Bai Zilong, Xu Zihan, Sun Cong, Zang Chengxi, Bunnell H Timothy, Sinfield Catherine, Rutter Jacqueline, Martinez Aaron Thomas, Bailey L Charles, Weiner Mark, Campion Thomas R, Carton Thomas W, Forrest Christopher B, Kaushal Rainu, Wang Fei, Peng Yifan
Population Health Sciences, Weill Cornell Medicine, New York, USA.
Nemours Children's Health, Wilmington, USA.
Npj Health Syst. 2025 Aug 21;2. doi: 10.1038/s44401-025-00033-4.
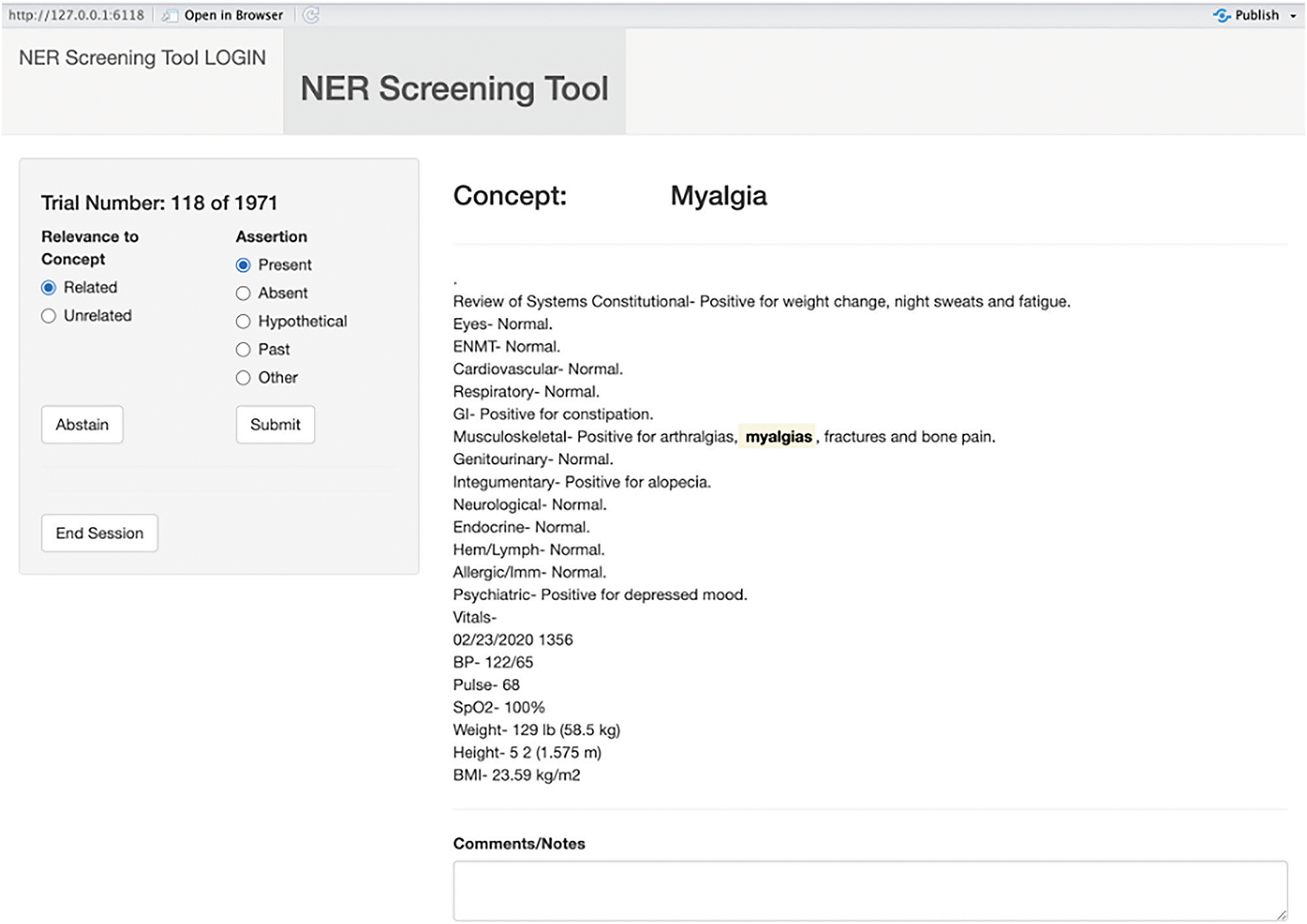
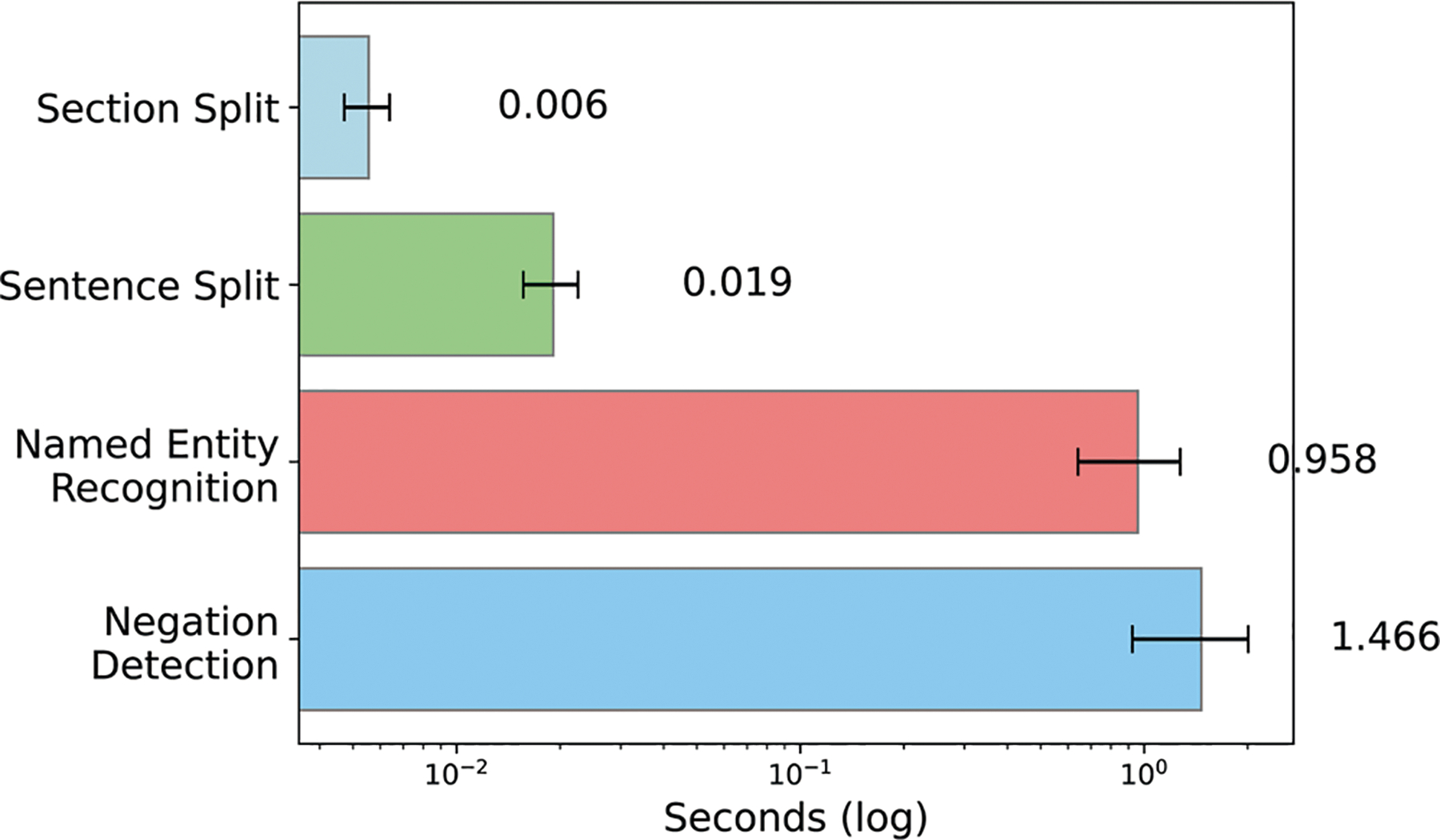
Accurately and efficiently diagnosing Post-Acute Sequelae of COVID-19 (PASC) remains challenging due to its myriad symptoms that evolve over long- and variable-time intervals. To address this issue, we developed a hybrid natural language processing pipeline that integrates rule-based named entity recognition with BERT-based assertion detection modules for PASC-symptom extraction and assertion detection from clinical notes. We developed a comprehensive PASC lexicon with clinical specialists. From 11 health systems of the RECOVER initiative network across the U.S., we curated 160 intake progress notes for model development and evaluation, and collected 47,654 progress notes for a population-level prevalence study. We achieved an average F1 score of 0.82 in one-site internal validation and 0.76 in 10-site external validation for assertion detection. Our pipeline processed each note at 2.448 ± 0.812 seconds on average. Spearman correlation tests showed ρ > 0.83 for positive mentions and ρ > 0.72 for negative ones, both with < 0.0001. These demonstrate the effectiveness and efficiency of our models and its potential for improving PASC diagnosis.
由于新冠后急性后遗症(PASC)症状繁多且会在较长且可变的时间间隔内演变,准确有效地诊断PASC仍然具有挑战性。为解决这一问题,我们开发了一种混合自然语言处理流程,该流程将基于规则的命名实体识别与基于BERT的断言检测模块相结合,用于从临床记录中提取PASC症状并进行断言检测。我们与临床专家共同开发了一个全面的PASC词汇表。从美国RECOVER倡议网络的11个卫生系统中,我们挑选了160份入院进展记录用于模型开发和评估,并收集了47654份进展记录用于人群水平的患病率研究。在单站点内部验证中,我们的断言检测平均F1分数为0.82,在10站点外部验证中为0.76。我们的流程平均每处理一份记录需要2.448±0.812秒。斯皮尔曼相关性检验显示,阳性提及的ρ>0.83,阴性提及的ρ>0.72,两者的p值均<0.0001。这些结果证明了我们模型的有效性和效率及其在改善PASC诊断方面的潜力。