Malik Adeel, Ahmad Shandar
Department of Biosciences, Jamia Millia Islamia University, New Delhi-110025, India.
BMC Struct Biol. 2007 Jan 3;7:1. doi: 10.1186/1472-6807-7-1.
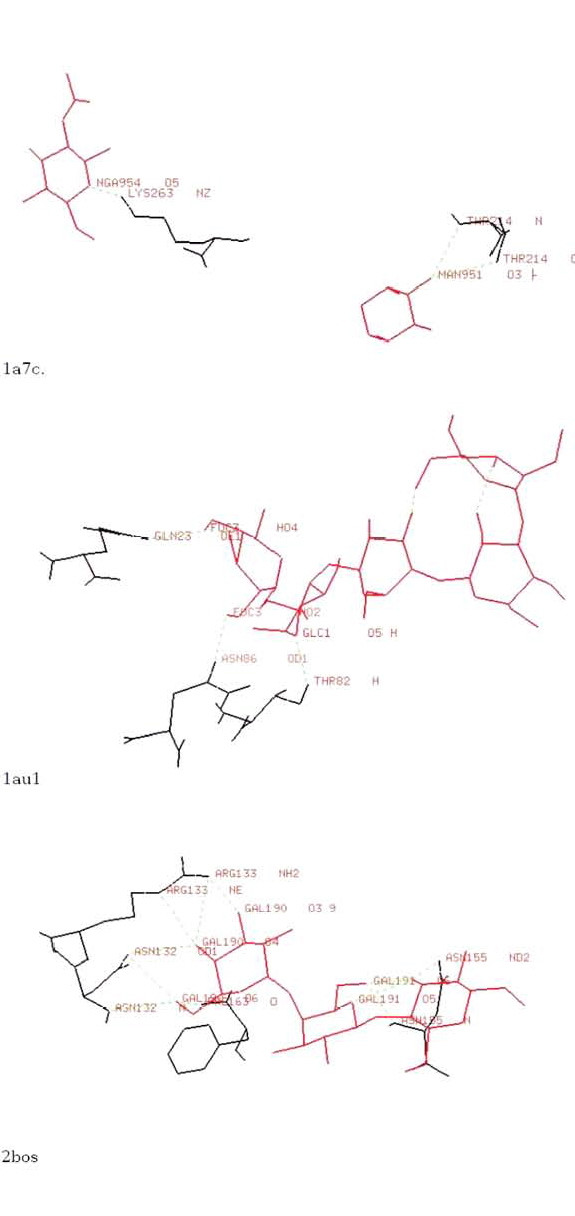
Protein-Carbohydrate interactions are crucial in many biological processes with implications to drug targeting and gene expression. Nature of protein-carbohydrate interactions may be studied at individual residue level by analyzing local sequence and structure environments in binding regions in comparison to non-binding regions, which provide an inherent control for such analyses. With an ultimate aim of predicting binding sites from sequence and structure, overall statistics of binding regions needs to be compiled. Sequence-based predictions of binding sites have been successfully applied to DNA-binding proteins in our earlier works. We aim to apply similar analysis to carbohydrate binding proteins. However, due to a relatively much smaller region of proteins taking part in such interactions, the methodology and results are significantly different. A comparison of protein-carbohydrate complexes has also been made with other protein-ligand complexes.
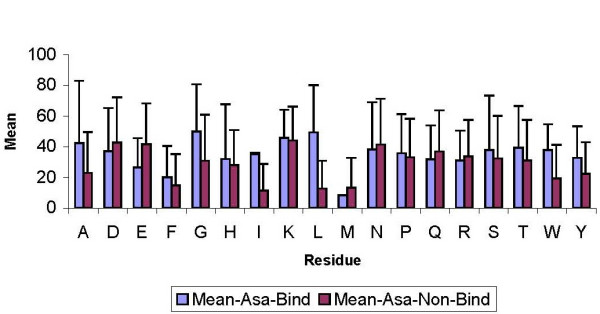
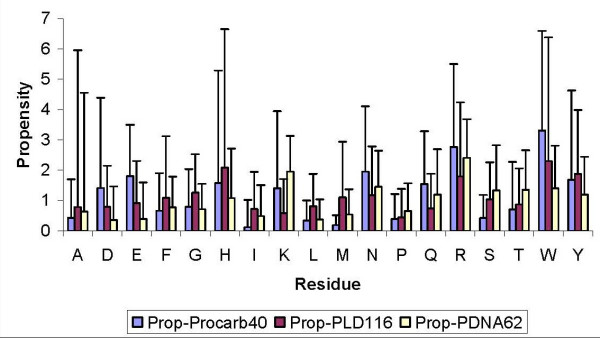
We have compiled statistics of amino acid compositions in binding versus non-binding regions- general as well as in each different secondary structure conformation. Binding propensities of each of the 20 residue types and their structure features such as solvent accessibility, packing density and secondary structure have been calculated to assess their predisposition to carbohydrate interactions. Finally, evolutionary profiles of amino acid sequences have been used to predict binding sites using a neural network. Another set of neural networks was trained using information from single sequences and the prediction performance from the evolutionary profiles and single sequences were compared. Best of the neural network based prediction could achieve an 87% sensitivity of prediction at 23% specificity for all carbohydrate-binding sites, using evolutionary information. Single sequences gave 68% sensitivity and 55% specificity for the same data set. Sensitivity and specificity for a limited galactose binding data set were obtained as 63% and 79% respectively for evolutionary information and 62% and 68% sensitivity and specificity for single sequences. Propensity and other sequence and structural features of carbohydrate binding sites have also been compared with our similar extensive studies on DNA-binding proteins and also with protein-ligand complexes.
Carbohydrates typically show a preference to bind aromatic residues and most prominently tryptophan. Higher exposed surface area of binding sites indicates a role of hydrophobic interactions. Neural networks give a moderate success of prediction, which is expected to improve when structures of more protein-carbohydrate complexes become available in future.
蛋白质 - 碳水化合物相互作用在许多生物过程中至关重要,对药物靶向和基因表达具有重要意义。通过分析结合区域与非结合区域的局部序列和结构环境,可以在单个残基水平上研究蛋白质 - 碳水化合物相互作用的性质,这为这类分析提供了内在对照。为了从序列和结构预测结合位点,需要汇编结合区域的总体统计数据。基于序列的结合位点预测已在我们早期的工作中成功应用于DNA结合蛋白。我们旨在将类似的分析应用于碳水化合物结合蛋白。然而,由于参与此类相互作用的蛋白质区域相对小得多,方法和结果有显著差异。还对蛋白质 - 碳水化合物复合物与其他蛋白质 - 配体复合物进行了比较。
我们汇编了结合区域与非结合区域(总体以及每种不同二级结构构象)的氨基酸组成统计数据。计算了20种残基类型中每种残基的结合倾向及其结构特征,如溶剂可及性、堆积密度和二级结构,以评估它们与碳水化合物相互作用的倾向。最后,利用氨基酸序列的进化谱通过神经网络预测结合位点。使用来自单序列的信息训练另一组神经网络,并比较进化谱和单序列的预测性能。基于神经网络的最佳预测在使用进化信息时,对所有碳水化合物结合位点可达到87%的预测灵敏度和23%的特异性。对于同一数据集,单序列的灵敏度为68%,特异性为55%。对于有限的半乳糖结合数据集,进化信息的灵敏度和特异性分别为63%和79%,单序列的灵敏度和特异性分别为62%和68%。碳水化合物结合位点的倾向以及其他序列和结构特征也已与我们对DNA结合蛋白的类似广泛研究以及蛋白质 - 配体复合物进行了比较。
碳水化合物通常倾向于结合芳香族残基,最显著的是色氨酸。结合位点较高的暴露表面积表明疏水相互作用起作用。神经网络预测取得了一定成功,预计未来当有更多蛋白质 - 碳水化合物复合物的结构时,预测效果会有所改善。