Gong Ting, Xuan Jianhua, Wang Chen, Li Huai, Hoffman Eric, Clarke Robert, Wang Yue
Department of Electrical and Computer Engineering, Virginia Polytechnic Institute and State University, Arlington, VA 22203, USA.
Gene Regul Syst Bio. 2008 Jan 15;1:349-63.
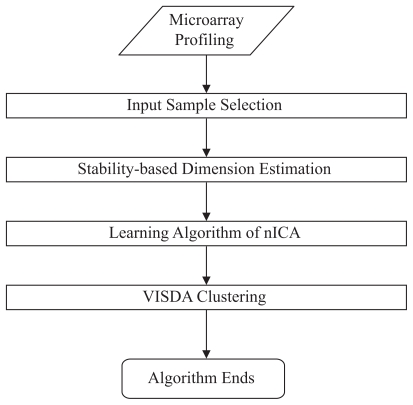
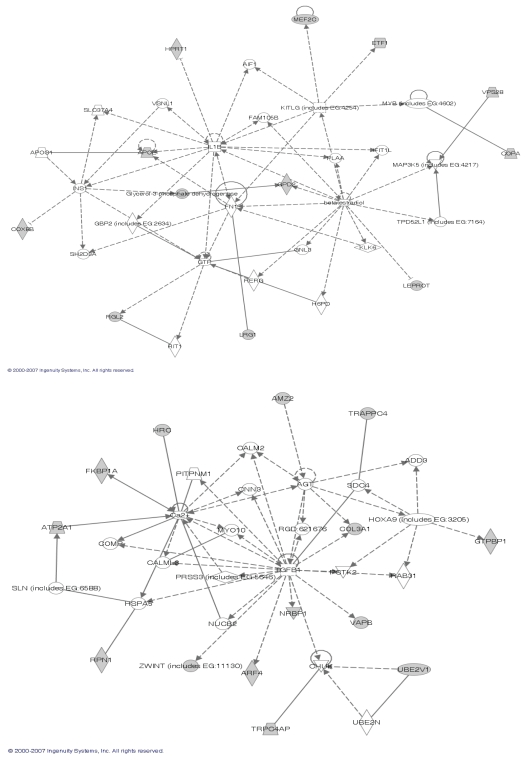
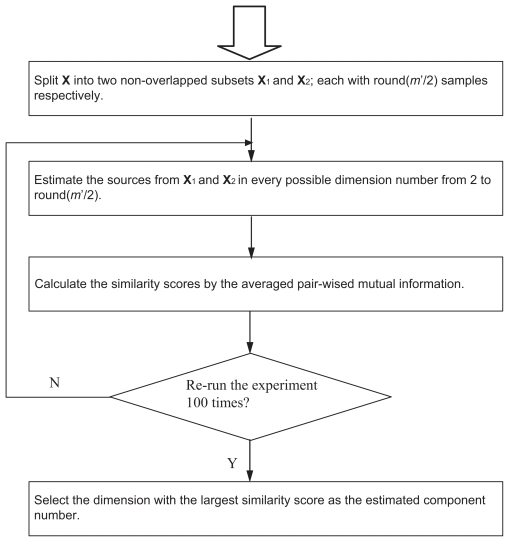
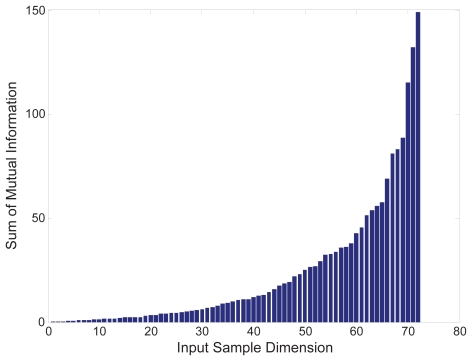
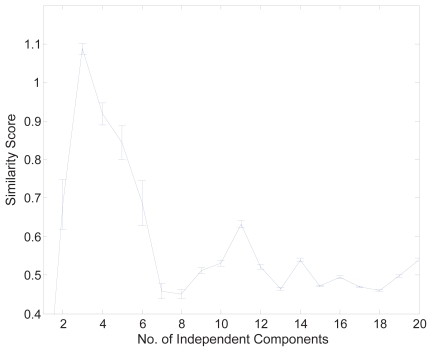
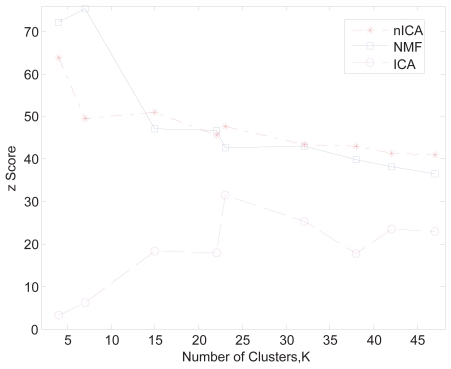
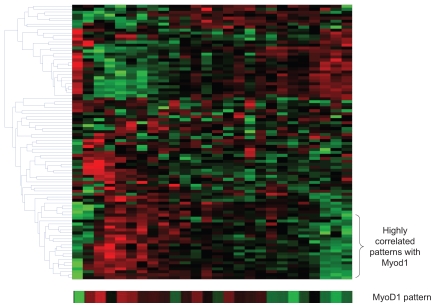
Genes mostly interact with each other to form transcriptional modules for performing single or multiple functions. It is important to unravel such transcriptional modules and to determine how disturbances in them may lead to disease. Here, we propose a non-negative independent component analysis (nICA) approach for transcriptional module discovery. nICA method utilizes the non-negativity constraint to enforce the independence of biological processes within the participated genes. In such, nICA decomposes the observed gene expression into positive independent components, which fits better to the reality of corresponding putative biological processes. In conjunction with nICA modeling, visual statistical data analyzer (VISDA) is applied to group genes into modules in latent variable space. We demonstrate the usefulness of the approach through the identification of composite modules from yeast data and the discovery of pathway modules in muscle regeneration.
基因大多相互作用以形成执行单一或多种功能的转录模块。解析此类转录模块并确定其中的紊乱如何导致疾病非常重要。在此,我们提出一种用于转录模块发现的非负独立成分分析(nICA)方法。nICA方法利用非负约束来加强参与基因内生物过程的独立性。这样,nICA将观察到的基因表达分解为正独立成分,这更符合相应假定生物过程的实际情况。结合nICA建模,视觉统计数据分析器(VISDA)用于在潜在变量空间中将基因分组为模块。我们通过从酵母数据中识别复合模块以及在肌肉再生中发现通路模块来证明该方法的实用性。