Birkholtz Lyn-Marie, Bastien Olivier, Wells Gordon, Grando Delphine, Joubert Fourie, Kasam Vinod, Zimmermann Marc, Ortet Philippe, Jacq Nicolas, Saïdani Nadia, Roy Sylvaine, Hofmann-Apitius Martin, Breton Vincent, Louw Abraham I, Maréchal Eric
Department of Biochemistry and African Centre for Gene Technologies, Faculty of Natural and Agricultural Sciences, University of Pretoria, 0002, Pretoria, South Africa.
Malar J. 2006 Nov 17;5:110. doi: 10.1186/1475-2875-5-110.
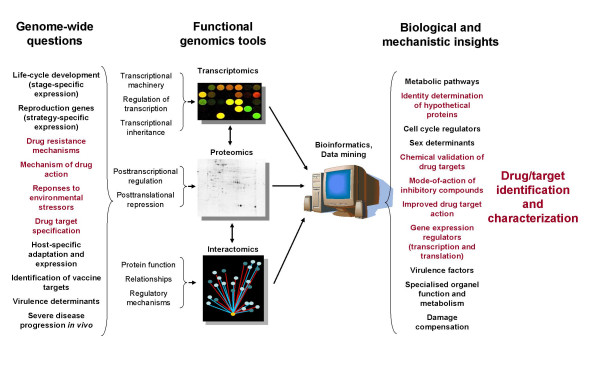
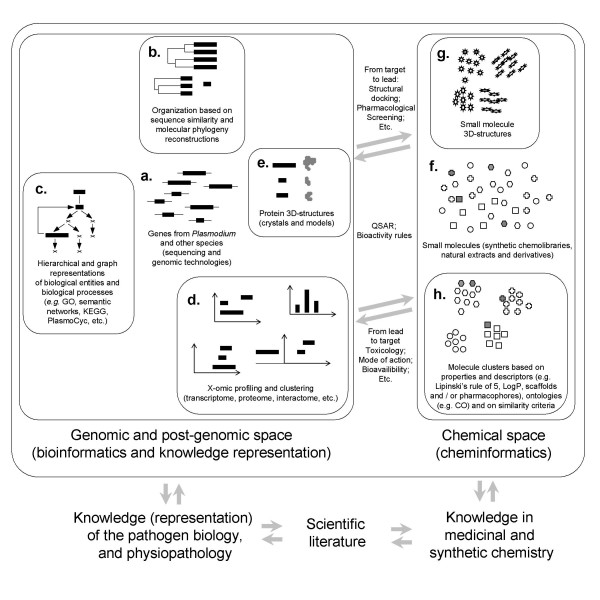
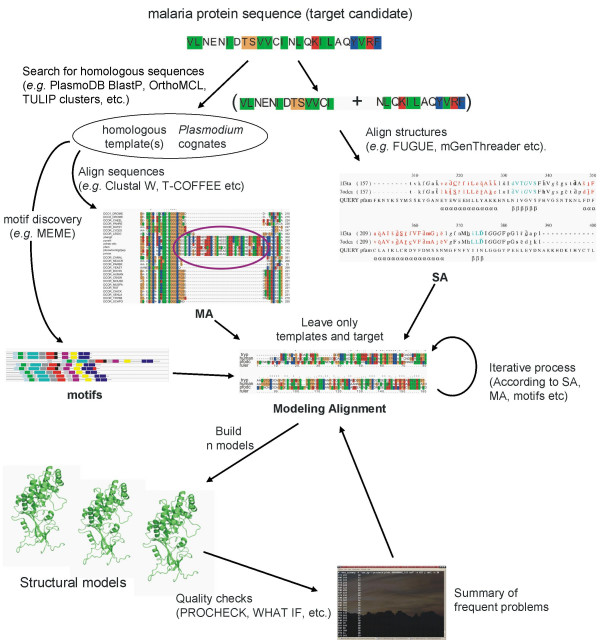
The organization and mining of malaria genomic and post-genomic data is important to significantly increase the knowledge of the biology of its causative agents, and is motivated, on a longer term, by the necessity to predict and characterize new biological targets and new drugs. Biological targets are sought in a biological space designed from the genomic data from Plasmodium falciparum, but using also the millions of genomic data from other species. Drug candidates are sought in a chemical space containing the millions of small molecules stored in public and private chemolibraries. Data management should, therefore, be as reliable and versatile as possible. In this context, five aspects of the organization and mining of malaria genomic and post-genomic data were examined: 1) the comparison of protein sequences including compositionally atypical malaria sequences, 2) the high throughput reconstruction of molecular phylogenies, 3) the representation of biological processes, particularly metabolic pathways, 4) the versatile methods to integrate genomic data, biological representations and functional profiling obtained from X-omic experiments after drug treatments and 5) the determination and prediction of protein structures and their molecular docking with drug candidate structures. Recent progress towards a grid-enabled chemogenomic knowledge space is discussed.
疟疾病原体基因组和后基因组数据的组织与挖掘对于大幅增加对其致病因子生物学的认识非常重要,从长远来看,这是出于预测和鉴定新生物靶点及新药的必要性。生物靶点是在根据恶性疟原虫基因组数据构建的生物空间中寻找的,但也会利用来自其他物种的数百万基因组数据。候选药物则是在包含公共和私人化学文库中存储的数百万小分子的化学空间中寻找。因此,数据管理应尽可能可靠且通用。在此背景下,研究了疟疾病原体基因组和后基因组数据组织与挖掘的五个方面:1)包括组成上非典型疟原虫序列在内的蛋白质序列比较;2)分子系统发育的高通量重建;3)生物过程,特别是代谢途径的表示;4)整合药物处理后从X-组学实验获得的基因组数据、生物表示和功能谱的通用方法;5)蛋白质结构的确定与预测及其与候选药物结构的分子对接。讨论了朝着支持网格的化学基因组知识空间取得的最新进展。