Hazelhurst Scott, Hide Winston, Lipták Zsuzsanna, Nogueira Ramon, Starfield Richard
Wits Bioinformatics, University of the Witwatersrand, Johannesburg, Private Bag 3, 2050 Wits, South Africa.
Bioinformatics. 2008 Jul 1;24(13):1542-6. doi: 10.1093/bioinformatics/btn203. Epub 2008 May 14.
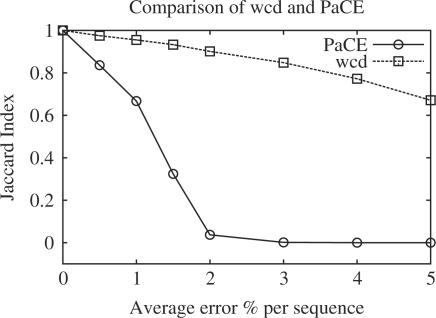
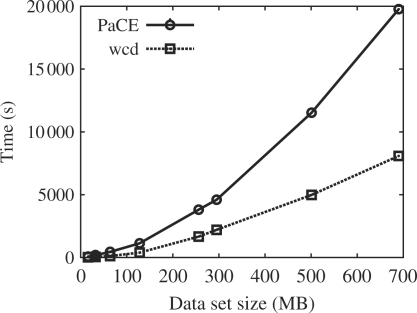
The wcd system is an open source tool for clustering expressed sequence tags (EST) and other DNA and RNA sequences. wcd allows efficient all-versus-all comparison of ESTs using either the d(2) distance function or edit distance, improving existing implementations of d(2). It supports merging, refinement and reclustering of clusters. It is 'drop in' compatible with the StackPack clustering package. wcd supports parallelization under both shared memory and cluster architectures. It is distributed with an EMBOSS wrapper allowing wcd to be installed as part of an EMBOSS installation (and so provided by a web server).
wcd is distributed under a GPL licence and is available from http://code.google.com/p/wcdest.
Additional experimental results. The wcd manual, a companion paper describing underlying algorithms, and all datasets used for experimentation can also be found at www.bioinf.wits.ac.za/~scott/wcdsupp.html.
wcd系统是一种用于对表达序列标签(EST)以及其他DNA和RNA序列进行聚类的开源工具。wcd允许使用d(2)距离函数或编辑距离对EST进行高效的全对全比较,改进了d(2)的现有实现方式。它支持聚类的合并、细化和重新聚类。它与StackPack聚类软件包“即插即用”兼容。wcd在共享内存和集群架构下均支持并行化。它随附一个EMBOSS包装器,允许将wcd作为EMBOSS安装的一部分进行安装(因此可由网络服务器提供)。
wcd根据GPL许可进行分发,可从http://code.google.com/p/wcdest获取。
更多实验结果。wcd手册、一篇描述基础算法的配套论文以及所有用于实验的数据集也可在www.bioinf.wits.ac.za/~scott/wcdsupp.html上找到。