Jang Hyeong Jun, Song Yun Min, Jeon Jang Su, Yun Hwi-Yeol, Kim Sang Kyum, Kim Jae Kyoung
School of Transdisciplinary Studies, KAIST, Daejeon, Republic of Korea.
Biomedical Mathematics Group, Pioneer Research Center for Mathematical and Computational Sciences, Institute for Basic Science, Daejeon, Republic of Korea.
Nat Commun. 2025 Jun 5;16(1):5217. doi: 10.1038/s41467-025-60468-z.
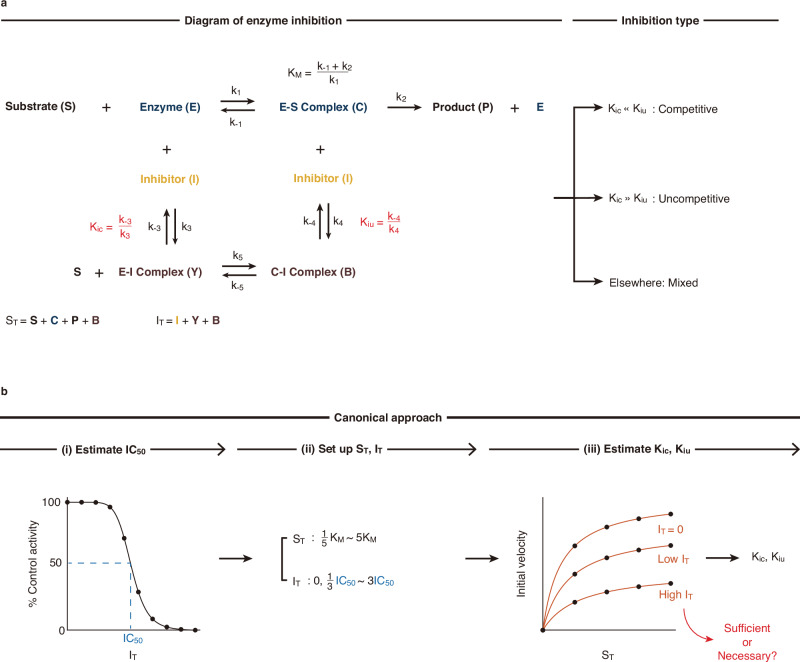
Enzyme inhibition analysis is essential in drug development and food processing, necessitating precise estimation of inhibition constants. Traditionally, these constants are estimated through experiments using multiple substrate and inhibitor concentrations, but inconsistencies across studies highlight a need for a more systematic approach to set experimental designs across all types of enzyme inhibition. Here, we address this by analyzing the error landscape of estimations in various experimental designs. We find that nearly half of the conventional data is dispensable and even introduces bias. Instead, by incorporating the relationship between IC and inhibition constants into the fitting process, we find that using a single inhibitor concentration greater than IC suffices for precise estimation. This IC-based optimal approach, which we name 50-BOA, substantially reduces (>75%) the number of experiments required while ensuring precision and accuracy. Additionally, we provide a user-friendly package that implements the 50-BOA.
酶抑制分析在药物开发和食品加工中至关重要,需要精确估计抑制常数。传统上,这些常数是通过使用多种底物和抑制剂浓度的实验来估计的,但不同研究之间的不一致凸显了需要一种更系统的方法来设置所有类型酶抑制的实验设计。在这里,我们通过分析各种实验设计中估计的误差情况来解决这个问题。我们发现,近一半的传统数据是不必要的,甚至会引入偏差。相反,通过将IC与抑制常数之间的关系纳入拟合过程,我们发现使用单一大于IC的抑制剂浓度就足以进行精确估计。这种基于IC的最优方法,我们称之为50-BOA,在确保精度和准确性的同时,大幅减少(>75%)了所需的实验数量。此外,我们提供了一个实现50-BOA的用户友好型软件包。