Pollastri Gianluca, Martin Alberto J M, Mooney Catherine, Vullo Alessandro
Complex and Adaptive Systems Laboratory, School of Computer Science and Informatics, University College Dublin, Belfield, Dublin 4, Ireland.
BMC Bioinformatics. 2007 Jun 14;8:201. doi: 10.1186/1471-2105-8-201.
Structural properties of proteins such as secondary structure and solvent accessibility contribute to three-dimensional structure prediction, not only in the ab initio case but also when homology information to known structures is available. Structural properties are also routinely used in protein analysis even when homology is available, largely because homology modelling is lower throughput than, say, secondary structure prediction. Nonetheless, predictors of secondary structure and solvent accessibility are virtually always ab initio.
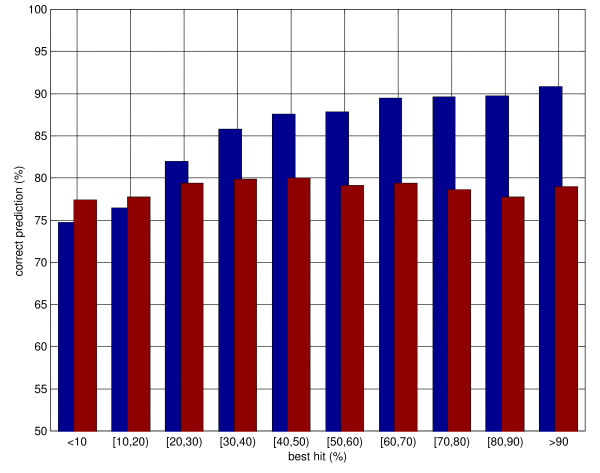
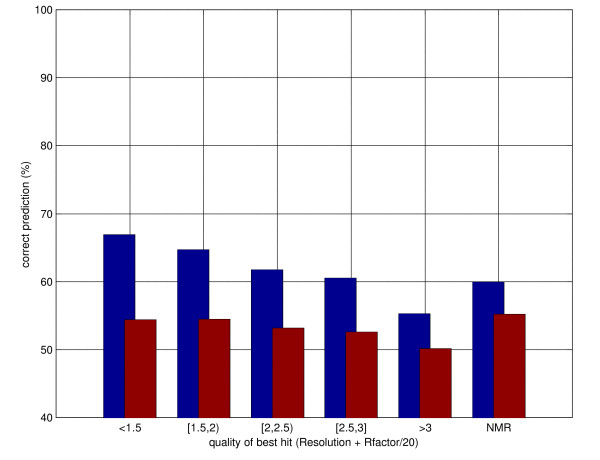
Here we develop high-throughput machine learning systems for the prediction of protein secondary structure and solvent accessibility that exploit homology to proteins of known structure, where available, in the form of simple structural frequency profiles extracted from sets of PDB templates. We compare these systems to their state-of-the-art ab initio counterparts, and with a number of baselines in which secondary structures and solvent accessibilities are extracted directly from the templates. We show that structural information from templates greatly improves secondary structure and solvent accessibility prediction quality, and that, on average, the systems significantly enrich the information contained in the templates. For sequence similarity exceeding 30%, secondary structure prediction quality is approximately 90%, close to its theoretical maximum, and 2-class solvent accessibility roughly 85%. Gains are robust with respect to template selection noise, and significant for marginal sequence similarity and for short alignments, supporting the claim that these improved predictions may prove beneficial beyond the case in which clear homology is available.
The predictive system are publicly available at the address http://distill.ucd.ie.
蛋白质的结构特性,如二级结构和溶剂可及性,不仅有助于从头预测三维结构,在有已知结构的同源信息时也有帮助。即使有同源性信息,结构特性在蛋白质分析中也经常被使用,很大程度上是因为同源建模的通量低于二级结构预测等方法。尽管如此,二级结构和溶剂可及性的预测器几乎总是从头开始的。
在这里,我们开发了用于预测蛋白质二级结构和溶剂可及性的高通量机器学习系统,该系统利用与已知结构蛋白质的同源性(如果有的话),以从PDB模板集中提取的简单结构频率分布的形式。我们将这些系统与其从头开始的同类先进系统进行比较,并与一些直接从模板中提取二级结构和溶剂可及性的基线进行比较。我们表明,模板中的结构信息大大提高了二级结构和溶剂可及性的预测质量,并且平均而言,这些系统显著丰富了模板中包含的信息。对于序列相似性超过30%的情况,二级结构预测质量约为90%,接近其理论最大值,二分类溶剂可及性约为85%。对于模板选择噪声,增益是稳健的,对于边缘序列相似性和短比对也是显著的,这支持了这样的观点,即这些改进的预测可能在没有明显同源性的情况下也有益处。