Cohen A M, Hersh W R, Dubay C, Spackman K
Department of Medical Informatics and Clinical Epidemiology, School of Medicine, Oregon Health & Science University, 3181 S,W, Sam Jackson Park Road, Portland, Oregon 97239-3098, USA.
BMC Bioinformatics. 2005 Apr 22;6:103. doi: 10.1186/1471-2105-6-103.
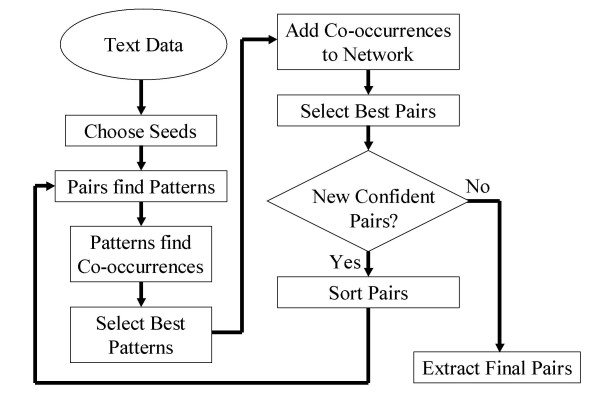
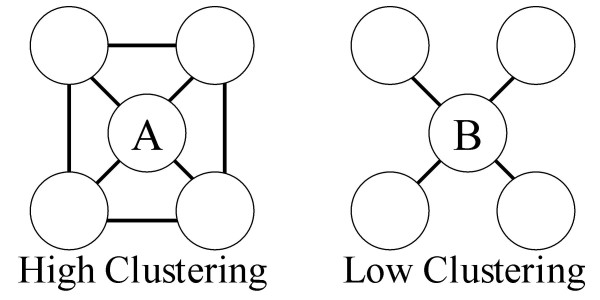
Text-mining can assist biomedical researchers in reducing information overload by extracting useful knowledge from large collections of text. We developed a novel text-mining method based on analyzing the network structure created by symbol co-occurrences as a way to extend the capabilities of knowledge extraction. The method was applied to the task of automatic gene and protein name synonym extraction.
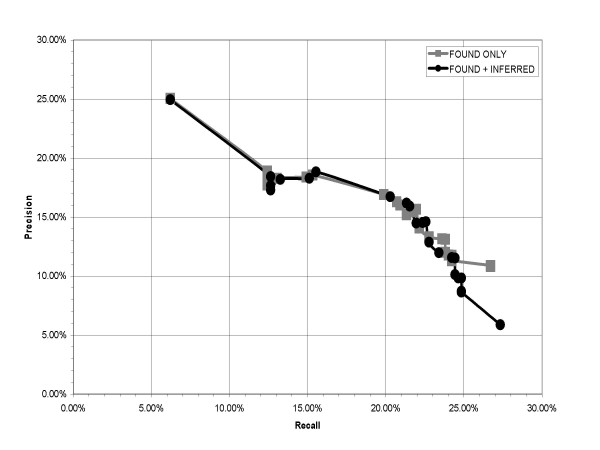
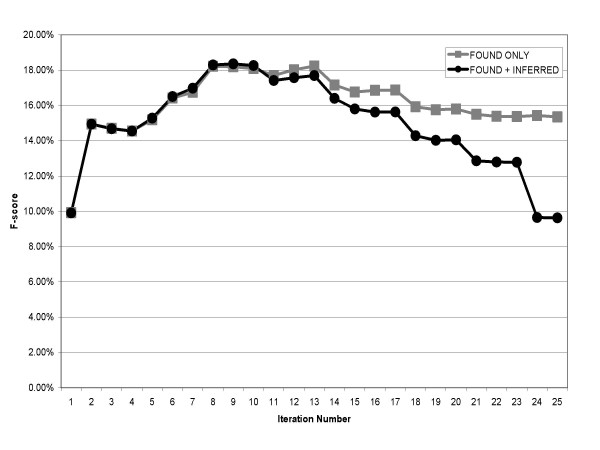
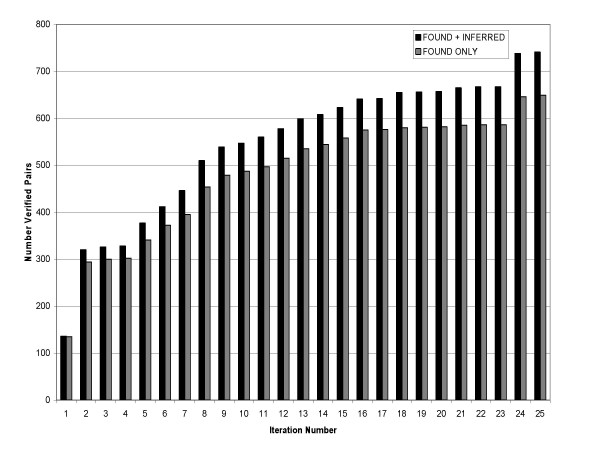
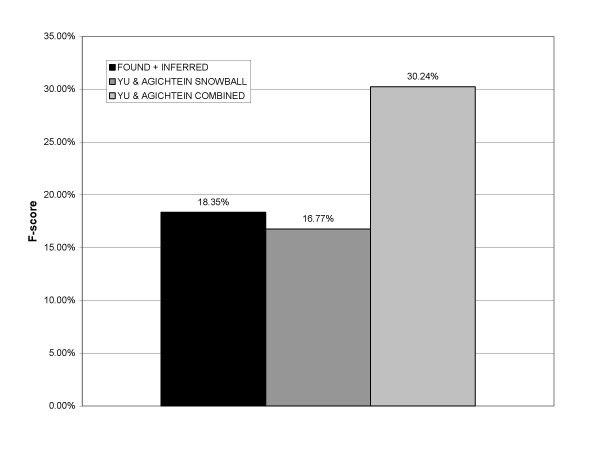
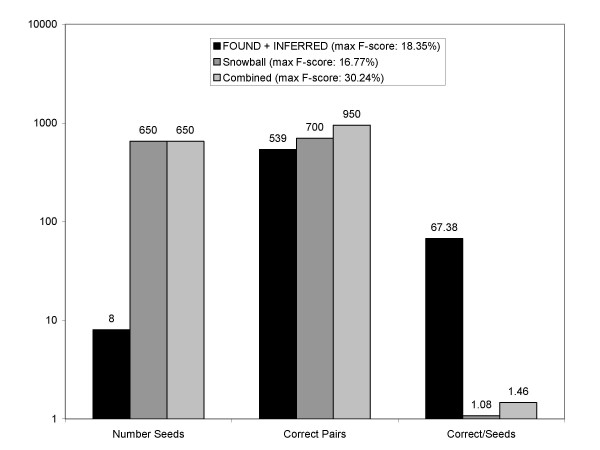
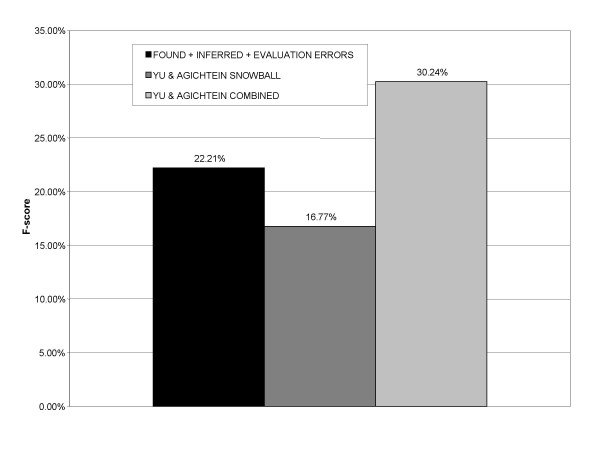
Performance was measured on a test set consisting of about 50,000 abstracts from one year of MEDLINE. Synonyms retrieved from curated genomics databases were used as a gold standard. The system obtained a maximum F-score of 22.21% (23.18% precision and 21.36% recall), with high efficiency in the use of seed pairs.
The method performs comparably with other studied methods, does not rely on sophisticated named-entity recognition, and requires little initial seed knowledge.
文本挖掘可通过从大量文本集合中提取有用知识,帮助生物医学研究人员减轻信息过载。我们基于分析符号共现所创建的网络结构,开发了一种新颖的文本挖掘方法,以此扩展知识提取的能力。该方法应用于自动基因和蛋白质名称同义词提取任务。
在一个由约50,000篇来自一年的MEDLINE摘要组成的测试集上进行性能评估。从经过整理的基因组学数据库中检索到的同义词用作黄金标准。该系统获得了22.21%的最高F值(精确率为23.18%,召回率为21.36%),在种子对的使用上效率较高。
该方法与其他研究方法表现相当,不依赖复杂的命名实体识别,且所需的初始种子知识较少。