Judson Richard, Elloumi Fathi, Setzer R Woodrow, Li Zhen, Shah Imran
National Center for Computational Toxicology, Office of Research and Development, US Environmental Protection Agency, Research Triangle Park, North Carolina 27711, USA.
BMC Bioinformatics. 2008 May 19;9:241. doi: 10.1186/1471-2105-9-241.
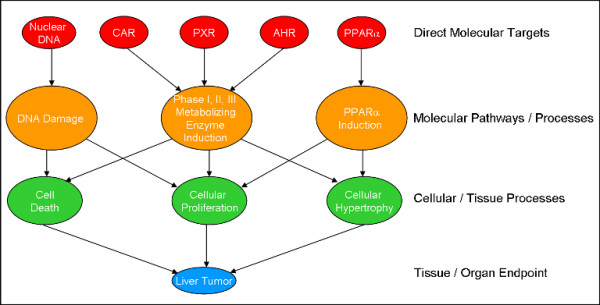
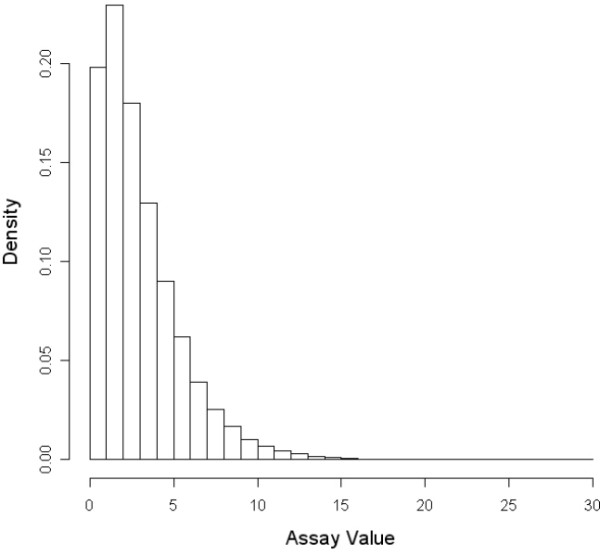
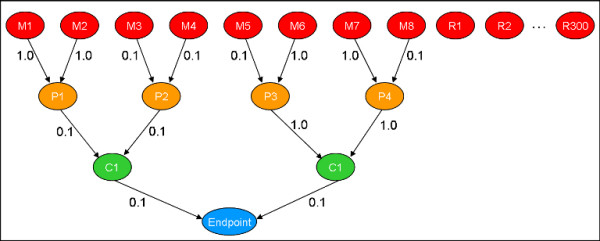
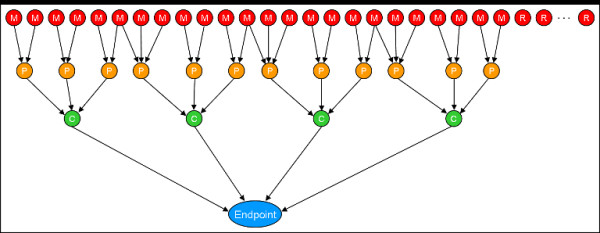
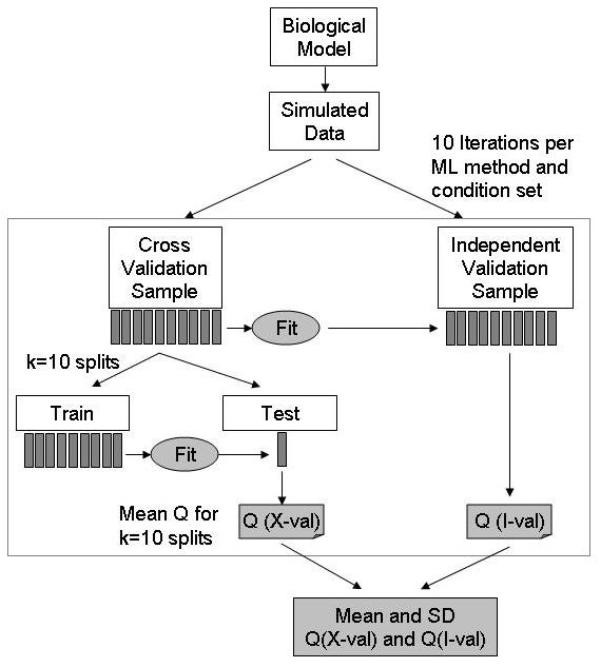
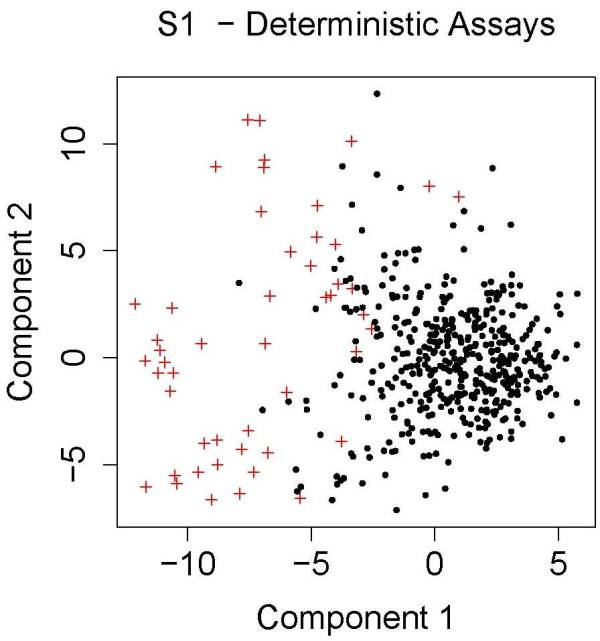
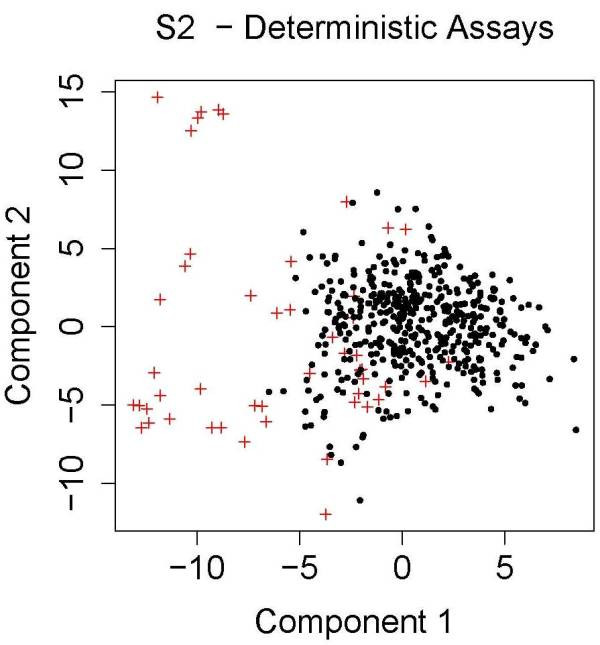
Bioactivity profiling using high-throughput in vitro assays can reduce the cost and time required for toxicological screening of environmental chemicals and can also reduce the need for animal testing. Several public efforts are aimed at discovering patterns or classifiers in high-dimensional bioactivity space that predict tissue, organ or whole animal toxicological endpoints. Supervised machine learning is a powerful approach to discover combinatorial relationships in complex in vitro/in vivo datasets. We present a novel model to simulate complex chemical-toxicology data sets and use this model to evaluate the relative performance of different machine learning (ML) methods.
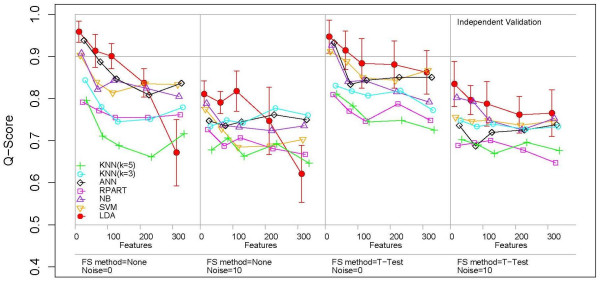
The classification performance of Artificial Neural Networks (ANN), K-Nearest Neighbors (KNN), Linear Discriminant Analysis (LDA), Naïve Bayes (NB), Recursive Partitioning and Regression Trees (RPART), and Support Vector Machines (SVM) in the presence and absence of filter-based feature selection was analyzed using K-way cross-validation testing and independent validation on simulated in vitro assay data sets with varying levels of model complexity, number of irrelevant features and measurement noise. While the prediction accuracy of all ML methods decreased as non-causal (irrelevant) features were added, some ML methods performed better than others. In the limit of using a large number of features, ANN and SVM were always in the top performing set of methods while RPART and KNN (k = 5) were always in the poorest performing set. The addition of measurement noise and irrelevant features decreased the classification accuracy of all ML methods, with LDA suffering the greatest performance degradation. LDA performance is especially sensitive to the use of feature selection. Filter-based feature selection generally improved performance, most strikingly for LDA.
We have developed a novel simulation model to evaluate machine learning methods for the analysis of data sets in which in vitro bioassay data is being used to predict in vivo chemical toxicology. From our analysis, we can recommend that several ML methods, most notably SVM and ANN, are good candidates for use in real world applications in this area.
使用高通量体外试验进行生物活性分析可以降低环境化学品毒理学筛选所需的成本和时间,还可以减少动物试验的需求。几项公共努力旨在在高维生物活性空间中发现预测组织、器官或全动物毒理学终点的模式或分类器。监督式机器学习是在复杂的体外/体内数据集中发现组合关系的强大方法。我们提出了一种新颖的模型来模拟复杂的化学-毒理学数据集,并使用该模型评估不同机器学习(ML)方法的相对性能。
使用K折交叉验证测试和独立验证,对具有不同模型复杂度、无关特征数量和测量噪声水平的模拟体外试验数据集,分析了人工神经网络(ANN)、K近邻(KNN)、线性判别分析(LDA)、朴素贝叶斯(NB)、递归划分和回归树(RPART)以及支持向量机(SVM)在有无基于过滤的特征选择情况下的分类性能。虽然随着非因果(无关)特征的添加,所有ML方法的预测准确性都有所下降,但一些ML方法的表现优于其他方法。在使用大量特征的极限情况下,ANN和SVM始终处于表现最佳的方法组中,而RPART和KNN(k = 5)始终处于表现最差的方法组中。测量噪声和无关特征的添加降低了所有ML方法的分类准确性,其中LDA的性能下降最为明显。LDA的性能对特征选择的使用特别敏感。基于过滤的特征选择通常会提高性能,对LDA最为显著。
我们开发了一种新颖的模拟模型,用于评估机器学习方法在分析体外生物测定数据用于预测体内化学毒理学的数据集中的性能。通过我们的分析,我们可以推荐几种ML方法,最值得注意的是SVM和ANN,是该领域实际应用的良好候选方法。