Meereis Florian, Kaufmann Michael
The Protein Chemistry Group, Institute of Neurobiochemistry, Witten/Herdecke University, Stockumer Str. 10, 58448 Witten, Germany.
BMC Bioinformatics. 2004 Oct 15;5:150. doi: 10.1186/1471-2105-5-150.
The rapidly increasing number of completely sequenced genomes led to the establishment of the COG-database which, based on sequence homologies, assigns similar proteins from different organisms to clusters of orthologous groups (COGs). There are several bioinformatic studies that made use of this database to determine (hyper)thermophile-specific proteins by searching for COGs containing (almost) exclusively proteins from (hyper)thermophilic genomes. However, public software to perform individually definable group-specific searches is not available.
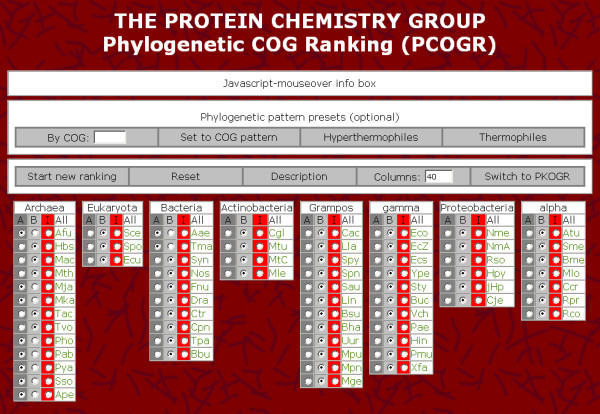
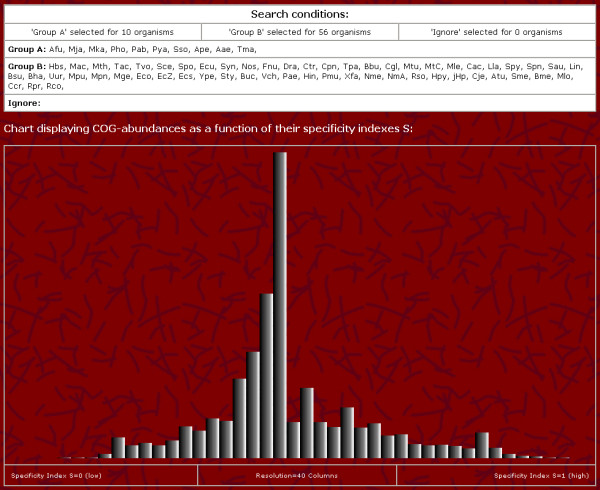
The tool described here exactly fills this gap. The software is accessible at http://www.uni-wh.de/pcogr and is linked to the COG-database. The user can freely define two groups of organisms by selecting for each of the (current) 66 organisms to belong either to groupA, to the reference groupB or to be ignored by the algorithm. Then, for all COGs a specificity index is calculated with respect to the specificity to groupA, i. e. high scoring COGs contain proteins from the most of groupA organisms while proteins from the most organisms assigned to groupB are absent. In addition to ranking all COGs according to the user defined specificity criteria, a graphical visualization shows the distribution of all COGs by displaying their abundance as a function of their specificity indexes.
This software allows detecting COGs specific to a predefined group of organisms. All COGs are ranked in the order of their specificity and a graphical visualization allows recognizing (i) the presence and abundance of such COGs and (ii) the phylogenetic relationship between groupA- and groupB-organisms. The software also allows detecting putative protein-protein interactions, novel enzymes involved in only partially known biochemical pathways, and alternate enzymes originated by convergent evolution.
全基因组测序数量的迅速增加促成了COG数据库的建立,该数据库基于序列同源性,将来自不同生物体的相似蛋白质归入直系同源群(COG)。有多项生物信息学研究利用该数据库,通过搜索那些(几乎)只包含来自嗜热(超嗜热)基因组蛋白质的COG,来确定嗜热(超嗜热)菌特异性蛋白质。然而,目前尚无能够进行用户自定义的特定群组搜索的公共软件。
该软件能够检测特定预定义生物体组特有的COG。所有COG均按其特异性排序,图形化可视化有助于识别(i)此类COG的存在及丰度,以及(ii)A组和B组生物体之间的系统发育关系。该软件还能够检测假定的蛋白质 - 蛋白质相互作用、参与部分已知生化途径的新型酶,以及由趋同进化产生的替代酶。