Gao Shouguo, Wang Xujing
Department of Physics & the Comprehensive Diabetes Center, University of Alabama at Birmingham, 1300 University Blvd, Birmingham, AL 35294, USA.
J Comput Sci Syst Biol. 2009 Apr 1;2:133. doi: 10.4172/jcsb.1000025.
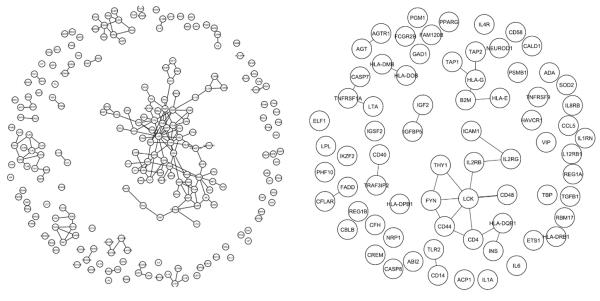
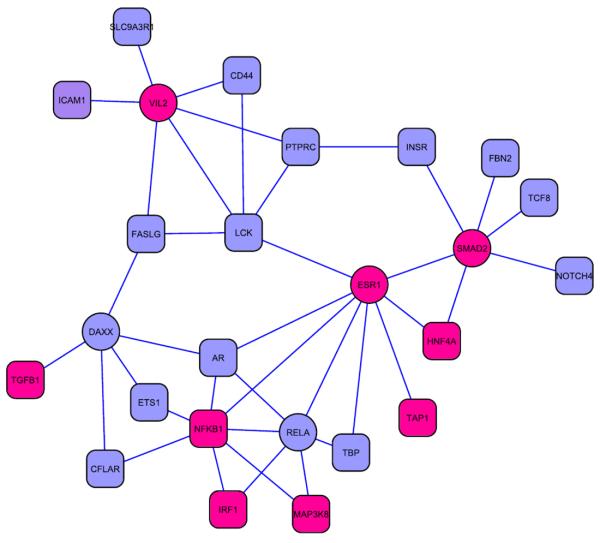
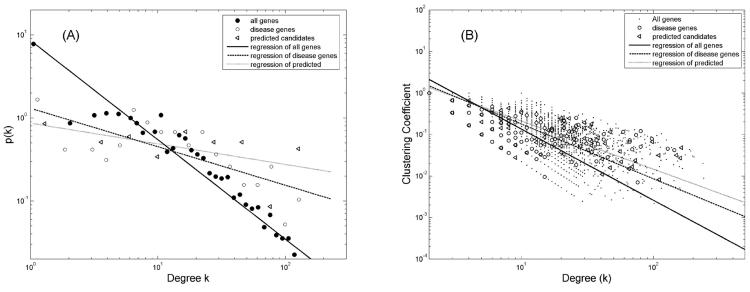
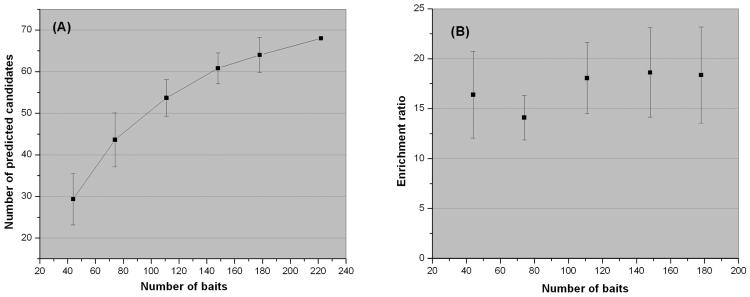
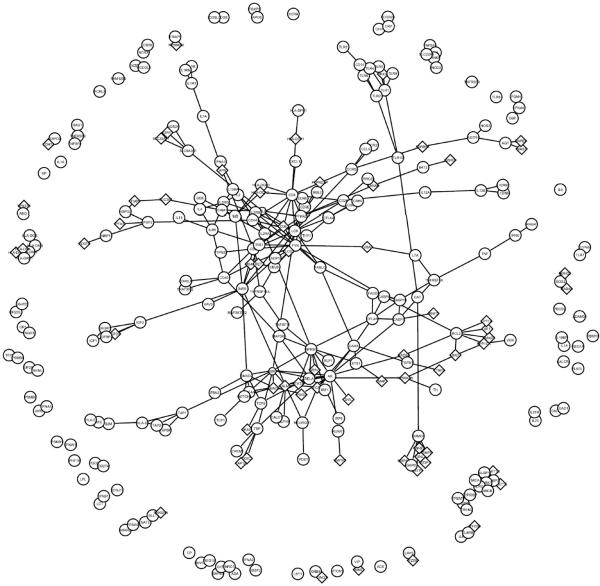
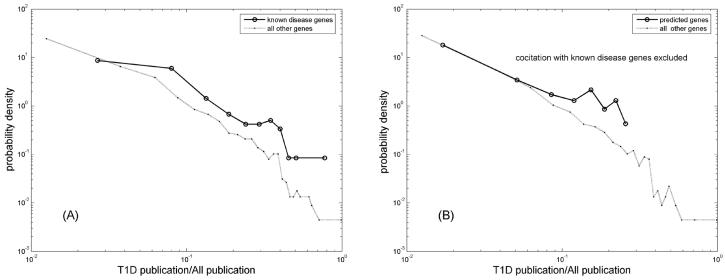
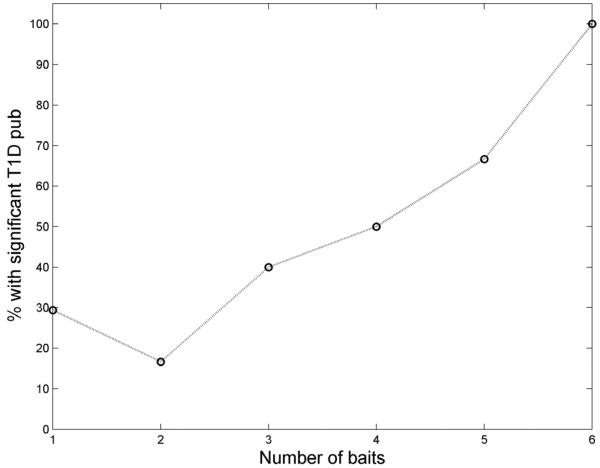
Proteins directly interacting with each other tend to have similar functions and be involved in the same cellular processes. Mutations in genes that code for them often lead to the same family of disease phenotypes. Efforts have been made to prioritize positional candidate genes for complex diseases utilize the protein-protein interaction (PPI) information. But such an approach is often considered too general to be practically useful for specific diseases. RESULTS: In this study we investigate the efficacy of this approach in type 1 diabetes (T1D). 266 known disease genes, and 983 positional candidate genes from the 18 established linkage loci of T1D, are compiled from the T1Dbase (http://t1dbase.org). We found that the PPI network of known T1D genes has distinct topological features from others, with significantly higher number of interactions among themselves even after adjusting for their high network degrees (p<1e-5). We then define those positional candidates that are first degree PPI neighbours of the 266 known disease genes to be new candidate disease genes. This leads to a list of 68 genes for further study. Cross validation using the known disease genes as benchmark reveals that the enrichment is ~17.1 fold over random selection, and ~4 fold better than using the linkage information alone. We find that the citations of the new candidates in T1D-related publications are significantly (p<1e-7) more than random, even after excluding the co-citation with the known disease genes; they are significantly over-represented (p<1e-10) in the top 30 GO terms shared by known disease genes. Furthermore, sequence analysis reveals that they contain significantly (p<0.0004) more protein domains that are known to be relevant to T1D. These findings provide indirect validation of the newly predicted candidates. CONCLUSION: Our study demonstrates the potential of the PPI information in prioritizing positional candidate genes for T1D.
相互直接作用的蛋白质往往具有相似的功能,并参与相同的细胞过程。编码这些蛋白质的基因突变通常会导致同一类疾病表型。人们已努力利用蛋白质-蛋白质相互作用(PPI)信息对复杂疾病的定位候选基因进行优先级排序。但这种方法通常被认为过于笼统,对特定疾病实际用处不大。
在本研究中,我们调查了这种方法在1型糖尿病(T1D)中的有效性。从T1Dbase(http://t1dbase.org)汇编了266个已知疾病基因以及来自T1D的18个已确定连锁位点的983个定位候选基因。我们发现,已知T1D基因的PPI网络具有与其他网络不同的拓扑特征,即使在调整其高网络度后,它们之间的相互作用数量仍显著更多(p<1e - 5)。然后,我们将那些作为266个已知疾病基因的一度PPI邻居的定位候选基因定义为新的候选疾病基因。这产生了一份68个基因的列表以供进一步研究。以已知疾病基因为基准进行交叉验证表明,富集度比随机选择高约17.1倍,比仅使用连锁信息好约4倍。我们发现,即使排除与已知疾病基因的共引用,新候选基因在T1D相关出版物中的引用也显著多于随机情况(p<1e - 7);它们在已知疾病基因共有的前30个GO术语中显著过度富集(p<1e - 10)。此外,序列分析表明,它们包含显著更多(p<0.0004)已知与T1D相关的蛋白质结构域。这些发现为新预测的候选基因提供了间接验证。
我们的研究证明了PPI信息在对T1D的定位候选基因进行优先级排序方面的潜力。