Computer Engineering Dept, Bilkent University, Center for Bioinformatics, Ankara, Turkey.
BMC Bioinformatics. 2009 Nov 16;10:376. doi: 10.1186/1471-2105-10-376.
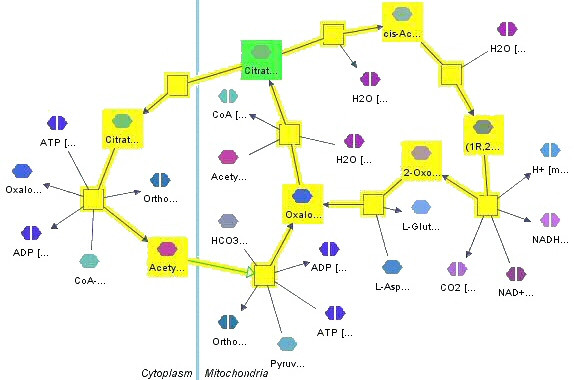
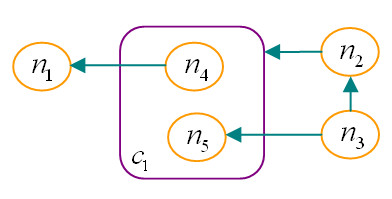
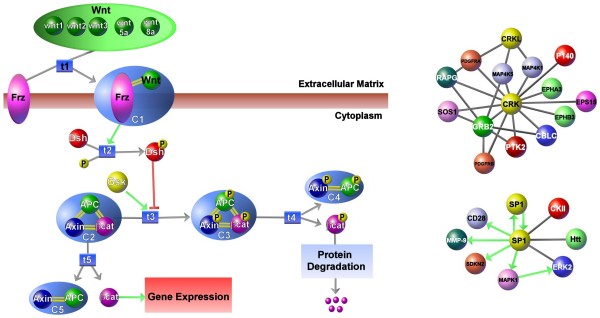
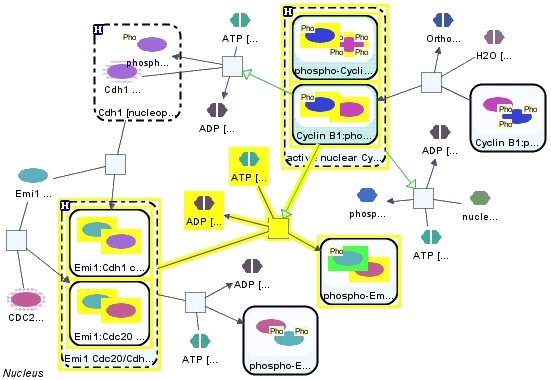
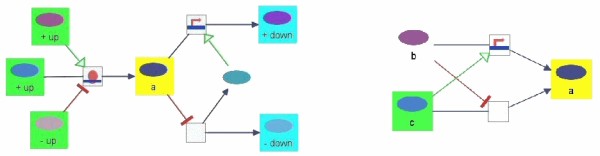
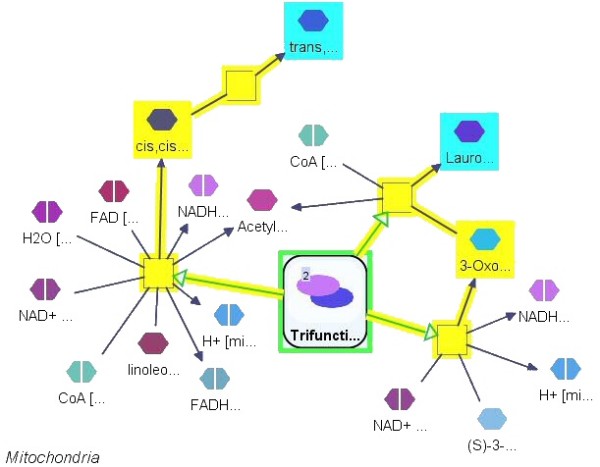
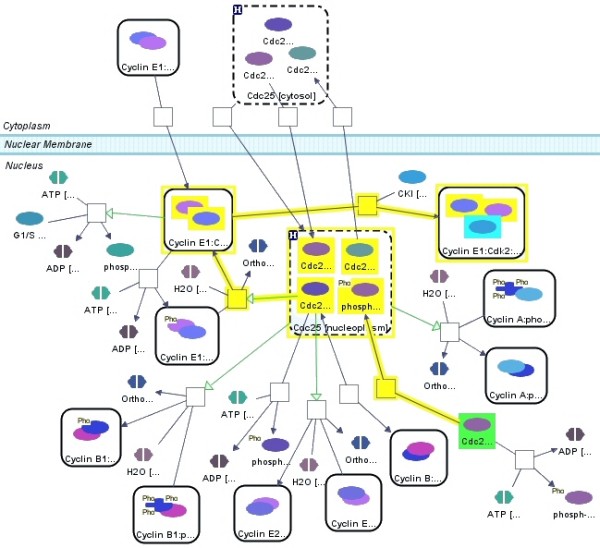
Graph-based pathway ontologies and databases are widely used to represent data about cellular processes. This representation makes it possible to programmatically integrate cellular networks and to investigate them using the well-understood concepts of graph theory in order to predict their structural and dynamic properties. An extension of this graph representation, namely hierarchically structured or compound graphs, in which a member of a biological network may recursively contain a sub-network of a somehow logically similar group of biological objects, provides many additional benefits for analysis of biological pathways, including reduction of complexity by decomposition into distinct components or modules. In this regard, it is essential to effectively query such integrated large compound networks to extract the sub-networks of interest with the help of efficient algorithms and software tools.
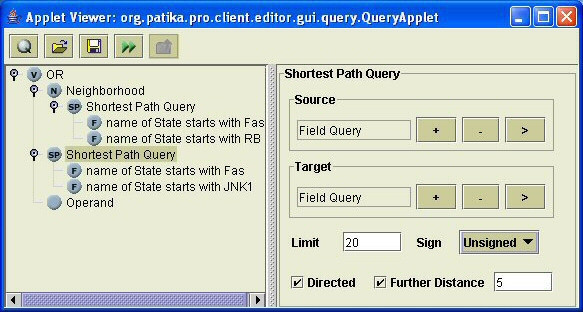
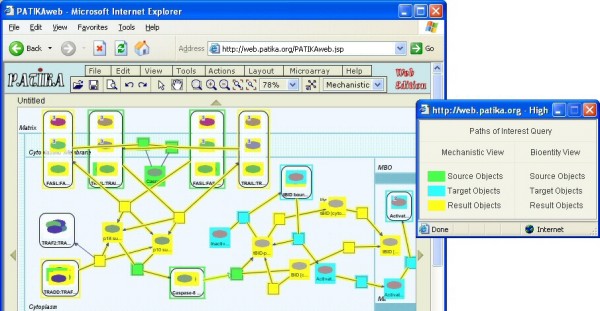
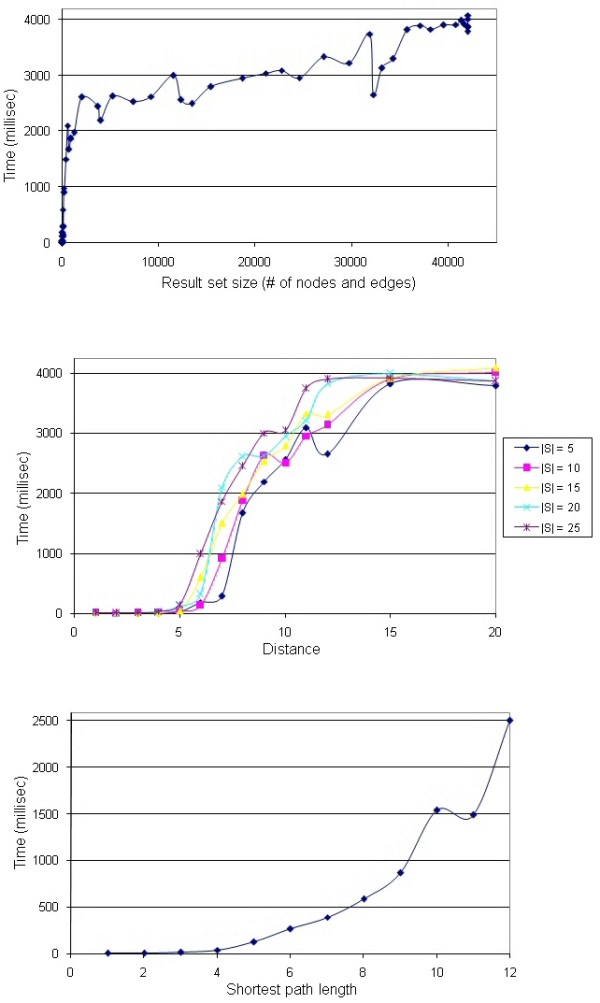
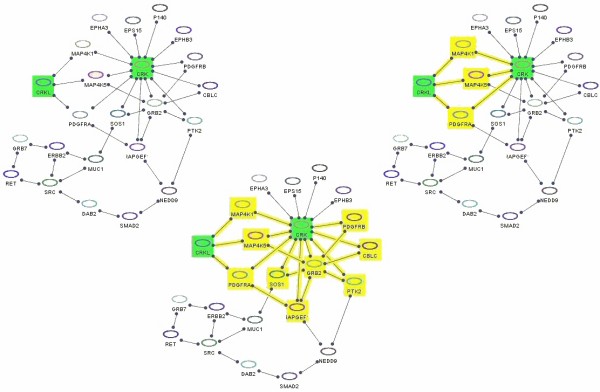
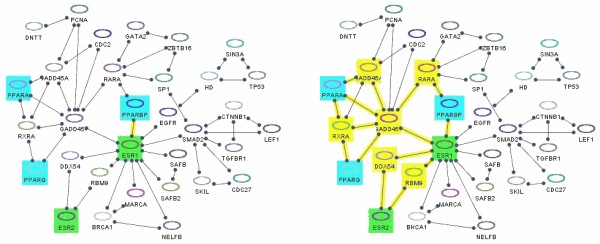
Towards this goal, we developed a querying framework, along with a number of graph-theoretic algorithms from simple neighborhood queries to shortest paths to feedback loops, that is applicable to all sorts of graph-based pathway databases, from PPIs (protein-protein interactions) to metabolic and signaling pathways. The framework is unique in that it can account for compound or nested structures and ubiquitous entities present in the pathway data. In addition, the queries may be related to each other through "AND" and "OR" operators, and can be recursively organized into a tree, in which the result of one query might be a source and/or target for another, to form more complex queries. The algorithms were implemented within the querying component of a new version of the software tool PATIKAweb (Pathway Analysis Tool for Integration and Knowledge Acquisition) and have proven useful for answering a number of biologically significant questions for large graph-based pathway databases.
The PATIKA Project Web site is http://www.patika.org. PATIKAweb version 2.1 is available at http://web.patika.org.
基于图的通路本体和数据库被广泛用于表示细胞过程的数据。这种表示形式使得能够以编程方式集成细胞网络,并使用图论的成熟概念对其进行研究,从而预测其结构和动态特性。这种图表示的扩展,即层次结构或复合图,其中生物网络的成员可以递归地包含具有某种逻辑相似性的生物对象组的子网络,为生物通路的分析提供了许多额外的好处,包括通过分解为不同的组件或模块来降低复杂性。在这方面,有效地查询此类集成的大型复合网络以借助有效的算法和软件工具提取感兴趣的子网络是至关重要的。
为了实现这一目标,我们开发了一个查询框架,以及一些图论算法,从简单的邻居查询到最短路径再到反馈循环,适用于各种基于图的通路数据库,从蛋白质-蛋白质相互作用(PPIs)到代谢和信号通路。该框架的独特之处在于它可以考虑通路数据中存在的复合或嵌套结构和普遍实体。此外,查询可以通过“AND”和“OR”运算符相互关联,并可以递归地组织成一棵树,其中一个查询的结果可能是另一个查询的源和/或目标,以形成更复杂的查询。该算法已在 PATIKAweb 软件工具的新版本的查询组件中实现,并已证明对回答基于大型图的通路数据库的许多具有生物学意义的问题非常有用。
PATIKA 项目网站是 http://www.patika.org。PATIKAweb 版本 2.1 可在 http://web.patika.org 获得。