Chiang Tony, Scholtens Denise, Sarkar Deepayan, Gentleman Robert, Huber Wolfgang
EMBL, European Bioinformatics Institute, Wellcome Trust Genome Campus, Hinxton, Cambridge, CB10 1SD, UK.
Genome Biol. 2007;8(9):R186. doi: 10.1186/gb-2007-8-9-r186.
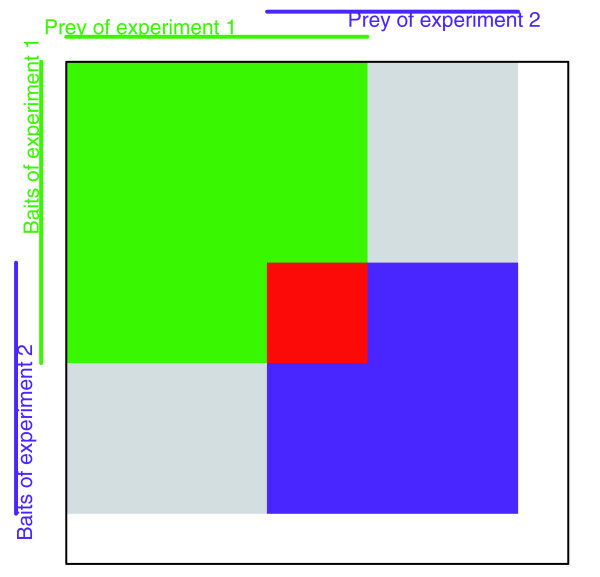
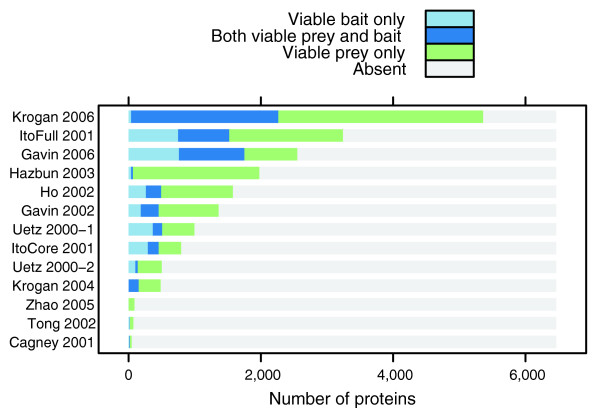
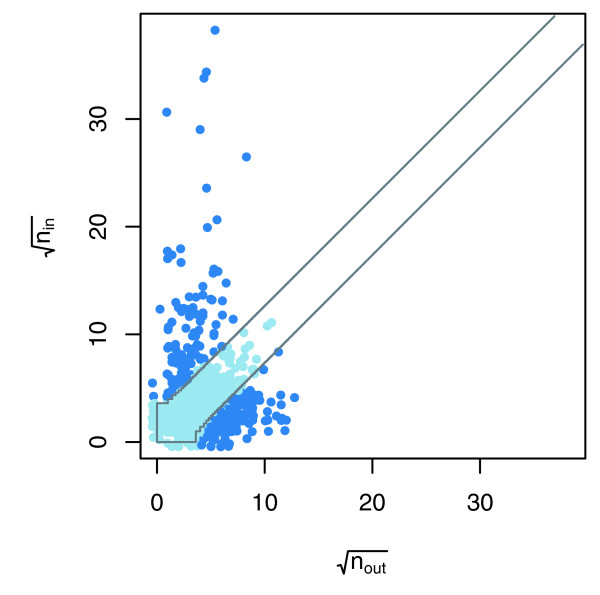
Using a directed graph model for bait to prey systems and a multinomial error model, we assessed the error statistics in all published large-scale datasets for Saccharomyces cerevisiae and characterized them by three traits: the set of tested interactions, artifacts that lead to false-positive or false-negative observations, and estimates of the stochastic error rates that affect the data. These traits provide a prerequisite for the estimation of the protein interactome and its modules.
我们使用针对诱饵-猎物系统的有向图模型和多项误差模型,评估了酿酒酵母所有已发表的大规模数据集中的误差统计数据,并通过三个特征对其进行了表征:测试的相互作用集、导致假阳性或假阴性观察结果的人为因素,以及影响数据的随机误差率估计。这些特征为蛋白质相互作用组及其模块的估计提供了前提条件。