Altaf-Ul-Amin Md, Shinbo Yoko, Mihara Kenji, Kurokawa Ken, Kanaya Shigehiko
Department of Bioinformatics and Genomics, Graduate School of Information Science, Nara Institute of Science and Technology, 8916-5 Takayama, Ikoma, Nara 630-0101, Japan.
BMC Bioinformatics. 2006 Apr 14;7:207. doi: 10.1186/1471-2105-7-207.
After complete sequencing of a number of genomes the focus has now turned to proteomics. Advanced proteomics technologies such as two-hybrid assay, mass spectrometry etc. are producing huge data sets of protein-protein interactions which can be portrayed as networks, and one of the burning issues is to find protein complexes in such networks. The enormous size of protein-protein interaction (PPI) networks warrants development of efficient computational methods for extraction of significant complexes.
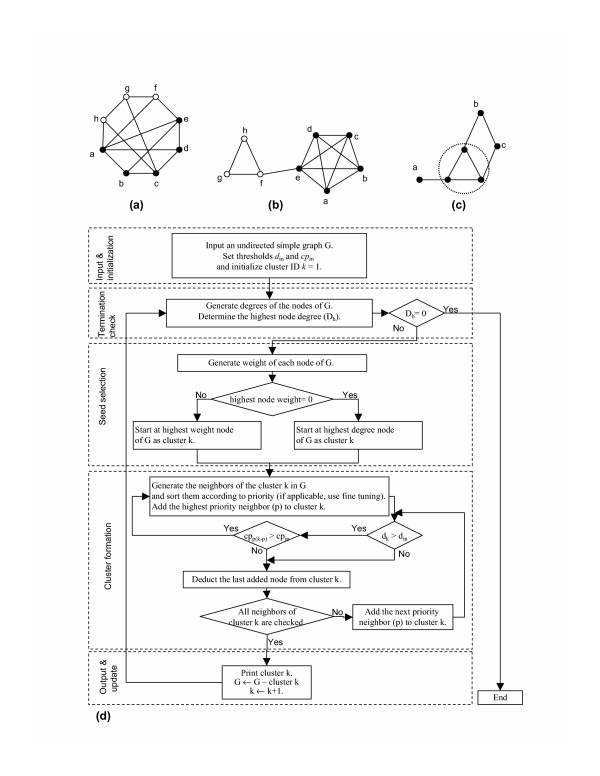
This paper presents an algorithm for detection of protein complexes in large interaction networks. In a PPI network, a node represents a protein and an edge represents an interaction. The input to the algorithm is the associated matrix of an interaction network and the outputs are protein complexes. The complexes are determined by way of finding clusters, i. e. the densely connected regions in the network. We also show and analyze some protein complexes generated by the proposed algorithm from typical PPI networks of Escherichia coli and Saccharomyces cerevisiae. A comparison between a PPI and a random network is also performed in the context of the proposed algorithm.
The proposed algorithm makes it possible to detect clusters of proteins in PPI networks which mostly represent molecular biological functional units. Therefore, protein complexes determined solely based on interaction data can help us to predict the functions of proteins, and they are also useful to understand and explain certain biological processes.
在完成多个基因组的测序后,研究重点现已转向蛋白质组学。诸如双杂交检测、质谱分析等先进的蛋白质组学技术正在产生大量蛋白质 - 蛋白质相互作用的数据集,这些数据集可以描绘成网络,而其中一个亟待解决的问题是在这样的网络中找到蛋白质复合物。蛋白质 - 蛋白质相互作用(PPI)网络的巨大规模促使人们开发高效的计算方法来提取重要的复合物。
本文提出了一种用于在大型相互作用网络中检测蛋白质复合物的算法。在一个PPI网络中,一个节点代表一种蛋白质,一条边代表一种相互作用。该算法的输入是一个相互作用网络的关联矩阵,输出则是蛋白质复合物。这些复合物是通过寻找聚类来确定的,即网络中紧密连接的区域。我们还展示并分析了该算法从大肠杆菌和酿酒酵母的典型PPI网络中生成的一些蛋白质复合物。在该算法的背景下,还对一个PPI网络和一个随机网络进行了比较。
所提出的算法能够检测PPI网络中的蛋白质聚类,这些聚类大多代表分子生物学功能单元。因此,仅基于相互作用数据确定的蛋白质复合物有助于我们预测蛋白质的功能,并且它们对于理解和解释某些生物学过程也很有用。