Bradley Michael E, Benner Steven A
Department of Chemistry, University of Florida, PO Box 117200, Gainesville, FL 32611, USA.
BMC Bioinformatics. 2006 Feb 23;7:89. doi: 10.1186/1471-2105-7-89.
When accurate models for the divergent evolution of protein sequences are integrated with complementary biological information, such as folded protein structures, analyses of the combined data often lead to new hypotheses about molecular physiology. This represents an excellent example of how bioinformatics can be used to guide experimental research. However, progress in this direction has been slowed by the lack of a publicly available resource suitable for general use.
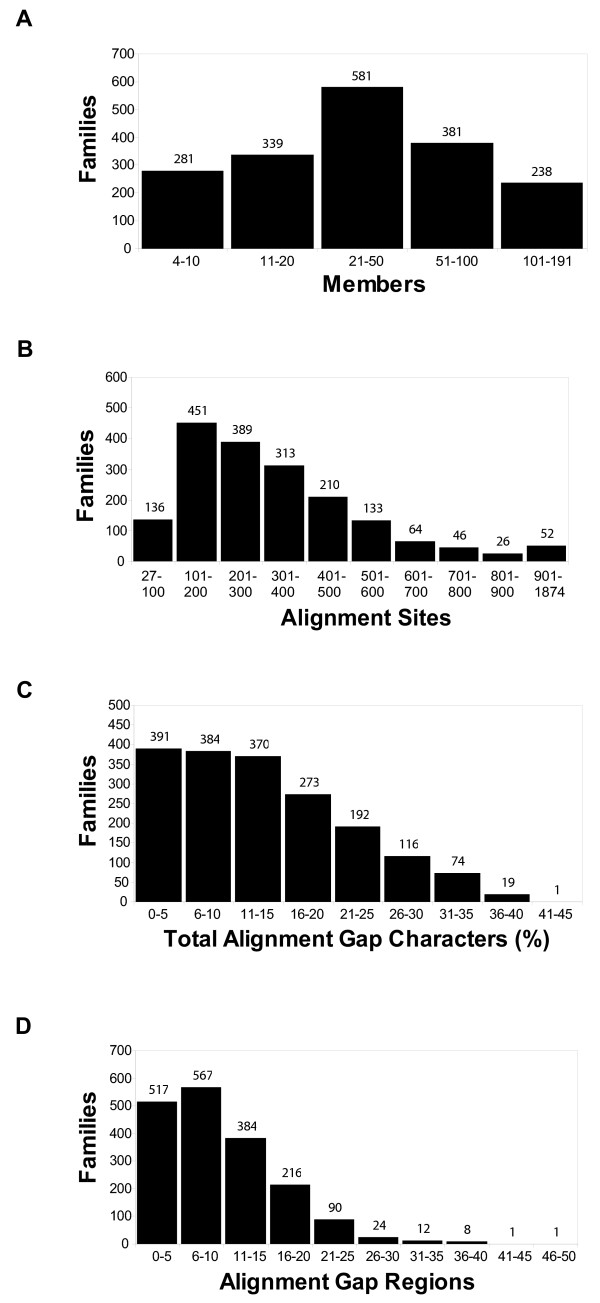
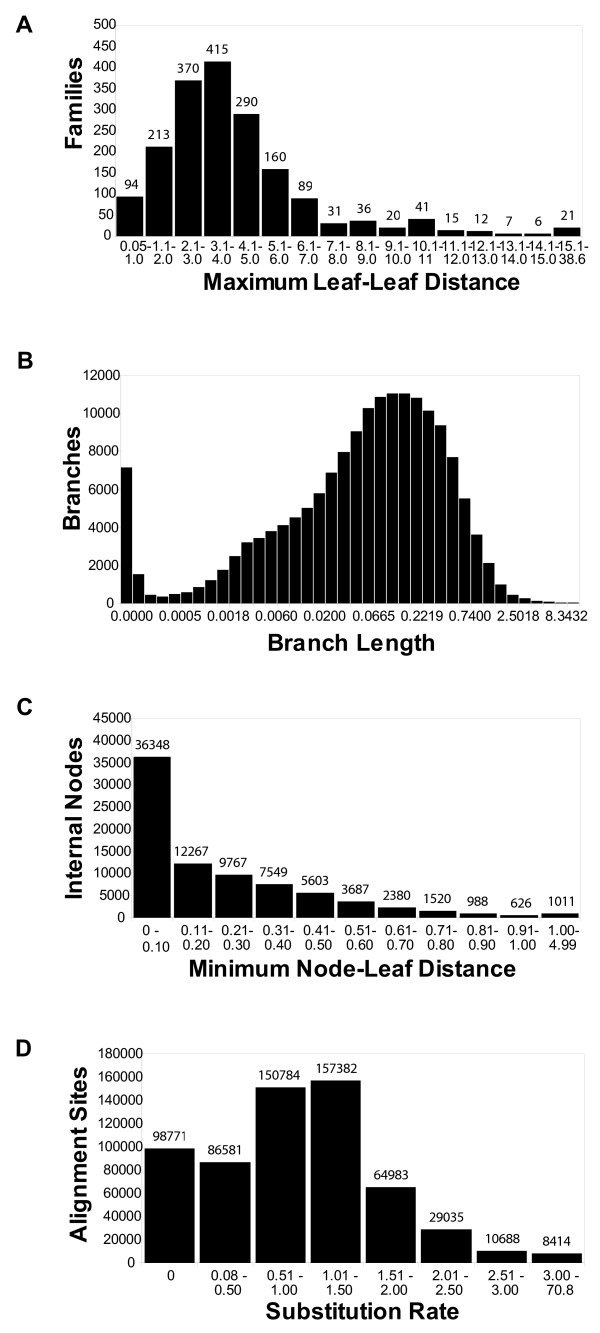
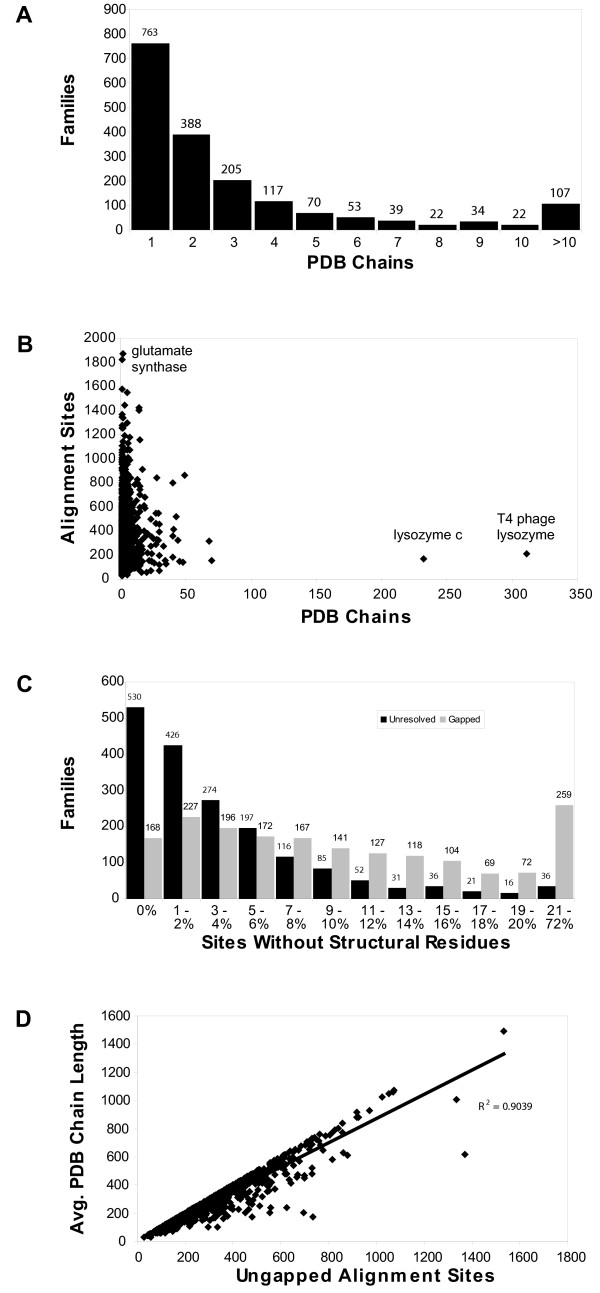
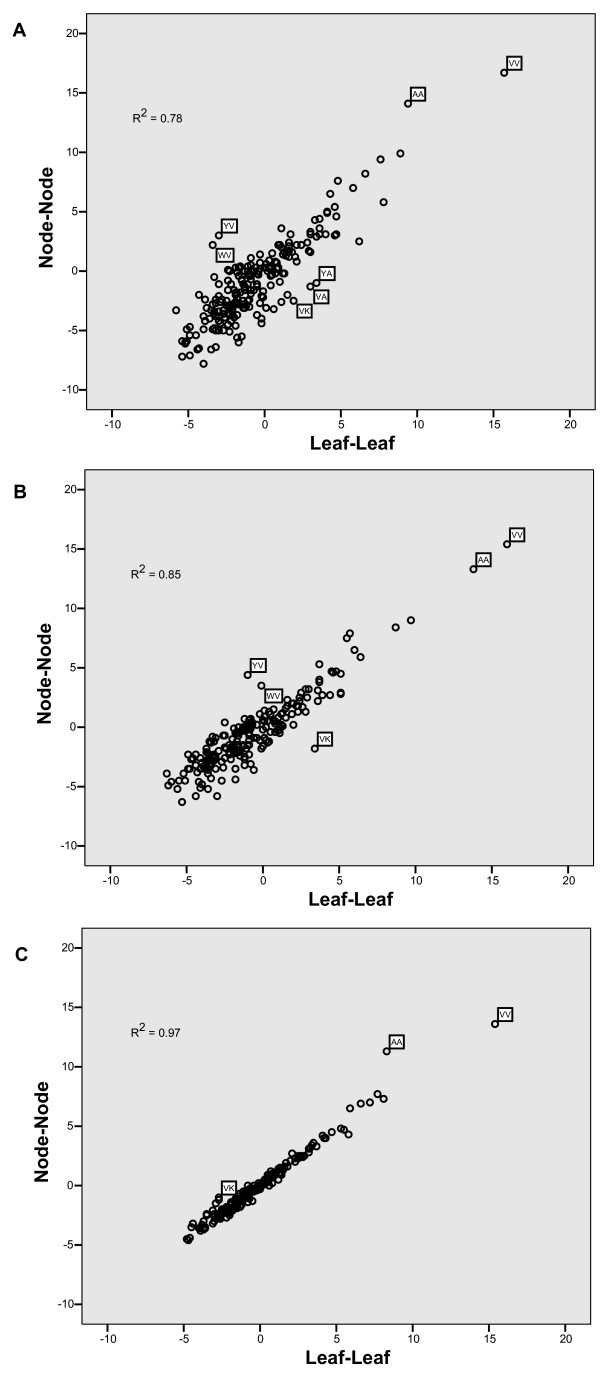
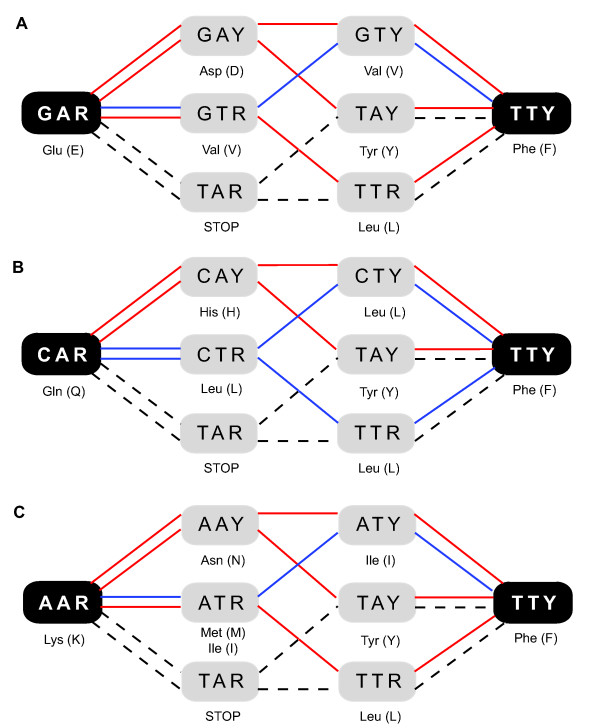
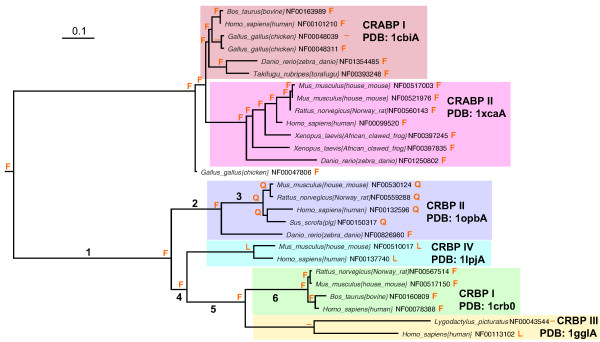
The precomputed Magnum database offers a solution to this problem for ca. 1,800 full-length protein families with at least one crystal structure. The Magnum deliverables include 1) multiple sequence alignments, 2) mapping of alignment sites to crystal structure sites, 3) phylogenetic trees, 4) inferred ancestral sequences at internal tree nodes, and 5) amino acid replacements along tree branches. Comprehensive evaluations revealed that the automated procedures used to construct Magnum produced accurate models of how proteins divergently evolve, or genealogies, and correctly integrated these with the structural data. To demonstrate Magnum's capabilities, we asked for amino acid replacements requiring three nucleotide substitutions, located at internal protein structure sites, and occurring on short phylogenetic tree branches. In the cellular retinoid binding protein family a site that potentially modulates ligand binding affinity was discovered. Recruitment of cellular retinol binding protein to function as a lens crystallin in the diurnal gecko afforded another opportunity to showcase the predictive value of a browsable database containing branch replacement patterns integrated with protein structures.
We integrated two areas of protein science, evolution and structure, on a large scale and created a precomputed database, known as Magnum, which is the first freely available resource of its kind. Magnum provides evolutionary and structural bioinformatics resources that are useful for identifying experimentally testable hypotheses about the molecular basis of protein behaviors and functions, as illustrated with the examples from the cellular retinoid binding proteins.
当将蛋白质序列趋异进化的精确模型与互补的生物学信息(如折叠的蛋白质结构)相结合时,对组合数据的分析往往会产生关于分子生理学的新假设。这是生物信息学如何用于指导实验研究的一个绝佳例子。然而,由于缺乏适用于一般用途的公开可用资源,这一方向的进展一直较为缓慢。
预先计算的Magnum数据库为大约1800个具有至少一个晶体结构的全长蛋白质家族解决了这一问题。Magnum提供的成果包括:1)多序列比对;2)比对位点到晶体结构位点的映射;3)系统发育树;4)内部树节点处的推断祖先序列;5)沿树枝的氨基酸替换。综合评估表明,用于构建Magnum的自动化程序产生了蛋白质趋异进化(即谱系)的精确模型,并将这些模型与结构数据正确整合。为了展示Magnum的能力,我们查找了位于蛋白质内部结构位点、需要三个核苷酸替换且发生在短系统发育树分支上的氨基酸替换。在细胞视黄醇结合蛋白家族中,发现了一个可能调节配体结合亲和力的位点。在日行壁虎中,细胞视黄醇结合蛋白被招募来充当晶状体晶状体蛋白,这为展示一个包含与蛋白质结构整合的分支替换模式的可浏览数据库的预测价值提供了另一个机会。
我们大规模整合了蛋白质科学的两个领域——进化和结构,并创建了一个预先计算的数据库Magnum,这是同类中的首个免费可用资源。Magnum提供了进化和结构生物信息学资源,有助于识别关于蛋白质行为和功能分子基础的可实验验证的假设,如细胞视黄醇结合蛋白的例子所示。