Hu Zihua, Willsky Gail R
Center for Computational Research, Department of Biostatistics, University at Buffalo, Buffalo, NY 14260, USA.
BMC Bioinformatics. 2006 Jan 10;7:12. doi: 10.1186/1471-2105-7-12.
The choice of probe set algorithms for expression summary in a GeneChip study has a great impact on subsequent gene expression data analysis. Spiked-in cRNAs with known concentration are often used to assess the relative performance of probe set algorithms. Given the fact that the spiked-in cRNAs do not represent endogenously expressed genes in experiments, it becomes increasingly important to have methods to study whether a particular probe set algorithm is more appropriate for a specific dataset, without using such external reference data.
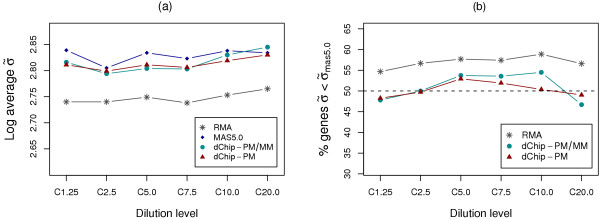
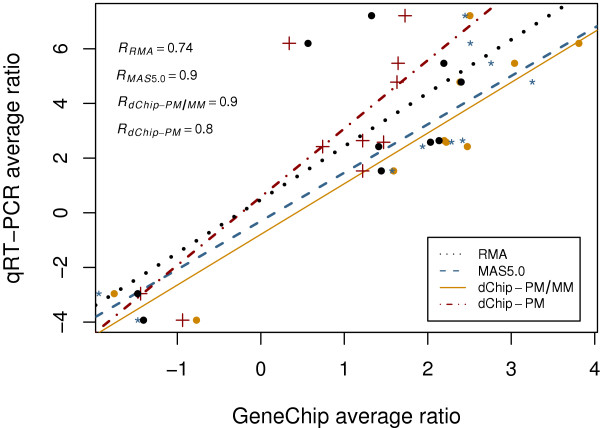
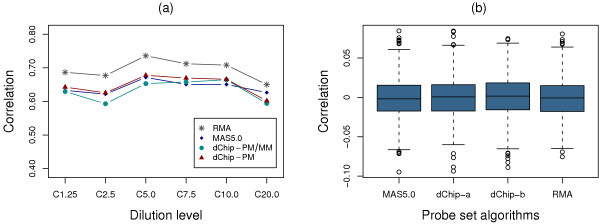
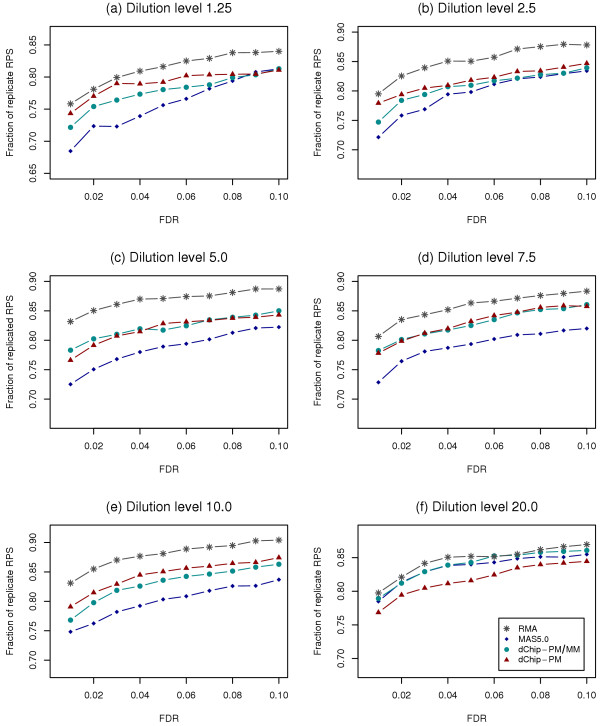
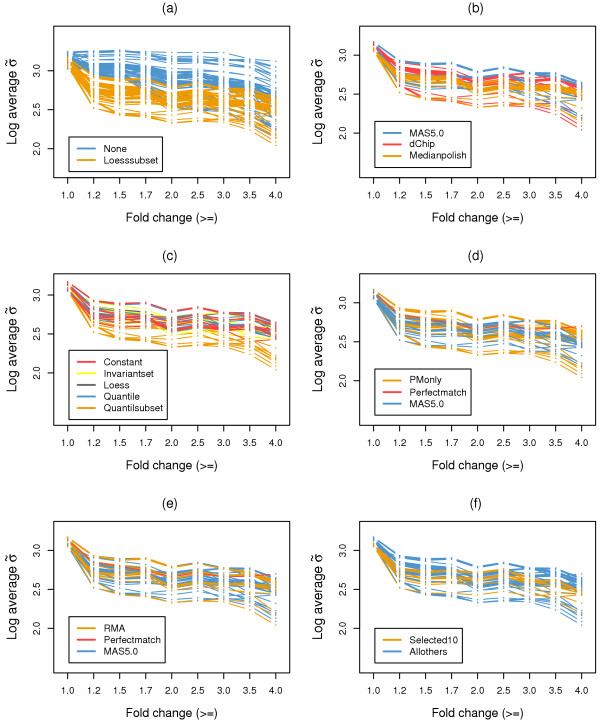
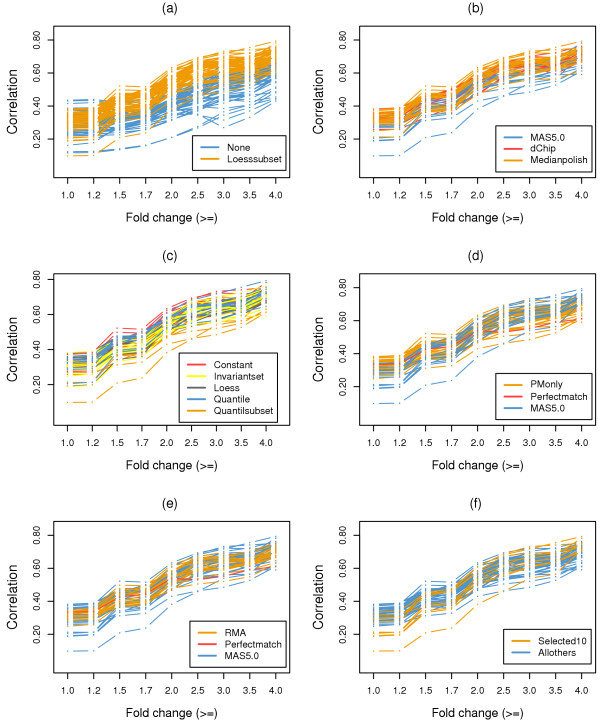
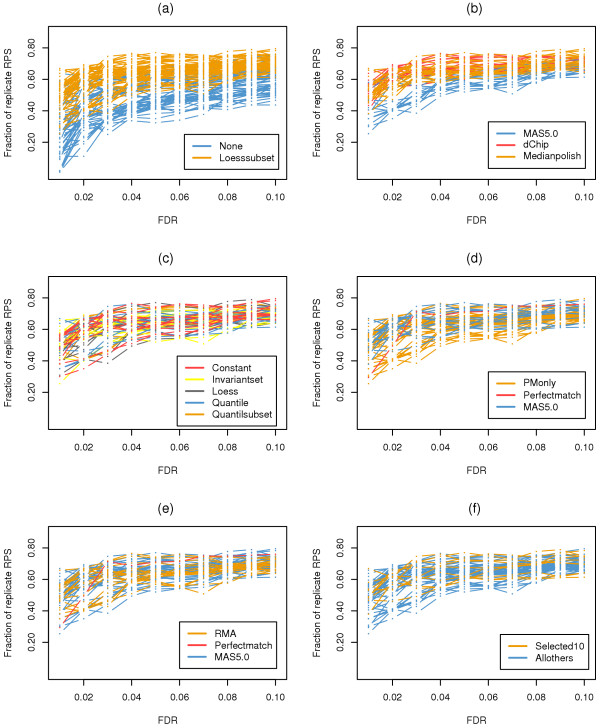
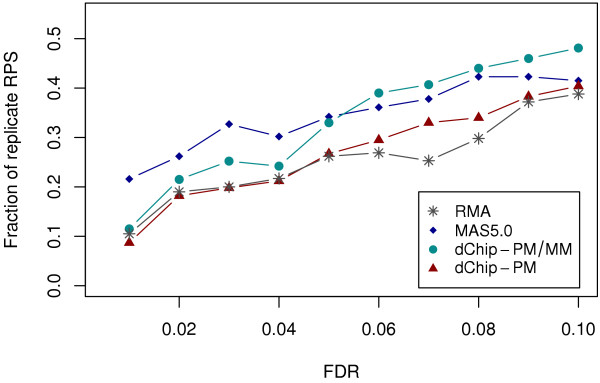
We propose the use of the probe set redundancy feature for evaluating the performance of probe set algorithms, and have presented three approaches for analyzing data variance and result bias using two sample t-test statistics from redundant probe sets. These approaches are as follows: 1) analyzing redundant probe set variance based on t-statistic rank order, 2) computing correlation of t-statistics between redundant probe sets, and 3) analyzing the co-occurrence of replicate redundant probe sets representing differentially expressed genes. We applied these approaches to expression summary data generated from three datasets utilizing individual probe set algorithms of MAS5.0, dChip, or RMA. We also utilized combinations of options from the three probe set algorithms. We found that results from the three approaches were similar within each individual expression summary dataset, and were also in good agreement with previously reported findings by others. We also demonstrate the validity of our findings by independent experimental methods.
All three proposed approaches allowed us to assess the performance of probe set algorithms using the probe set redundancy feature. The analyses of redundant probe set variance based on t-statistic rank order and correlation of t-statistics between redundant probe sets provide useful tools for data variance analysis, and the co-occurrence of replicate redundant probe sets representing differentially expressed genes allows estimation of result bias. The results also suggest that individual probe set algorithms have dataset-specific performance.
在基因芯片研究中,用于表达汇总的探针集算法选择对后续基因表达数据分析有很大影响。已知浓度的掺入式cRNA常被用于评估探针集算法的相对性能。鉴于掺入式cRNA在实验中并不代表内源性表达基因,因此,在不使用此类外部参考数据的情况下,研究特定探针集算法是否更适合特定数据集的方法变得越来越重要。
我们建议使用探针集冗余特征来评估探针集算法的性能,并提出了三种利用冗余探针集的双样本t检验统计量分析数据方差和结果偏差的方法。这些方法如下:1)基于t统计量排序分析冗余探针集方差;2)计算冗余探针集之间t统计量的相关性;3)分析代表差异表达基因的重复冗余探针集的共现情况。我们将这些方法应用于利用MAS5.0、dChip或RMA的单个探针集算法从三个数据集中生成的表达汇总数据。我们还利用了这三种探针集算法的选项组合。我们发现,在每个单独的表达汇总数据集中,这三种方法的结果相似,并且也与其他人先前报道的结果高度一致。我们还通过独立实验方法证明了我们发现的有效性。
所有三种提出的方法都使我们能够利用探针集冗余特征评估探针集算法的性能。基于t统计量排序的冗余探针集方差分析和冗余探针集之间t统计量的相关性分析为数据方差分析提供了有用的工具,而代表差异表达基因的重复冗余探针集的共现情况则可以估计结果偏差。结果还表明,单个探针集算法具有数据集特定的性能。