Department of Radiology, Mayo Clinic, Rochester, MN 55905, USA.
J Digit Imaging. 2010 Apr;23(2):119-32. doi: 10.1007/s10278-009-9215-7. Epub 2009 May 30.
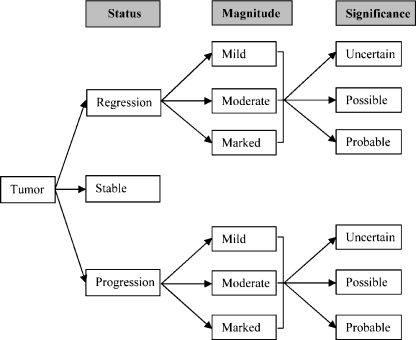
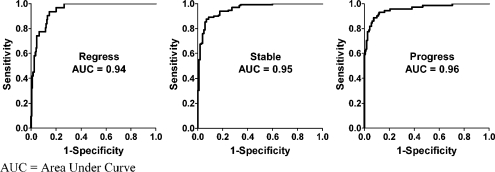
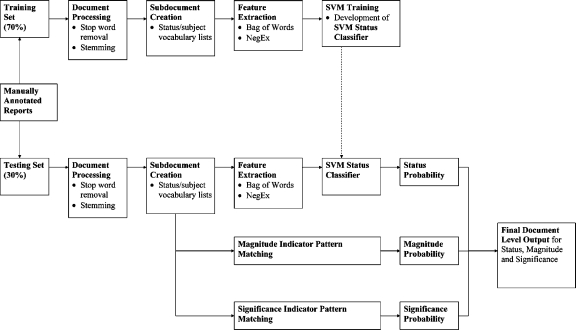
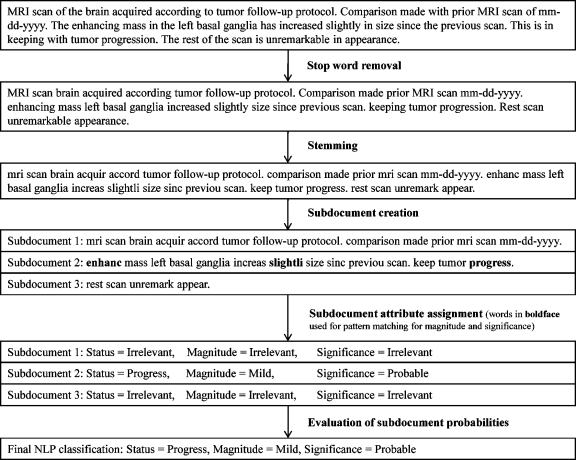
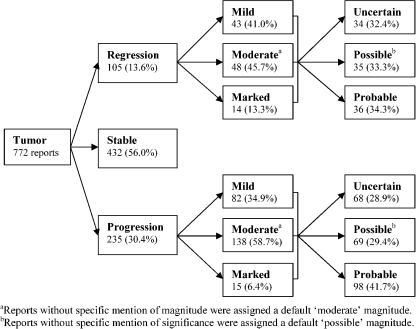
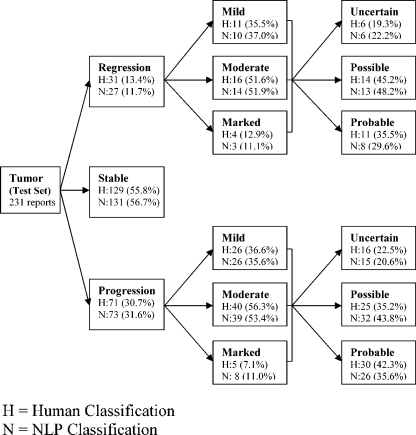
Information in electronic medical records is often in an unstructured free-text format. This format presents challenges for expedient data retrieval and may fail to convey important findings. Natural language processing (NLP) is an emerging technique for rapid and efficient clinical data retrieval. While proven in disease detection, the utility of NLP in discerning disease progression from free-text reports is untested. We aimed to (1) assess whether unstructured radiology reports contained sufficient information for tumor status classification; (2) develop an NLP-based data extraction tool to determine tumor status from unstructured reports; and (3) compare NLP and human tumor status classification outcomes. Consecutive follow-up brain tumor magnetic resonance imaging reports (2000--2007) from a tertiary center were manually annotated using consensus guidelines on tumor status. Reports were randomized to NLP training (70%) or testing (30%) groups. The NLP tool utilized a support vector machines model with statistical and rule-based outcomes. Most reports had sufficient information for tumor status classification, although 0.8% did not describe status despite reference to prior examinations. Tumor size was unreported in 68.7% of documents, while 50.3% lacked data on change magnitude when there was detectable progression or regression. Using retrospective human classification as the gold standard, NLP achieved 80.6% sensitivity and 91.6% specificity for tumor status determination (mean positive predictive value, 82.4%; negative predictive value, 92.0%). In conclusion, most reports contained sufficient information for tumor status determination, though variable features were used to describe status. NLP demonstrated good accuracy for tumor status classification and may have novel application for automated disease status classification from electronic databases.
电子病历中的信息通常采用非结构化的自由文本格式。这种格式给快速有效的临床数据检索带来了挑战,并且可能无法传达重要的发现。自然语言处理 (NLP) 是一种新兴的技术,可以快速有效地检索临床数据。虽然在疾病检测方面已经得到验证,但 NLP 在从自由文本报告中辨别疾病进展方面的效用尚未经过测试。我们的目的是:(1)评估非结构化放射学报告是否包含足够的信息用于肿瘤状态分类;(2)开发一种基于 NLP 的数据提取工具,用于从非结构化报告中确定肿瘤状态;(3)比较 NLP 和人工肿瘤状态分类结果。采用肿瘤状态共识指南对来自一家三级医院的连续随访脑肿瘤磁共振成像报告(2000-2007 年)进行手动注释。报告被随机分为 NLP 训练(70%)或测试(30%)组。NLP 工具使用带有统计和基于规则的输出的支持向量机模型。虽然 0.8%的报告没有描述状态,但大多数报告都包含足够的信息用于肿瘤状态分类,尽管有参考先前的检查。肿瘤大小在 68.7%的文件中未报告,而在有可检测的进展或消退时,50.3%的文件缺乏关于变化幅度的数据。使用回顾性人工分类作为金标准,NLP 对肿瘤状态确定的灵敏度为 80.6%,特异性为 91.6%(平均阳性预测值为 82.4%;阴性预测值为 92.0%)。总之,大多数报告包含足够的信息用于肿瘤状态的确定,尽管使用了不同的特征来描述状态。NLP 对肿瘤状态分类具有较高的准确性,并且可能在从电子数据库中自动进行疾病状态分类方面具有新的应用。