Willighagen Egon L, O'Boyle Noel M, Gopalakrishnan Harini, Jiao Dazhi, Guha Rajarshi, Steinbeck Christoph, Wild David J
Cologne University Bioinformatics Center, Cologne University, Cologne, Germany.
BMC Bioinformatics. 2007 Dec 21;8:487. doi: 10.1186/1471-2105-8-487.
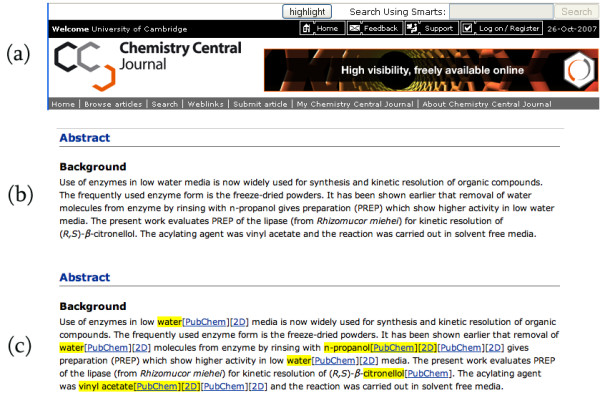
The web has seen an explosion of chemistry and biology related resources in the last 15 years: thousands of scientific journals, databases, wikis, blogs and resources are available with a wide variety of types of information. There is a huge need to aggregate and organise this information. However, the sheer number of resources makes it unrealistic to link them all in a centralised manner. Instead, search engines to find information in those resources flourish, and formal languages like Resource Description Framework and Web Ontology Language are increasingly used to allow linking of resources. A recent development is the use of userscripts to change the appearance of web pages, by on-the-fly modification of the web content. This opens possibilities to aggregate information and computational results from different web resources into the web page of one of those resources.
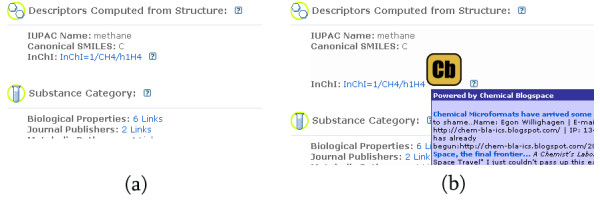
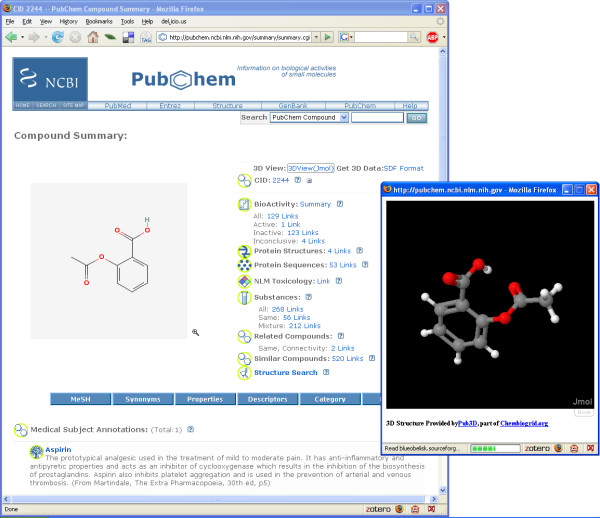
Several userscripts are presented that enrich biology and chemistry related web resources by incorporating or linking to other computational or data sources on the web. The scripts make use of Greasemonkey-like plugins for web browsers and are written in JavaScript. Information from third-party resources are extracted using open Application Programming Interfaces, while common Universal Resource Locator schemes are used to make deep links to related information in that external resource. The userscripts presented here use a variety of techniques and resources, and show the potential of such scripts.
This paper discusses a number of userscripts that aggregate information from two or more web resources. Examples are shown that enrich web pages with information from other resources, and show how information from web pages can be used to link to, search, and process information in other resources. Due to the nature of userscripts, scientists are able to select those scripts they find useful on a daily basis, as the scripts run directly in their own web browser rather than on the web server. This flexibility allows the scientists to tune the features of web resources to optimise their productivity.
在过去15年里,网络上与化学和生物学相关的资源呈爆炸式增长:有成千上万种科学期刊、数据库、维基、博客以及各种类型信息的资源。对这些信息进行汇总和整理的需求巨大。然而,资源数量之多使得以集中方式将它们全部链接起来变得不切实际。相反,用于在这些资源中查找信息的搜索引擎蓬勃发展,并且诸如资源描述框架和网络本体语言等形式语言越来越多地被用于实现资源链接。最近的一个发展是使用用户脚本通过即时修改网页内容来改变网页外观。这为将来自不同网络资源的信息和计算结果汇总到其中一个资源的网页中开辟了可能性。
展示了几个用户脚本,这些脚本通过合并或链接到网络上的其他计算或数据源来丰富与生物学和化学相关的网络资源。这些脚本利用类似Greasemonkey的网络浏览器插件,并使用JavaScript编写。通过开放的应用程序编程接口提取来自第三方资源的信息,同时使用常见的通用资源定位器方案来创建到该外部资源中相关信息的深度链接。这里展示的用户脚本使用了多种技术和资源,并展示了此类脚本的潜力。
本文讨论了一些汇总来自两个或更多网络资源信息的用户脚本。给出的示例展示了如何用来自其他资源的信息丰富网页,以及展示了如何利用网页中的信息来链接、搜索和处理其他资源中的信息。由于用户脚本的性质,科学家能够选择他们日常觉得有用的那些脚本,因为这些脚本直接在他们自己的网络浏览器中运行,而不是在网络服务器上。这种灵活性使科学家能够调整网络资源的功能以优化其工作效率。