Lee Ho-Joon, Manke Thomas, Bringas Ricardo, Vingron Martin
Department of Computational Molecular Biology, Max Planck Institute for Molecular Genetics, 14195 Berlin, Germany.
BMC Bioinformatics. 2008 Jan 22;9:32. doi: 10.1186/1471-2105-9-32.
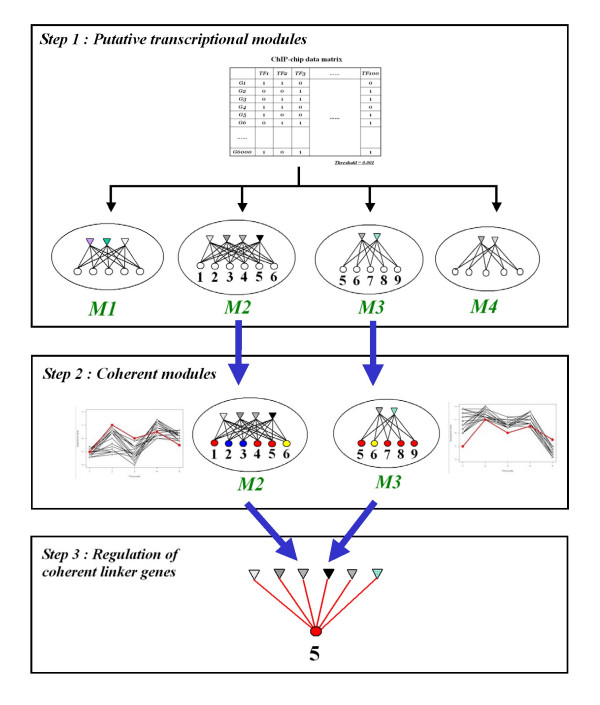
The identification of groups of co-regulated genes and their transcription factors, called transcriptional modules, has been a focus of many studies about biological systems. While methods have been developed to derive numerous modules from genome-wide data, individual links between regulatory proteins and target genes still need experimental verification. In this work, we aim to prioritize regulator-target links within transcriptional modules based on three types of large-scale data sources.
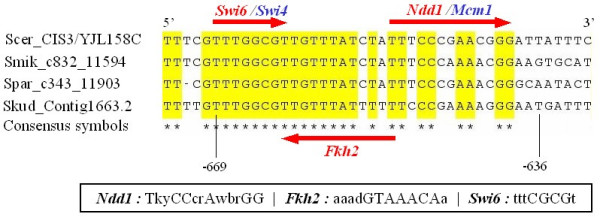
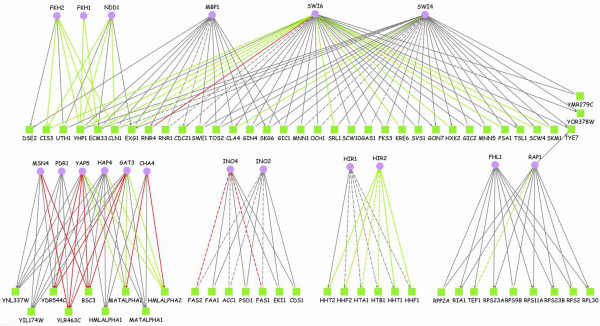
Starting with putative transcriptional modules from ChIP-chip data, we first derive modules in which target genes show both expression and function coherence. The most reliable regulatory links between transcription factors and target genes are established by identifying intersection of target genes in coherent modules for each enriched functional category. Using a combination of genome-wide yeast data in normal growth conditions and two different reference datasets, we show that our method predicts regulatory interactions with significantly higher predictive power than ChIP-chip binding data alone. A comparison with results from other studies highlights that our approach provides a reliable and complementary set of regulatory interactions. Based on our results, we can also identify functionally interacting target genes, for instance, a group of co-regulated proteins related to cell wall synthesis. Furthermore, we report novel conserved binding sites of a glycoprotein-encoding gene, CIS3, regulated by Swi6-Swi4 and Ndd1-Fkh2-Mcm1 complexes.
We provide a simple method to prioritize individual TF-gene interactions from large-scale transcriptional modules. In comparison with other published works, we predict a complementary set of regulatory interactions which yields a similar or higher prediction accuracy at the expense of sensitivity. Therefore, our method can serve as an alternative approach to prioritization for further experimental studies.
共调控基因及其转录因子组(称为转录模块)的识别一直是许多生物系统研究的重点。虽然已经开发出从全基因组数据中推导众多模块的方法,但调节蛋白与靶基因之间的个别联系仍需实验验证。在这项工作中,我们旨在基于三种大规模数据源对转录模块内的调节因子 - 靶标联系进行优先级排序。
从芯片免疫沉淀(ChIP-chip)数据中的假定转录模块开始,我们首先推导靶基因在表达和功能上都具有一致性的模块。通过识别每个富集功能类别中连贯模块内靶基因的交集,建立转录因子与靶基因之间最可靠的调控联系。使用正常生长条件下的全基因组酵母数据与两个不同参考数据集的组合,我们表明我们的方法预测调控相互作用的预测能力明显高于单独的ChIP-chip结合数据。与其他研究结果的比较突出表明,我们的方法提供了一组可靠且互补的调控相互作用。基于我们的结果,我们还可以识别功能上相互作用的靶基因,例如,一组与细胞壁合成相关的共调控蛋白。此外,我们报告了由Swi6-Swi4和Ndd1-Fkh2-Mcm1复合物调控的糖蛋白编码基因CIS3的新保守结合位点。
我们提供了一种简单的方法来对大规模转录模块中的单个转录因子 - 基因相互作用进行优先级排序。与其他已发表的工作相比,我们预测了一组互补的调控相互作用,其预测准确性相似或更高,但以敏感性为代价。因此,我们的方法可以作为进一步实验研究优先级排序的替代方法。