Konishi Tomokazu
Faculty of Bioresource Sciences, Akita Prefectural University, Akita 010-0195, Japan.
BMC Bioinformatics. 2004 Jan 13;5:5. doi: 10.1186/1471-2105-5-5.
To cancel experimental variations, microarray data must be normalized prior to analysis. Where an appropriate model for statistical data distribution is available, a parametric method can normalize a group of data sets that have common distributions. Although such models have been proposed for microarray data, they have not always fit the distribution of real data and thus have been inappropriate for normalization. Consequently, microarray data in most cases have been normalized with non-parametric methods that adjust data in a pair-wise manner. However, data analysis and the integration of resultant knowledge among experiments have been difficult, since such normalization concepts lack a universal standard.
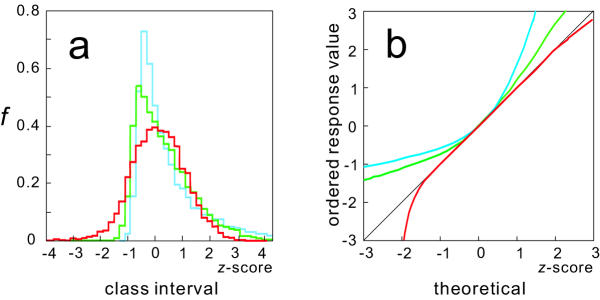
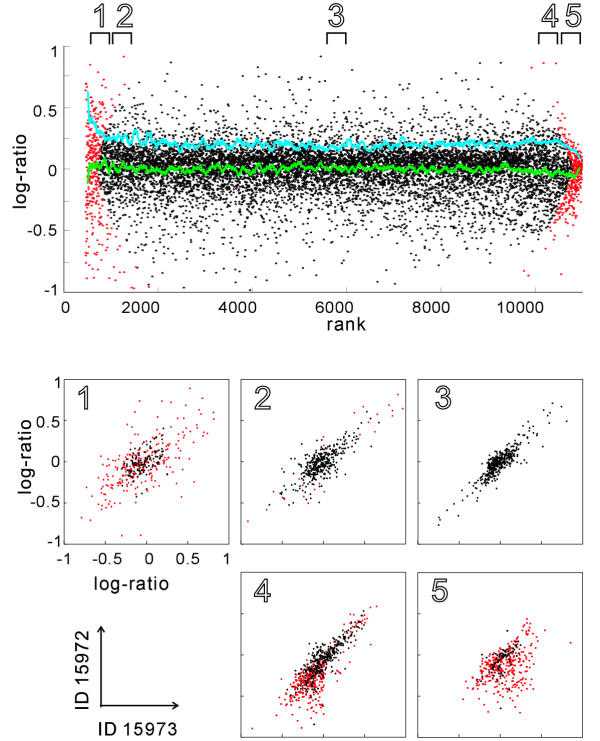
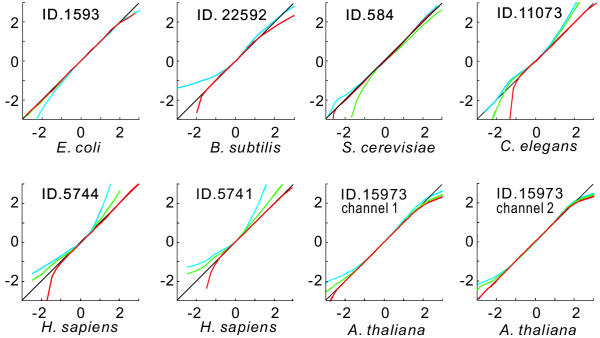
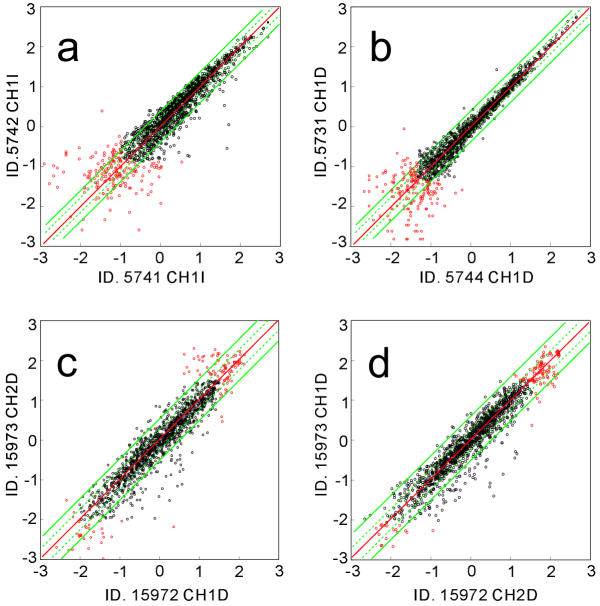
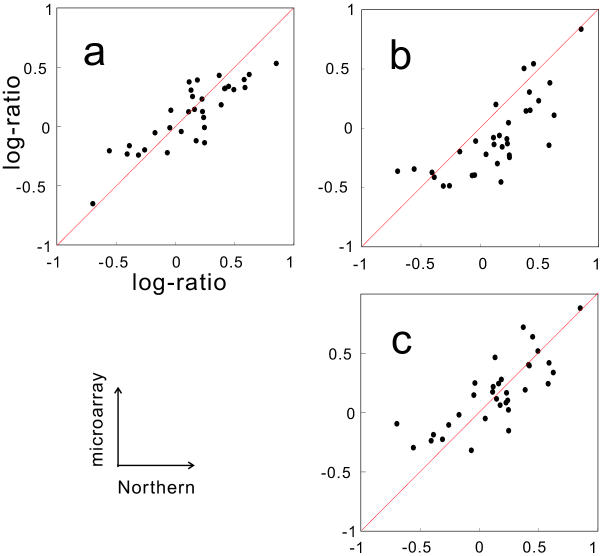
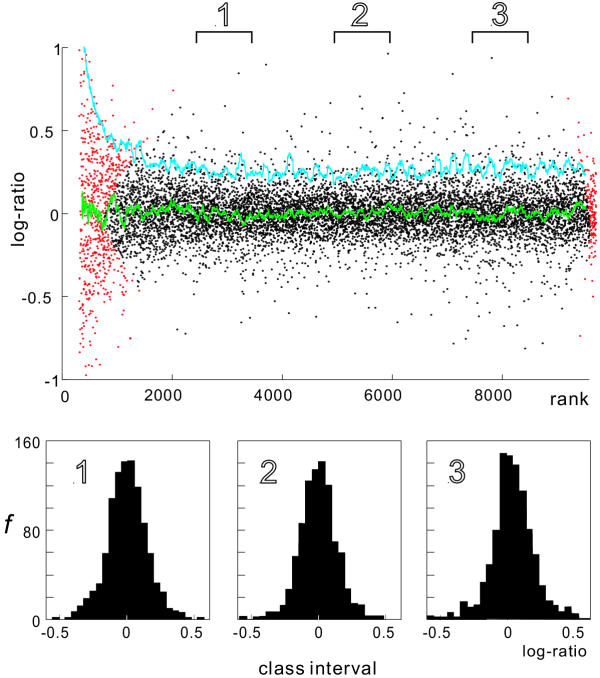
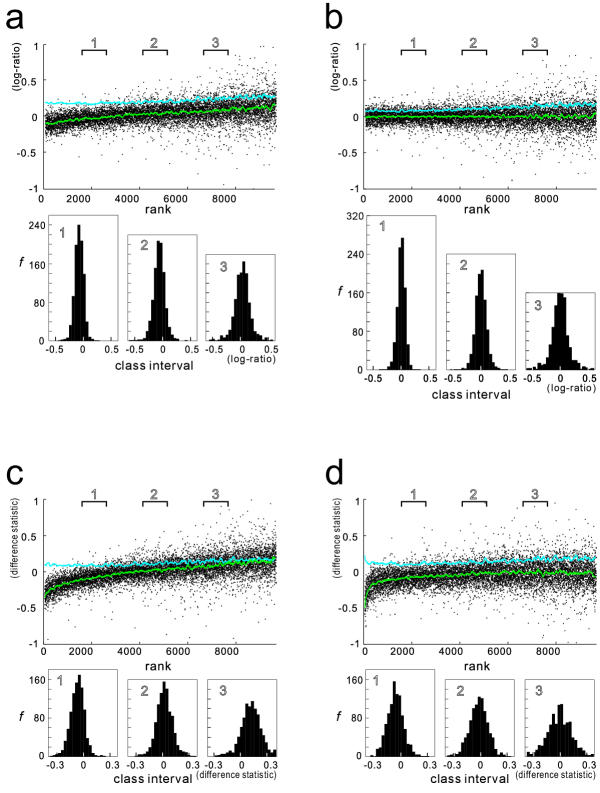
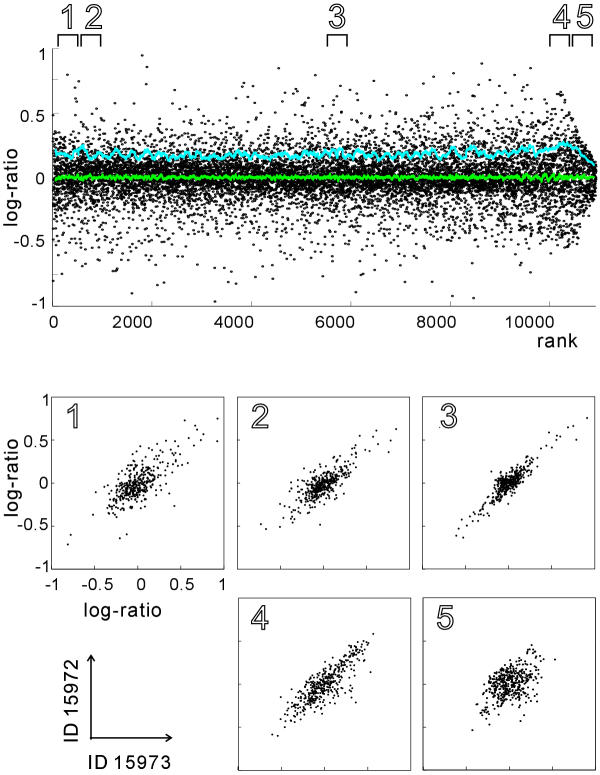
A three-parameter lognormal distribution model was tested on over 300 sets of microarray data. The model treats the hybridization background, which is difficult to identify from images of hybridization, as one of the parameters. A rigorous coincidence of the model to data sets was found, proving the model's appropriateness for microarray data. In fact, a closer fitting to Northern analysis was obtained. The model showed inconsistency only at very strong or weak data intensities. Measurement of z-scores as well as calculated ratios was reproducible only among data in the model-consistent intensity range; also, the ratios were independent of signal intensity at the corresponding range.
The model could provide a universal standard for data, simplifying data analysis and knowledge integration. It was deduced that the ranges of inconsistency were caused by experimental errors or additive noise in the data; therefore, excluding the data corresponding to those marginal ranges will prevent misleading analytical conclusions.
为消除实验差异,微阵列数据在分析前必须进行标准化处理。当存在适用于统计数据分布的模型时,参数化方法可对具有共同分布的一组数据集进行标准化。尽管已针对微阵列数据提出了此类模型,但它们并不总是能拟合实际数据的分布,因此不适用于标准化处理。因此,在大多数情况下,微阵列数据已采用以成对方式调整数据的非参数方法进行标准化。然而,由于此类标准化概念缺乏通用标准,数据分析以及实验间所得知识的整合一直很困难。
在300多组微阵列数据上测试了三参数对数正态分布模型。该模型将难以从杂交图像中识别的杂交背景视为参数之一。发现该模型与数据集高度吻合,证明了该模型适用于微阵列数据。实际上,与Northern分析的拟合度更高。该模型仅在数据强度非常强或非常弱时表现出不一致。z分数的测量以及计算出的比率仅在模型一致的强度范围内的数据之间是可重复的;此外,在相应范围内,比率与信号强度无关。
该模型可为数据提供通用标准,简化数据分析和知识整合。据推断,不一致的范围是由实验误差或数据中的加性噪声引起的;因此,排除与那些边缘范围相对应的数据将防止得出误导性的分析结论。