Meereis Florian, Kaufmann Michael
The Protein Chemistry Group, Witten/Herdecke University, Stockumer Str, 10, 58448 Witten, Germany.
BMC Bioinformatics. 2008 Nov 13;9:479. doi: 10.1186/1471-2105-9-479.
The current versions of the COG and arCOG databases, both excellent frameworks for studies in comparative and functional genomics, do not contain the nucleotide sequences corresponding to their protein or protein domain entries.
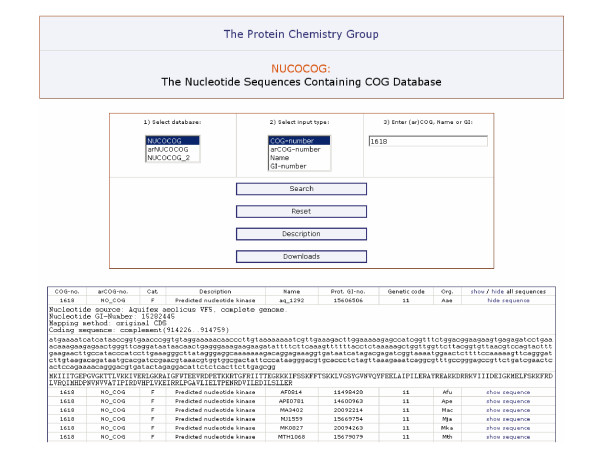
Using sequence information obtained from GenBank flat files covering the completely sequenced genomes of the COG and arCOG databases, we constructed NUCOCOG (nucleotide sequences containing COG databases) as an extended version including all nucleotide sequences and in addition the amino acid sequences originally utilized to construct the current COG and arCOG databases. We make available three comprehensive single XML files containing the complete databases including all sequence information. In addition, we provide a web interface as a utility suitable to browse the NUCOCOG database for sequence retrieval. The database is accessible at http://www.uni-wh.de/nucocog.
NUCOCOG offers the possibility to analyze any sequence related property in the context of the COG and arCOG framework simply by using script languages such as PERL applied to a large but single XML document.
目前版本的COG和arCOG数据库都是比较基因组学和功能基因组学研究的优秀框架,但不包含与其蛋白质或蛋白质结构域条目相对应的核苷酸序列。
利用从GenBank平面文件中获得的序列信息,这些文件涵盖了COG和arCOG数据库的完全测序基因组,我们构建了NUCOCOG(包含COG数据库的核苷酸序列)作为一个扩展版本,包括所有核苷酸序列以及最初用于构建当前COG和arCOG数据库的氨基酸序列。我们提供了三个全面的单个XML文件,其中包含完整的数据库以及所有序列信息。此外,我们提供了一个网络界面,作为一个适合浏览NUCOCOG数据库进行序列检索的实用工具。该数据库可在http://www.uni-wh.de/nucocog上访问。
NUCOCOG提供了一种可能性,即只需使用诸如PERL之类的脚本语言应用于一个大的但单个的XML文档,就可以在COG和arCOG框架的背景下分析任何与序列相关的属性。