Campagne Fabien
HRH Prince Alwaleed Bin Talal Bin Abdulaziz Alsaud Institute for Computational Biomedicine, New York, NY 10021, USA.
BMC Bioinformatics. 2008 Feb 29;9:132. doi: 10.1186/1471-2105-9-132.
The evaluation of information retrieval techniques has traditionally relied on human judges to determine which documents are relevant to a query and which are not. This protocol is used in the Text Retrieval Evaluation Conference (TREC), organized annually for the past 15 years, to support the unbiased evaluation of novel information retrieval approaches. The TREC Genomics Track has recently been introduced to measure the performance of information retrieval for biomedical applications.
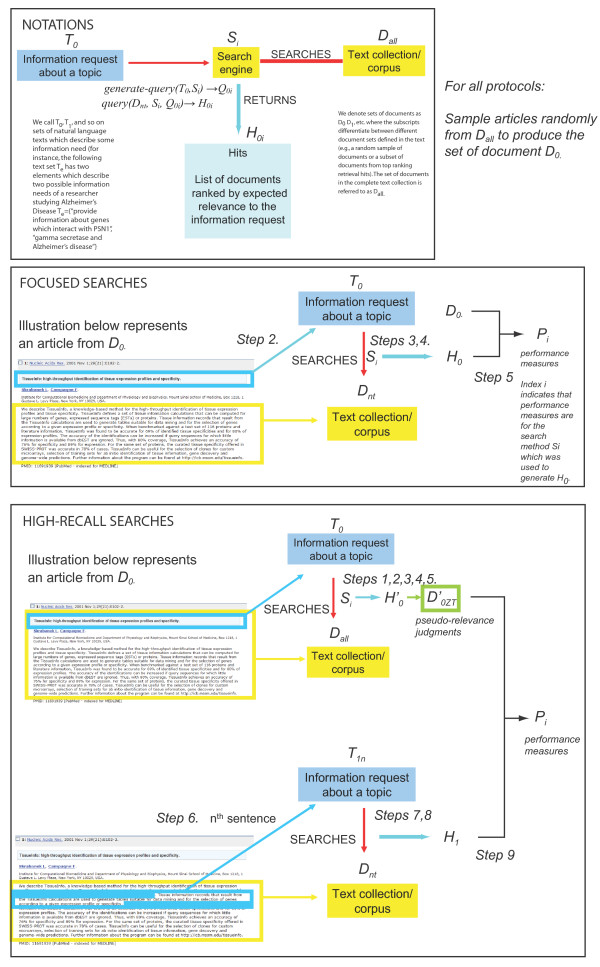
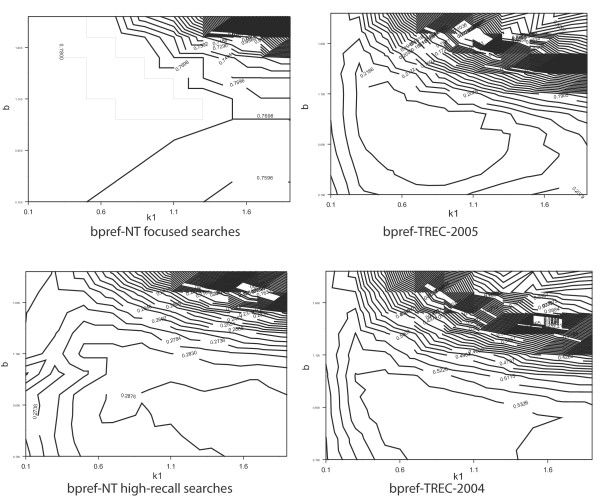
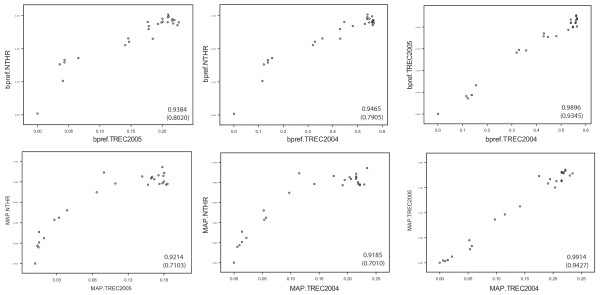
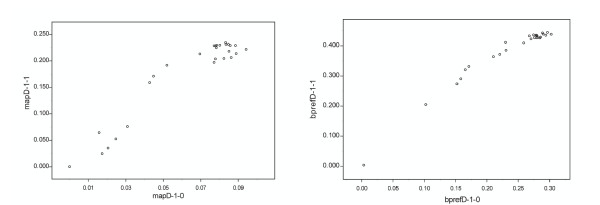
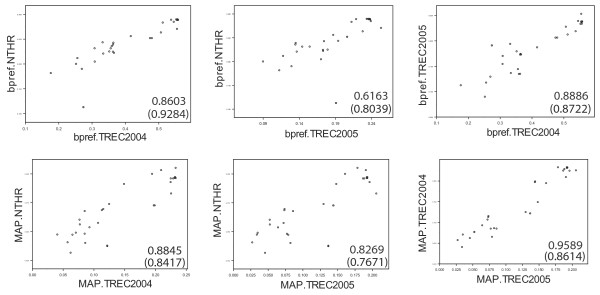
We describe two protocols for evaluating biomedical information retrieval techniques without human relevance judgments. We call these protocols No Title Evaluation (NT Evaluation). The first protocol measures performance for focused searches, where only one relevant document exists for each query. The second protocol measures performance for queries expected to have potentially many relevant documents per query (high-recall searches). Both protocols take advantage of the clear separation of titles and abstracts found in Medline. We compare the performance obtained with these evaluation protocols to results obtained by reusing the relevance judgments produced in the 2004 and 2005 TREC Genomics Track and observe significant correlations between performance rankings generated by our approach and TREC. Spearman's correlation coefficients in the range of 0.79-0.92 are observed comparing bpref measured with NT Evaluation or with TREC evaluations. For comparison, coefficients in the range 0.86-0.94 can be observed when evaluating the same set of methods with data from two independent TREC Genomics Track evaluations. We discuss the advantages of NT Evaluation over the TRels and the data fusion evaluation protocols introduced recently.
Our results suggest that the NT Evaluation protocols described here could be used to optimize some search engine parameters before human evaluation. Further research is needed to determine if NT Evaluation or variants of these protocols can fully substitute for human evaluations.
传统上,信息检索技术的评估依赖于人工评判来确定哪些文档与查询相关,哪些不相关。在过去15年中每年举办的文本检索评估会议(TREC)中使用此协议,以支持对新型信息检索方法进行公正的评估。最近引入了TREC基因组学赛道来衡量生物医学应用中信息检索的性能。
我们描述了两种无需人工相关性判断即可评估生物医学信息检索技术的协议。我们将这些协议称为无标题评估(NT评估)。第一种协议衡量聚焦搜索的性能,其中每个查询只有一篇相关文档。第二种协议衡量预期每个查询可能有许多相关文档的查询的性能(高召回率搜索)。这两种协议都利用了Medline中标题和摘要的清晰分离。我们将使用这些评估协议获得的性能与通过重用2004年和2005年TREC基因组学赛道产生的相关性判断获得的结果进行比较,并观察我们的方法生成的性能排名与TREC之间的显著相关性。使用NT评估或TREC评估测量的bpref进行比较时,观察到斯皮尔曼相关系数在0.79 - 0.92范围内。相比之下,使用来自两个独立的TREC基因组学赛道评估的数据评估同一组方法时,可以观察到系数在0.86 - 0.94范围内。我们讨论了NT评估相对于最近引入的TRels和数据融合评估协议的优势。
我们的结果表明,此处描述的NT评估协议可用于在人工评估之前优化一些搜索引擎参数。需要进一步研究以确定NT评估或这些协议的变体是否可以完全替代人工评估。