Maruyama Hiroki, Toyama Yoshitaka, Takanami Kentaro, Takase Kei, Kamei Takashi
Department of Surgery, Tohoku University Graduate School of Medicine, Sendai, Japan.
Department of Diagnostic Radiology, Tohoku University Hospital, 1-1 Seiryo-Machi, Aoba-Ku, Sendai, Japan, Sendai, 980-8575, Japan, 81 227177312.
JMIR Med Educ. 2025 Jul 30;11:e69313. doi: 10.2196/69313.
Artificial intelligence and large language models (LLMs)-particularly GPT-4 and GPT-4o-have demonstrated high correct-answer rates in medical examinations. GPT-4o has enhanced diagnostic capabilities, advanced image processing, and updated knowledge. Japanese surgeons face critical challenges, including a declining workforce, regional health care disparities, and work-hour-related challenges. Nonetheless, although LLMs could be beneficial in surgical education, no studies have yet assessed GPT-4o's surgical knowledge or its performance in the field of surgery.
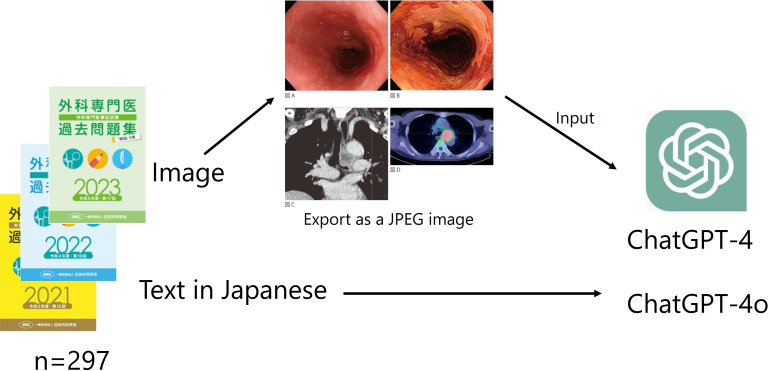
This study aims to evaluate the potential of GPT-4 and GPT-4o in surgical education by using them to take the Japan Surgical Board Examination (JSBE), which includes both textual questions and medical images-such as surgical and computed tomography scans-to comprehensively assess their surgical knowledge.
We used 297 multiple-choice questions from the 2021-2023 JSBEs. The questions were in Japanese, and 104 of them included images. First, the GPT-4 and GPT-4o responses to only the textual questions were collected via OpenAI's application programming interface to evaluate their correct-answer rate. Subsequently, the correct-answer rate of their responses to questions that included images was assessed by inputting both text and images.
The overall correct-answer rates of GPT-4o and GPT-4 for the text-only questions were 78% (231/297) and 55% (163/297), respectively, with GPT-4o outperforming GPT-4 by 23% (P=<.01). By contrast, there was no significant improvement in the correct-answer rate for questions that included images compared with the results for the text-only questions.
GPT-4o outperformed GPT-4 on the JSBE. However, the results of the LLMs were lower than those of the examinees. Despite the capabilities of LLMs, image recognition remains a challenge for them, and their clinical application requires caution owing to the potential inaccuracy of their results.
人工智能和大语言模型(LLMs)——尤其是GPT - 4和GPT - 4o——在医学考试中已展现出较高的正确答案率。GPT - 4o具有增强的诊断能力、先进的图像处理技术以及更新的知识。日本外科医生面临着严峻挑战,包括劳动力减少、地区医疗保健差异以及与工作时长相关的问题。尽管如此,虽然大语言模型在外科教育中可能有益,但尚无研究评估GPT - 4o的外科知识或其在外科领域的表现。
本研究旨在通过让GPT - 4和GPT - 4o参加日本外科医师资格考试(JSBE)来评估它们在外科教育中的潜力,该考试包括文本问题和医学图像(如手术和计算机断层扫描),以全面评估它们的外科知识。
我们使用了2021 - 2023年JSBE中的297道多项选择题。这些问题为日语,其中104道包含图像。首先,通过OpenAI的应用程序编程接口收集GPT - 4和GPT - 4o仅对文本问题的回答,以评估其正确答案率。随后,通过输入文本和图像来评估它们对包含图像问题的回答的正确答案率。
对于仅文本问题,GPT - 4o和GPT - 4的总体正确答案率分别为78%(231/297)和55%(163/297),GPT - 4o比GPT - 4表现好23%(P = <.01)。相比之下,与仅文本问题的结果相比,包含图像问题的正确答案率没有显著提高。
在JSBE中,GPT - 4o的表现优于GPT - 4。然而,大语言模型的结果低于考生。尽管大语言模型有能力,但图像识别对它们来说仍然是一个挑战,并且由于其结果可能不准确,其临床应用需要谨慎。