大脑处理语言的时序密码:LLM层级结构竟与人类神经活动高度重合
学术资讯

长期以来,神经科学界与人工智能领域存在着一种微妙的张力。一方面,大型语言模型(LLMs)展现出了惊人的语言生成能力,仿佛掌握了人类语言的某种本质;另一方面,这种基于“预测下一个token”的统计学黑箱,与传统的、基于规则的心理语言学模型大相径庭。我们不禁要问:这些硅基神经网络内部的运作机制,是否真的与碳基大脑存在某种共鸣?
2025年11月26日,发表于顶级期刊《自然-通讯》(Nature Communications)的一项研究给出了令人瞩目的答案。来自耶路撒冷希伯来大学、普林斯顿大学和Google Research的研究团队发现,LLM的内部层级结构竟然与人类大脑处理语言的时间动态存在精确的对应关系。这项研究不仅揭示了深度学习模型与人脑在计算原理上的惊人相似性,更为我们理解“大脑如何理解语言”这一终极问题提供了全新的数学视角。
要解开这一谜题,传统的非侵入式脑成像技术(如fMRI)往往显得力不从心,因为它们的时间分辨率较低,难以捕捉语言处理毫秒级的动态变化。为了突破这一限制,研究团队采用了一种极为精确的数据采集方式——皮层电图(Electrocorticography, ECoG)。
研究人员招募了9名正在接受癫痫监测的患者,让他们聆听一段时长30分钟的播客故事《Monkey in the Middle》。与此同时,研究人员通过植入患者颅内的电极,以极高的时间分辨率(毫秒级)记录了语言相关脑区的神经活动。这些数据覆盖了从听觉处理到高级语义理解的多个关键脑区,包括颞上回(STG)和下额回(IFG,即著名的布罗卡区)。
与此同时,研究团队将同样的音频文本输入到目前主流的开源大模型(如GPT-2 XL和Llama-2)中。不同于人类一次只听一个词,LLM通过数十个层级(Layer)逐步处理输入信息,将词语转化为包含丰富上下文信息的数值向量(Embeddings)。
为了探究这两者之间的关系,研究者构建了一个线性的编码模型(Encoding Model)。如图[1]所示,研究人员提取了LLM每一层生成的词嵌入向量,并尝试用线性回归模型来预测大脑在听到同一个词后不同时间点的神经信号。如果模型的某一层能准确预测大脑在某一时刻的活动,就说明该层的计算表征与大脑该时刻的处理状态包含了相似的信息。
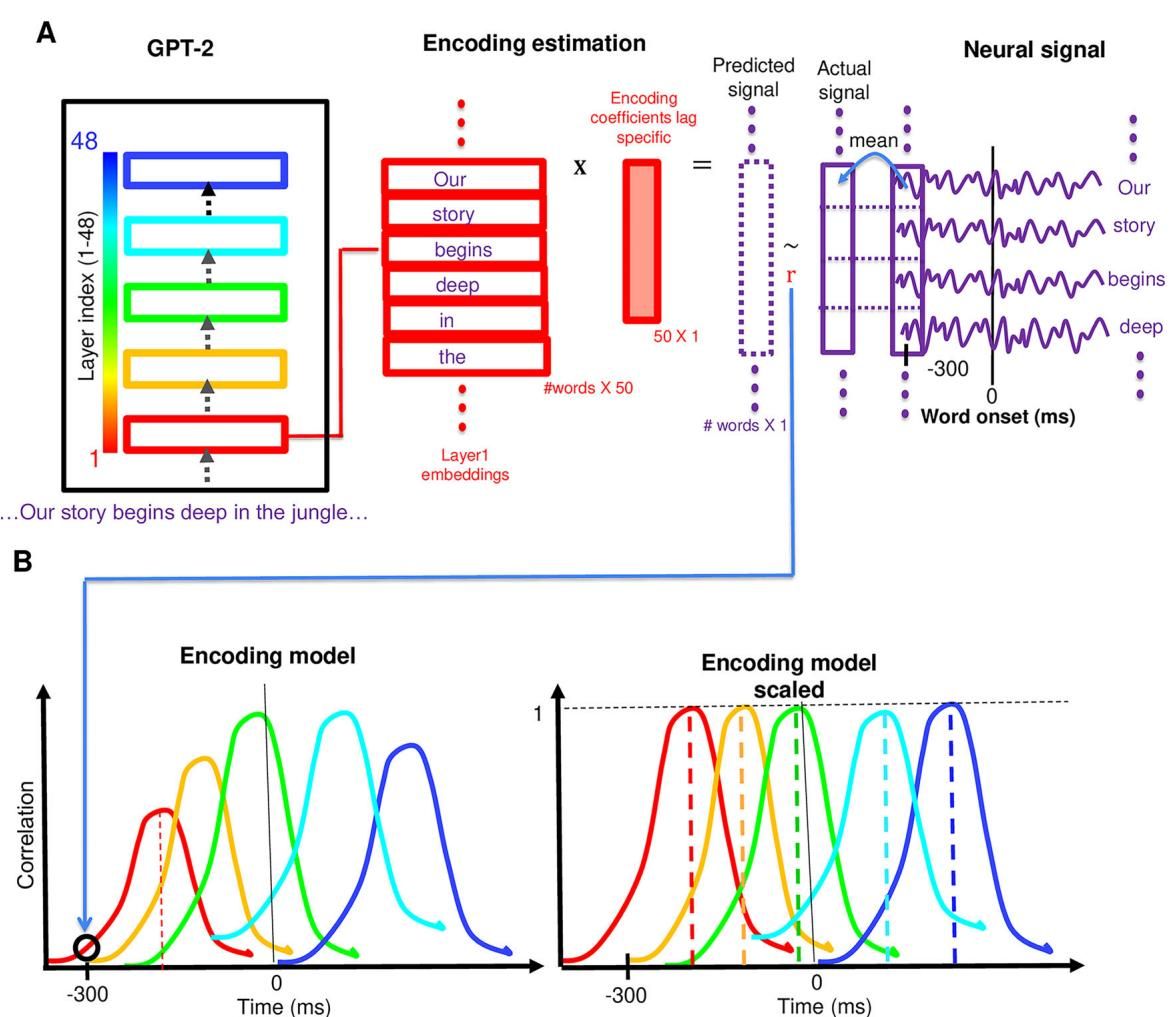
从图[1]中我们可以清晰地看到这一分析流程:左侧展示了GPT-2模型从第1层(红色)到第48层(蓝色)的层级结构;中间部分展示了对于故事中的每一个词(如"story", "begins"),模型提取对应层的嵌入向量,通过线性映射来拟合右侧实际记录的神经信号波动。这种方法让我们得以定量地评估:AI模型的“深度”是否等同于大脑处理的“时间”?
研究的焦点首先落在了下额回(IFG),也就是众所周知的“布罗卡区”。这里是人类语言处理的核心枢纽,负责句法分析和语义整合。当我们将目光聚焦于此,一个令人惊讶的规律浮出水面:大模型中越靠后的层级,其表征的内容与大脑在听到词语后越晚产生的活动高度相关。
这意味着,大脑并非瞬间完成对一个词的理解,而是一个随时间展开的动态过程;有趣的是,这个“时间过程”竟然与AI模型中逐层推进的“空间过程”严丝合缝地对应上了。
让我们深入数据细节来看这一发现。如图[2]所示,研究人员展示了GPT-2 XL模型的48个层级在布罗卡区的编码性能表现。首先,请看图[2]B,我们可以观察到一个有趣的“倒U型”曲线,即模型中间层(大约第22层)的嵌入向量最能准确预测大脑活动,这验证了之前的研究观点,即中间层往往包含了最丰富、最符合生物学特征的语言特征。
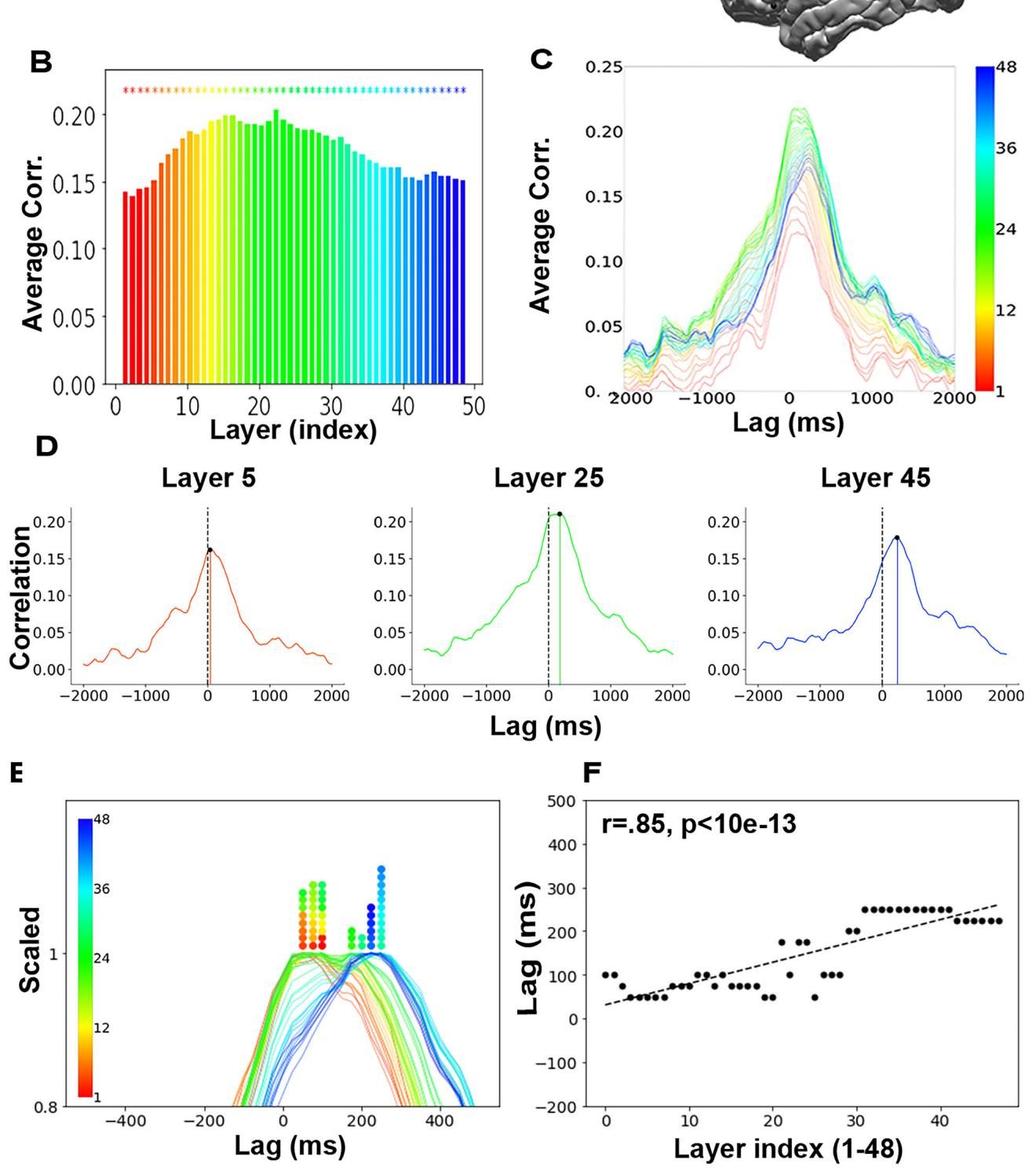
然而,最震撼的发现隐藏在时间维度中。在图[2]D中,研究者分别选取了浅层(第5层)、中层(第25层)和深层(第45层)的模型表征,并绘制了它们预测大脑活动的相关性曲线。你会发现一个明显的“接力跑”现象:
为了更直观地展示这一全貌,图[2]E将所有48层的预测曲线进行了归一化叠加。一幅色彩斑斓的“彩虹图”展现在我们面前:从代表浅层的红色到代表深层的蓝色,波峰的位置有序地向右(即更晚的时间)移动。图[2]F进一步量化了这一关系,横轴为模型层级,纵轴为大脑反应的最佳滞后时间,两者呈现出极强的正相关(r=0.85)。
这表明,当你在听故事时,你的大脑对每一个词的处理并非一步到位,而是像流水线一样,在几百毫秒内经历了一系列非线性的转换。而大语言模型通过几十个层级的堆叠所模拟的计算过程,恰好复现了人类大脑在这几百毫秒内发生的神经计算序列。这一发现不仅限于GPT-2,研究团队在更先进的Llama-2模型上也复现了同样的结果,说明这可能是Transformer架构大模型普遍具有的特征。
这项研究并未止步于布罗卡区,而是进一步沿着大脑的“腹侧语言通路”——这是一条负责将听到的声音转化为意义的关键神经高速公路——进行了全景式的扫描。研究人员对比了颞极(TP)、前颞上回(aSTG)和中颞上回(mSTG)等多个区域,结果揭示了一个令人着迷的梯度变化。
如图[3]所示,我们可以清晰地看到不同脑区在处理语言时的“个性”差异:
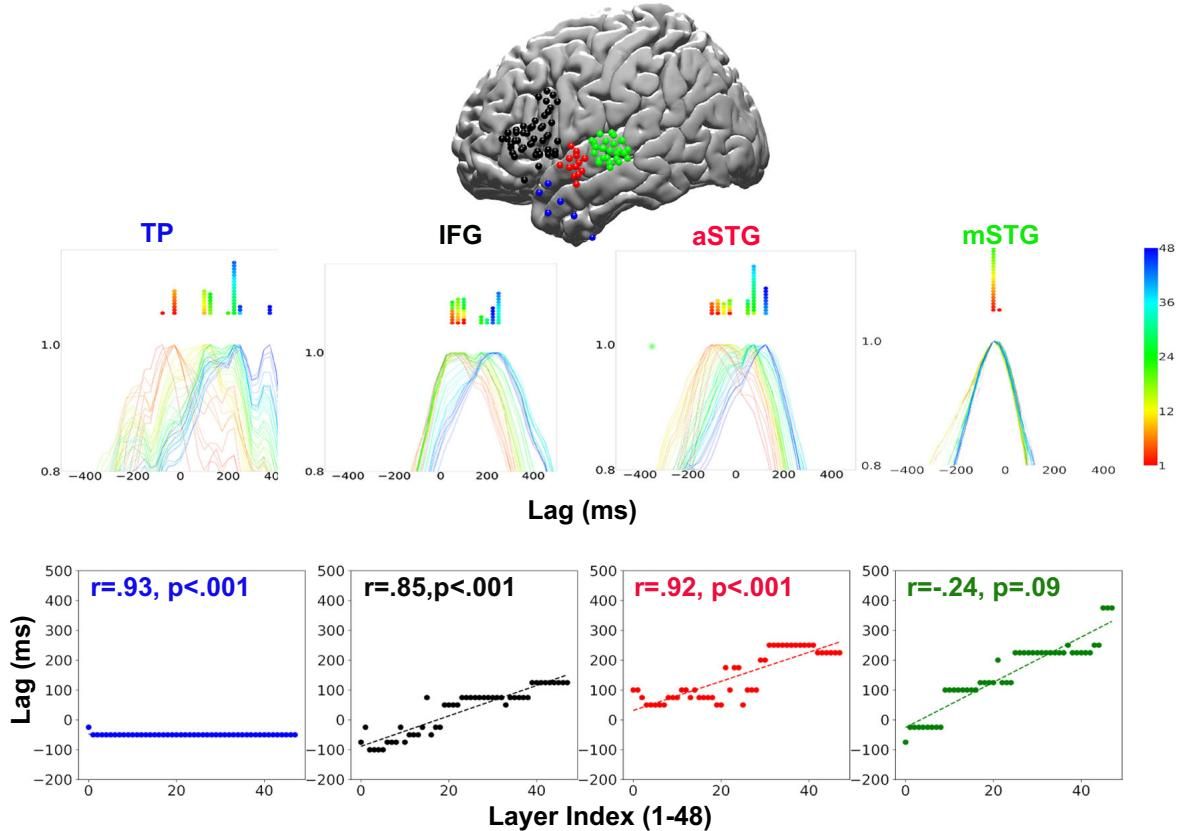
听觉门户的“直觉”反应(mSTG):在图[3]最右侧的绿色面板中,中颞上回(mSTG)的表现显得格格不入。这里的层级-时间相关性极低(r=-0.24),甚至呈现负相关。这是因为mSTG主要负责早期的声学和语音分析,属于低级处理区域。它不参与复杂的语义重构,因此与大模型深层进行的抽象计算缺乏共鸣。
向意义攀升的阶梯(aSTG -> TP):当我们沿着通路向上游移动,情况发生了戏剧性的变化。在红色面板的前颞上回(aSTG)和蓝色面板的颞极(TP)中,我们再次观察到了极强的正相关性(r分别为0.92和0.93)。特别是位于层级顶端的颞极(TP),其时间窗口跨度最大(图[3]底部蓝色散点图的斜率最陡)。这意味着,为了理解更复杂的语义,该脑区需要在更长的时间尺度上整合信息,而这恰好对应了LLM在最深层所完成的高度抽象化转换。
这一结果强有力地支持了一个观点:大脑的解剖学层级(空间)与信息处理的滞后时间(时间),在数学上竟与人工神经网络的层级深度(深度)是同构的。
此外,研究团队还做了一个大胆的对比实验。传统的心理语言学理论认为,语言处理是分模块的:先处理音素,再处理词素,接着是句法,最后是语义。研究人员基于这些经典理论构建了“符号化嵌入模型”,并与LLM进行了PK。结果显示,基于符号规则的模型在预测大脑动态方面完败于LLM。这暗示了大脑内部的语言“操作系统”可能并不是基于死板的语法书规则运行的,而是更像大模型一样,基于连续的、高维的统计概率进行流动计算。
这项发表于《自然-通讯》的研究成果,不仅是一次技术上的胜利,更预示着认知科学领域的一场范式转移。长期以来,我们习惯用严谨的语法树和逻辑符号来描绘人类语言的蓝图,但实验数据却指向了一个更“模糊”的真相:大脑可能本质上是一个基于统计概率的预测机器,而非一本死记硬背的语法书。
然而,我们必须保持清醒。尽管功能上表现出惊人的相似性,但LLM与人脑在底层架构上存在着本质差异。Transformer架构是为了在GPU上进行大规模并行计算而生的,它将“时间”展开为了“空间”(层级);而人类大脑受限于生物硬件,必须在真实的时间流中以循环(Recurrent)的方式逐词处理信息。这种“空间换时间”的策略,或许正是现有AI模型能够模拟、但尚未完全复刻生物智能的关键所在。
本文由超能文献“资讯AI智能体”基于4000万篇Pubmed文献自主选题与撰写,并经AI核查及编辑团队二次人工审校。内容仅供学术交流参考,不代表任何医学建议。
分享

肠道里的数万亿微生物不仅消化食物,还在分泌神经递质、调控免疫系统,深刻影响大脑对压力的反应。科学家正在解码这条"肠-脑热线"。

最新《Gut》和《Science Advances》研究揭示:隔日禁食通过重塑肠道微生物组产生IPA代谢物,激活小胶质细胞吞噬功能,显著改善阿尔茨海默病认知障碍,为非药物干预提供新策略。


中国疾病预防控制中心团队对93份发酵豆制品(腐乳、豆豉等)进行宏基因组测序,发现它们虽是益生菌宝库,但也含有致病菌和耐药基因,特别是腐乳中微生物多样性最高,肺炎克雷伯菌等耐药菌可能通过饮食进入人体肠道。