Fong Jessica H, Marchler-Bauer Aron
National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, 8600 Rockville Pike, Bethesda, MD 20894, USA.
BMC Res Notes. 2008 Nov 14;1:114. doi: 10.1186/1756-0500-1-114.
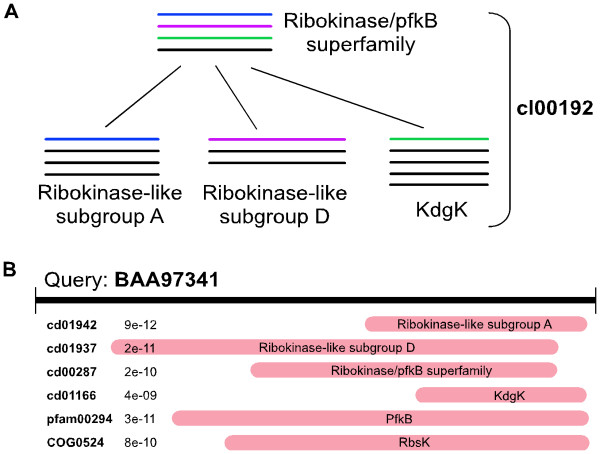
Domains, evolutionarily conserved units of proteins, are widely used to classify protein sequences and infer protein function. Often, two or more overlapping domain models match a region of a protein sequence. Therefore, procedures are required to choose appropriate domain annotations for the protein. Here, we propose a method for assigning NCBI-curated domains from the Curated Domain Database (CDD) that takes into account the organization of the domains into hierarchies of homologous domain models.
Our analysis of alignment scores from NCBI-curated domain assignments suggests that identifying the correct model among closely related models is more difficult than choosing between non-overlapping domain models. We find that simple heuristics based on sorting scores and domain-specific thresholds are effective at reducing classification error. In fact, in our test set, the heuristics result in almost 90% of current misclassifications due to missing domain subfamilies being replaced by more generic domain assignments, thereby eliminating a significant amount of error within the database.
Our proposed domain subfamily assignment rule has been incorporated into the CD-Search software for assigning CDD domains to query protein sequences and has significantly improved pre-calculated domain annotations on protein sequences in NCBI's Entrez resource.
结构域作为蛋白质的进化保守单位,被广泛用于蛋白质序列分类和功能推断。通常,两个或更多重叠的结构域模型会匹配蛋白质序列的一个区域。因此,需要相应程序来为蛋白质选择合适的结构域注释。在此,我们提出一种从精选结构域数据库(CDD)中分配NCBI精选结构域的方法,该方法考虑了结构域在同源结构域模型层次结构中的组织方式。
我们对NCBI精选结构域分配的比对分数分析表明,在密切相关的模型中识别正确模型比在非重叠结构域模型之间进行选择更为困难。我们发现基于排序分数和特定结构域阈值的简单启发式方法在减少分类错误方面很有效。事实上,在我们的测试集中,这些启发式方法使得几乎90%因缺少结构域亚家族而导致的当前错误分类被更通用的结构域分配所取代,从而消除了数据库中的大量错误。
我们提出的结构域亚家族分配规则已被纳入CD-Search软件,用于为查询蛋白质序列分配CDD结构域,并显著改进了NCBI的Entrez资源中蛋白质序列的预先计算的结构域注释。