Xie Benhuai, Pan Wei, Shen Xiaotong
Division of Biostatistics, School of Public Health, University of Minnesota,
Electron J Stat. 2008;2:168-212. doi: 10.1214/08-EJS194.
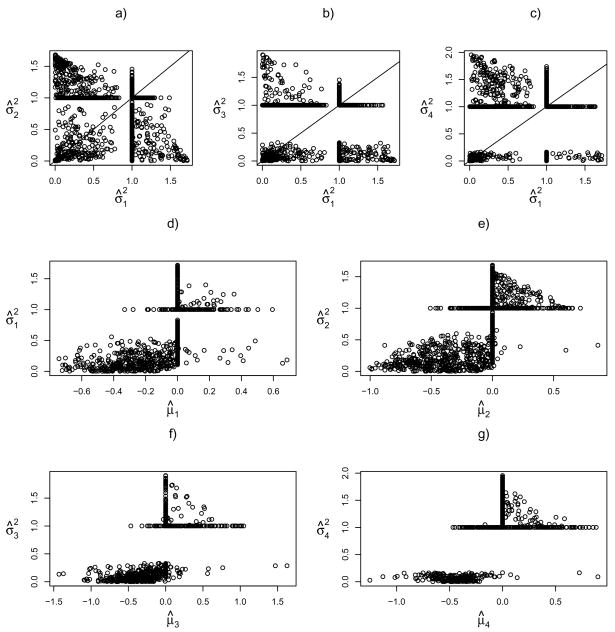
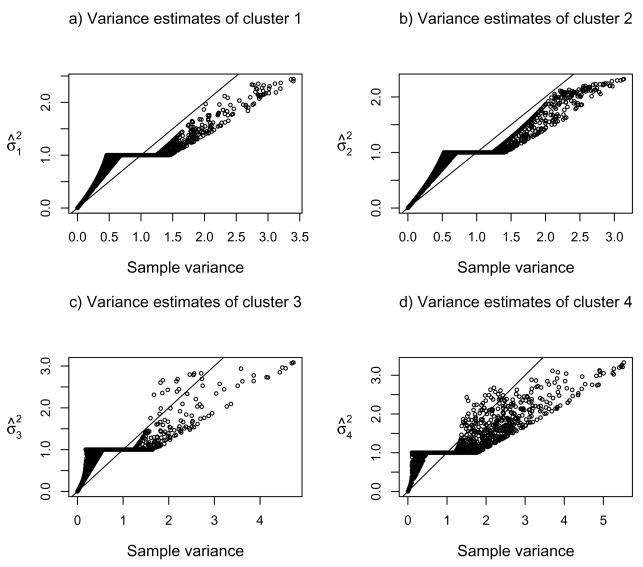
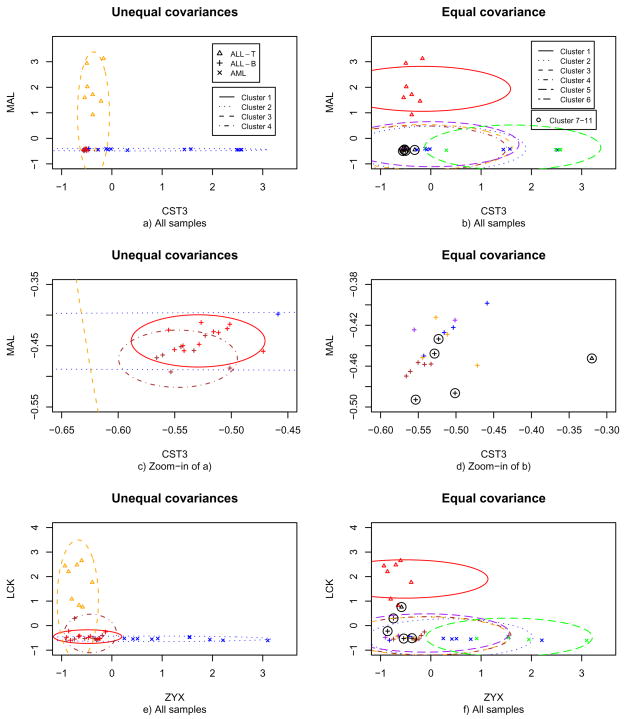
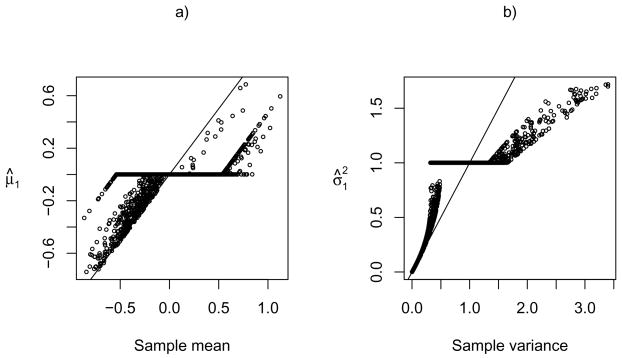
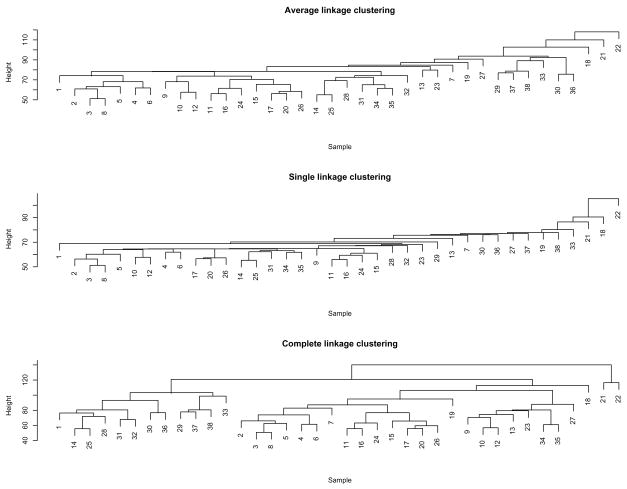
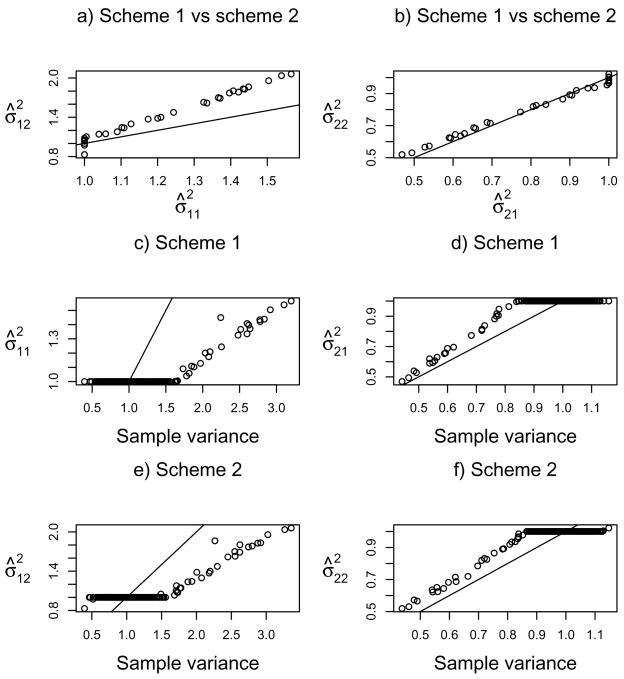
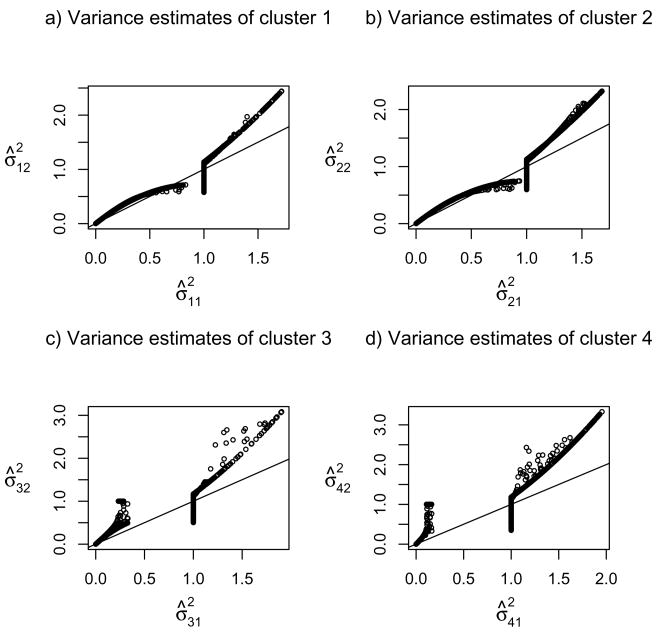
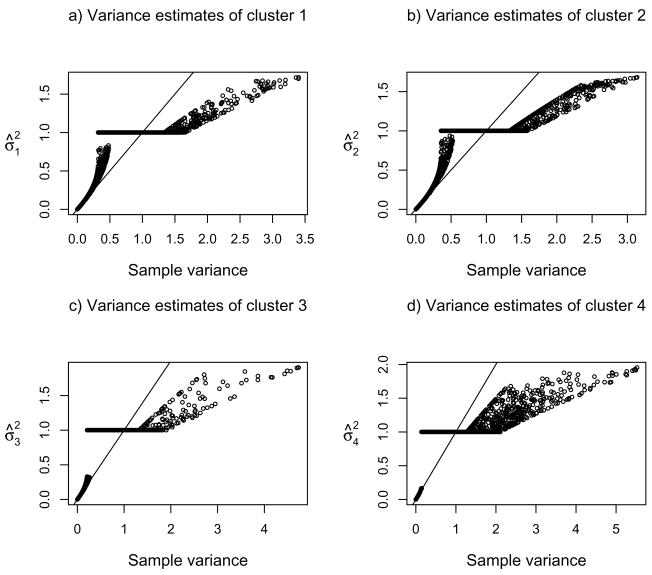
Clustering analysis is one of the most widely used statistical tools in many emerging areas such as microarray data analysis. For microarray and other high-dimensional data, the presence of many noise variables may mask underlying clustering structures. Hence removing noise variables via variable selection is necessary. For simultaneous variable selection and parameter estimation, existing penalized likelihood approaches in model-based clustering analysis all assume a common diagonal covariance matrix across clusters, which however may not hold in practice. To analyze high-dimensional data, particularly those with relatively low sample sizes, this article introduces a novel approach that shrinks the variances together with means, in a more general situation with cluster-specific (diagonal) covariance matrices. Furthermore, selection of grouped variables via inclusion or exclusion of a group of variables altogether is permitted by a specific form of penalty, which facilitates incorporating subject-matter knowledge, such as gene functions in clustering microarray samples for disease subtype discovery. For implementation, EM algorithms are derived for parameter estimation, in which the M-steps clearly demonstrate the effects of shrinkage and thresholding. Numerical examples, including an application to acute leukemia subtype discovery with microarray gene expression data, are provided to demonstrate the utility and advantage of the proposed method.
聚类分析是微阵列数据分析等许多新兴领域中使用最广泛的统计工具之一。对于微阵列数据和其他高维数据,许多噪声变量的存在可能会掩盖潜在的聚类结构。因此,通过变量选择去除噪声变量是必要的。对于同时进行变量选择和参数估计,基于模型的聚类分析中现有的惩罚似然方法都假设各聚类间有一个共同的对角协方差矩阵,但在实际中这可能不成立。为了分析高维数据,特别是那些样本量相对较小的数据,本文介绍了一种新颖的方法,即在具有聚类特定(对角)协方差矩阵的更一般情况下,将方差与均值一起收缩。此外,通过特定形式的惩罚允许通过完全包含或排除一组变量来选择分组变量,这有助于纳入主题知识,例如在对微阵列样本进行聚类以发现疾病亚型时纳入基因功能。为了实现,推导了用于参数估计的期望最大化(EM)算法,其中M步清楚地展示了收缩和阈值化的效果。提供了数值示例,包括将其应用于利用微阵列基因表达数据发现急性白血病亚型,以证明所提出方法的实用性和优势。