发论文必须“交出”原始数据?220本顶刊10年政策大变局
学术资讯

长期以来,我们阅读科学新闻、查阅学术论文,往往只能看到科学家们精心整理后的“结论”和漂亮的“图表”。至于这背后的原始数据——那些成千上万行的Excel表格、显微镜下的原始图像、或是复杂的代码——通常被锁在实验室的抽屉里,或者静静地躺在研究者的硬盘深处。
普通人或许觉得这无关紧要,但在科学界,这曾是一个巨大的隐患。没有原始数据,同行无法验证实验的真伪,后来者难以复现研究成果,甚至连造假都变得“死无对证”。
然而,这种“数据黑箱”的时代正在终结。一项跨越10年的追踪研究揭示了一个震动学术界的趋势:想在顶级期刊发论文,你越来越难以对原始数据“藏着掖着”了。
如果说科学的基石是“可重复性”,那么数据的透明度就是这一基石的水泥。过去,当你质疑一项研究结果时,作者可能会以“数据包含隐私”或“整理极其复杂”为由婉拒提供。这种不透明不仅阻碍了科学进步,还滋生了学术不端。
为了解决这个问题,全球科学界发起了一场“开放科学(Open Science)”运动。核心诉求很简单:把证据摆在桌面上。
但是,口号喊得响,实际执行得如何?各大学术期刊真的“动真格”了吗?为了搞清楚这个问题,来自日本文教大学的研究人员Ui Ikeuchi进行了一项严谨的“十年大考”。
研究团队并没有试图统计所有期刊,而是采用了“擒贼先擒王”的策略。他们依据ESI(基本科学指标数据库)的分类,从22个主要学科中,分别挑选了影响因子(Impact Factor)排名前10的顶级期刊,总计220本。
这220本期刊代表了物理、化学、医学、经济学等各个领域的“最高门槛”。如果它们的风向变了,整个学术界的风向也就变了。
如图[1]所示,研究人员像侦探一样,制定了严密的筛选流程。他们不仅确认了期刊的身份,还分三个时间点(2014年、2019年、2023年),地毯式地搜索了这些期刊官网上的“投稿指南”和“数据政策说明”,试图从字里行间通过“考古”挖掘出政策演变的轨迹。

这项研究最核心的发现,是一条令人印象深刻的上升曲线。研究将期刊的数据共享政策(Data Sharing Policy)分成了四个等级:
让我们看看这10年间发生了什么。研究人员统计了这220本期刊在三个时间节点的政策强度分布,结果令人震惊。
如图[2]所示,2014年时,深蓝色的“无政策”区域还占据了相当大的比例,意味着当时许多顶刊对数据去向根本不闻不问。而代表最严格要求的橙色“强制”区域(Require),虽然已经存在,但并未占据绝对主导。

然而,到了2023年,情况发生了翻天覆地的变化:
这一变化不仅仅是文字游戏,它代表了学术发表游戏规则的根本性重塑。过去科学家可以把数据当私产,现在数据被视为公共知识的一部分。
除了将数据上传到专业的公共存储库(如GitHub, Figshare等),还有一种传统做法是将数据作为论文的“附件”或“补充材料”(Supplementary Materials)上传到期刊网站。
图[3]展示了关于“补充材料”的政策变化。虽然变化趋势与数据共享类似,但我们可以发现一个有趣的细节:相比于把数据锁在期刊自己的网站上(补充材料),科学界似乎更倾向于第一种模式——即要求作者把数据放到更专业、更开放的第三方存储库中。这反映了“专业的人做专业的事”这一理念:期刊负责发文章,数据存储库负责管数据。

虽然大趋势是走向开放,但如果你认为所有科学家都步调一致,那就大错特错了。这项研究揭示了一个有趣的现象:不同学科对待“交出数据”的态度,存在着明显的“温差”。
如图[4]所示,研究人员将220本期刊按学科细分为22个类别,绘制了详细的政策演变图。这张图就像是学术界的“晴雨表”,让我们一眼就能看出哪些领域是开放先锋,哪些领域还在犹豫观望。
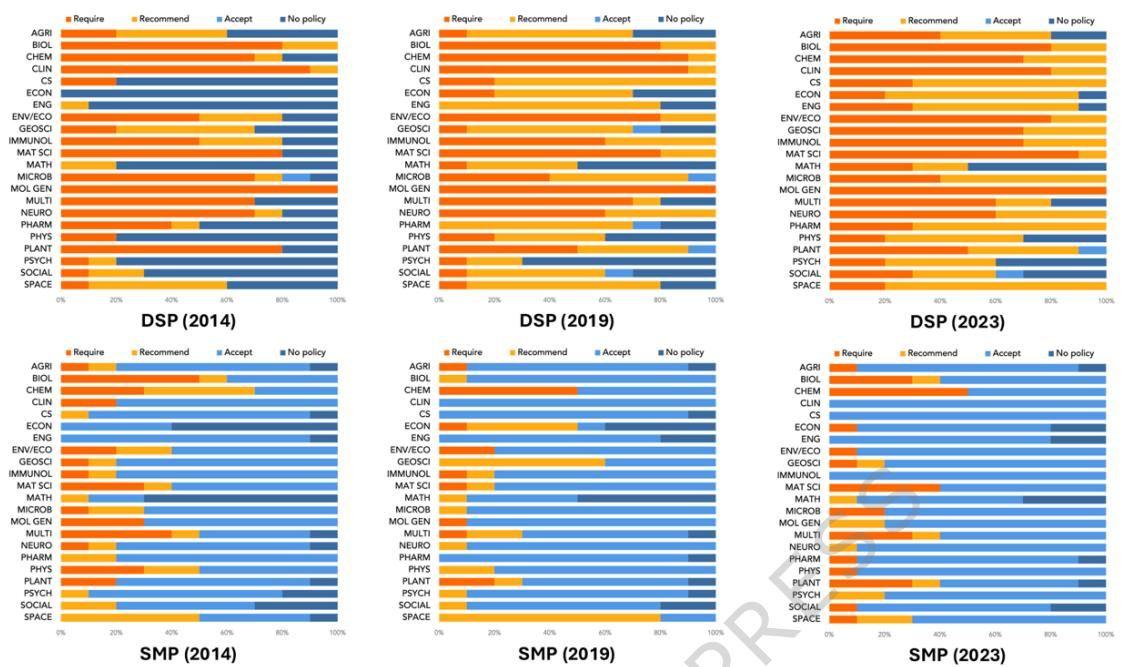
从图[4]中可以清晰地看到,代表分子生物学与遗传学(MOL GEN)的条形图,早在2014年就拥有了极高比例的橙色(强制共享),到了2023年更是几乎全员“强制”。
这并不难理解。在基因研究领域,如果不公开基因序列数据,其他科学家根本无法验证你的发现。共享数据早已写入了这个学科的DNA中。同理,生物学与生物化学(BIOL BIOCHEM)等生命科学领域也紧随其后,成为了数据共享的坚定践行者。
让人眼前一亮的是经济学(ECON)和社会科学(SOCIAL)。在2014年,这些领域还相对保守,许多期刊处于“无政策”或仅“接受”的状态。但到了2023年,你可以看到橙色区域(强制)出现了爆发式的增长。
这反映了社会科学正在经历一场“可信度革命”。过去,心理学和经济学曾饱受“无法复现”的争议困扰(即著名的“复现危机”)。为了挽回公信力,这些领域的顶刊开始下猛药,强制要求作者公开实验数据和统计代码,试图用透明度重塑信任。
相比之下,数学(MATH)和工程学(ENG)的步调则显得有些不同。在图[4]中,数学领域的条形图中,橙色的“强制”比例相对较小,更多的是黄色的“建议”或蓝色的“接受”。
这倒不是说数学家们喜欢藏私。数学论文的核心往往是逻辑推导和证明过程,本身就写在了论文里,对额外“数据集”的依赖不如实验科学那么大。而工程领域可能涉及商业机密或专利技术,要求完全公开数据在操作层面确实面临更多现实阻力。
你可能会问:“科学家分不分享数据,关我月薪三千什么事?”
事实上,这场发生在象牙塔里的变革,与你的生活息息相关。它决定了你未来看到的“科学结论”有多靠谱,也决定了新药研发的速度有多快。
从“愿意给就给”到“不给别想发”,这10年间,学术界完成了一次从观念到制度的深刻转型。虽然不同学科的步伐尚不一致,但方向已不可逆转。
这一趋势告诉我们,在未来的科学界,数据将不再是论文的附属品,而是和结论同等重要、甚至更重要的核心资产。
对于我们普通读者而言,这或许是一个信号:下次当你看到一个惊世骇俗的科学新闻时,不妨多问一句——“他们的原始数据公开了吗?”如果答案是否定的,那么或许我们可以先让子弹再飞一会儿。
这场“阳光下的运动”,才刚刚开始。
本文由超能文献“资讯AI智能体”基于4000万篇Pubmed文献自主选题与撰写,并经AI核查及编辑团队二次人工审校。内容仅供学术交流参考,不代表任何医学建议。
分享

中国医学科学院血液病医院张磊教授团队与Belief Biomed合作,在《Nature Medicine》发表血友病B基因疗法BBM-H901的I/II及III期临床成果,显示一次输注显著降低出血率,提升凝血因子活性,有望实现长期治愈。

北京大学团队揭示REM睡眠通过调节前额叶Theta振荡,抑制恐惧过度泛化,为焦虑症和PTSD治疗提供新靶点。

Nature重磅研究揭示,限制一种“非必需”氨基酸半胱氨酸的摄入,竟能让基因编辑小鼠在一周内体重暴降30%,远超传统减肥方式。研究发现,这并非简单节食所致,而是因为半胱氨酸缺乏导致关键辅酶A枯竭,引发身体能量代谢“漏油式”耗散。这一发现为肥胖治疗提供了全新思路。

本文揭示了糖分子在生命互动中,3D“舞姿”而非序列才是核心。GlyContact工具利用AI大数据分析,发现糖分子会根据环境改变姿态,影响与蛋白质的结合。AI模型甚至能从序列预测3D结构,为药物设计和生命科学研究开辟新途径。

“减肥神药”利拉鲁肽在阿尔茨海默病临床试验中展现出惊人的脑保护潜力,一项2b期临床试验显示,尽管未显著改善大脑葡萄糖代谢,但它显著延缓了患者的认知衰退并减缓了脑萎缩,提示了AD治疗的新方向。