Terwilliger Thomas C
Los Alamos National Laboratory, Los Alamos, NM 87545, USA.
Acta Crystallogr D Biol Crystallogr. 2003 Jan;59(Pt 1):38-44. doi: 10.1107/s0907444902018036. Epub 2002 Dec 19.
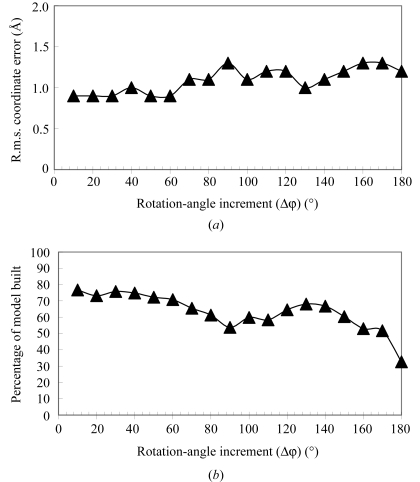
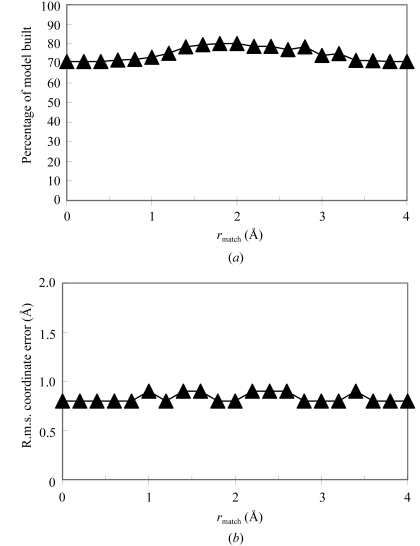
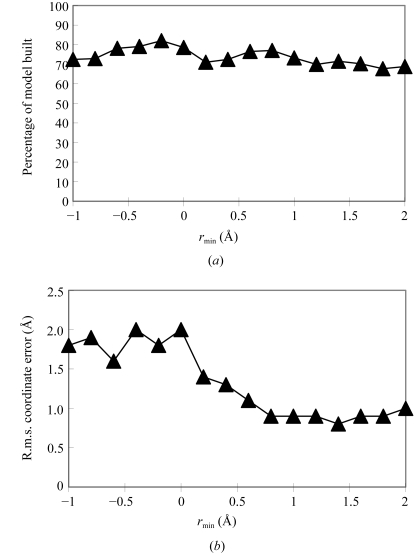
An algorithm for the automated macromolecular model building of polypeptide backbones is described. The procedure is hierarchical. In the initial stages, many overlapping polypeptide fragments are built. In subsequent stages, the fragments are extended and then connected. Identification of the locations of helical and beta-strand regions is carried out by FFT-based template matching. Fragment libraries of helices and beta-strands from refined protein structures are then positioned at the potential locations of helices and strands and the longest segments that fit the electron-density map are chosen. The helices and strands are then extended using fragment libraries consisting of sequences three amino acids long derived from refined protein structures. The resulting segments of polypeptide chain are then connected by choosing those which overlap at two or more C(alpha) positions. The fully automated procedure has been implemented in RESOLVE and is capable of model building at resolutions as low as 3.5 A. The algorithm is useful for building a preliminary main-chain model that can serve as a basis for refinement and side-chain addition.
本文描述了一种用于自动构建多肽主链大分子模型的算法。该过程是分层的。在初始阶段,构建许多重叠的多肽片段。在后续阶段,片段被延伸然后连接。通过基于快速傅里叶变换(FFT)的模板匹配来识别螺旋和β链区域的位置。然后将来自精制蛋白质结构的螺旋和β链片段库定位在螺旋和链的潜在位置,并选择与电子密度图匹配的最长片段。接着使用由来自精制蛋白质结构的三个氨基酸长的序列组成的片段库来延伸螺旋和链。然后通过选择在两个或更多α碳原子位置重叠的片段来连接所得的多肽链段。这个完全自动化的过程已在RESOLVE中实现,并且能够在低至3.5埃的分辨率下进行模型构建。该算法对于构建初步的主链模型很有用,该模型可作为精制和添加侧链的基础。