Marschall Tobias, Rahmann Sven
Computer Science Department, Bioinformatics for High-Throughput Technologies at the Chair of Algorithm Engineering, TU Dortmund, Dortmund, Germany.
Bioinformatics. 2009 Jun 15;25(12):i356-64. doi: 10.1093/bioinformatics/btp188.
The motif discovery problem consists of finding over-represented patterns in a collection of biosequences. It is one of the classical sequence analysis problems, but still has not been satisfactorily solved in an exact and efficient manner. This is partly due to the large number of possibilities of defining the motif search space and the notion of over-representation. Even for well-defined formalizations, the problem is frequently solved in an ad hoc manner with heuristics that do not guarantee to find the best motif.
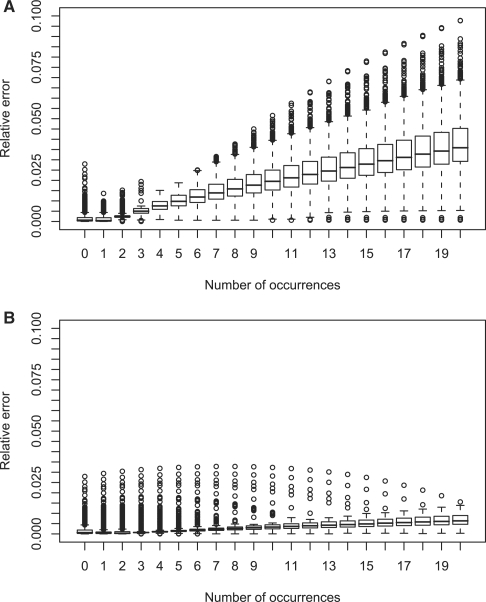
We show how to solve the motif discovery problem (almost) exactly on a practically relevant space of IUPAC generalized string patterns, using the p-value with respect to an i.i.d. model or a Markov model as the measure of over-representation. In particular, (i) we use a highly accurate compound Poisson approximation for the null distribution of the number of motif occurrences. We show how to compute the exact clump size distribution using a recently introduced device called probabilistic arithmetic automaton (PAA). (ii) We define two p-value scores for over-representation, the first one based on the total number of motif occurrences, the second one based on the number of sequences in a collection with at least one occurrence. (iii) We describe an algorithm to discover the optimal pattern with respect to either of the scores. The method exploits monotonicity properties of the compound Poisson approximation and is by orders of magnitude faster than exhaustive enumeration of IUPAC strings (11.8 h compared with an extrapolated runtime of 4.8 years). (iv) We justify the use of the proposed scores for motif discovery by showing our method to outperform other motif discovery algorithms (e.g. MEME, Weeder) on benchmark datasets. We also propose new motifs on Mycobacterium tuberculosis.
The method has been implemented in Java. It can be obtained from http://ls11-www.cs.tu-dortmund.de/people/marschal/paa_md/.
基序发现问题包括在生物序列集合中寻找过度出现的模式。它是经典的序列分析问题之一,但仍未以精确且高效的方式得到令人满意的解决。部分原因在于定义基序搜索空间的可能性众多以及过度出现的概念。即使对于定义明确的形式化问题,该问题也常常通过不保证能找到最佳基序的启发式方法临时解决。
我们展示了如何在IUPAC广义字符串模式的实际相关空间上(几乎)精确地解决基序发现问题,使用相对于独立同分布模型或马尔可夫模型的p值作为过度出现的度量。具体而言,(i)我们对基序出现次数的零分布使用高度精确的复合泊松近似。我们展示了如何使用最近引入的称为概率算术自动机(PAA)的工具来计算精确的聚集大小分布。(ii)我们为过度出现定义了两个p值分数,第一个基于基序出现的总数,第二个基于集合中至少出现一次的序列数量。(iii)我们描述了一种算法,用于发现相对于这两个分数中任何一个的最优模式。该方法利用了复合泊松近似的单调性属性,并且比IUPAC字符串的穷举枚举快几个数量级(11.8小时与外推运行时间4.8年相比)。(iv)通过在基准数据集上展示我们的方法优于其他基序发现算法(例如MEME、Weeder),我们证明了所提出的分数用于基序发现的合理性。我们还在结核分枝杆菌上提出了新的基序。
该方法已用Java实现。可从http://ls11 - www.cs.tu - dortmund.de/people/marschal/paa_md/获取。