efforts should focus on expanding the use of diverse prompting strategies, conducting ongoing model evaluation and refinement, and establishing a comprehensive, objective benchmarking system.
本研究使用30个问题对大语言模型(LLMs)进行了评估,每个问题均源自2024年欧洲心脏病学会(ESC)心房颤动(AF)管理指南中的一项建议。这些建议按推荐类别和证据水平进行了分层。主要目标是评估大语言模型生成的分类与ESC指南中的分类相比的可靠性和一致性。此外,该研究还评估了不同提示策略和工作语言对大语言模型性能的影响。测试了三种提示策略:输入-输出(IO)、零样本思维链(0-COT)和执行思维链(P-COT)提示。每个问题均以英文和中文呈现,并输入到三个大语言模型中:ChatGPT-4o、Claude 3.5 Sonnet和Gemini 1.5 Pro。不同大语言模型-提示组合的可靠性显示出中度到高度的一致性(Fleiss卡方值范围为0.449至0.763)。采用P-COT提示的Claude 3.5具有最高的推荐分类一致性(60.3%)。在大多数大语言模型-提示组合中,英文和中文之间未观察到显著差异。对不一致结果的偏差分析显示,在大多数大语言模型-提示组合中,倾向于更多推荐的治疗方法和更强的证据水平。临床问题的特征可能会影响大语言模型的性能。本研究突出了大语言模型对AF相关问题回答准确性的局限性。为了获得更全面的见解,建议进行重复查询。未来的工作应侧重于扩大不同提示策略的使用、持续进行模型评估和优化,以及建立一个全面、客观的基准系统。