Centre for Addiction and Mental Health (CAMH), 33 Russell Street, Toronto, Ontario, M5S 2S1, Canada.
Popul Health Metr. 2010 Mar 4;8:3. doi: 10.1186/1478-7954-8-3.
Alcohol consumption is a major risk factor in the global burden of disease, with overall volume of exposure as the principal underlying dimension. Two main sources of data on volume of alcohol exposure are available: surveys and per capita consumption derived from routine statistics such as taxation. As both sources have significant problems, this paper presents an approach that triangulates information from both sources into disaggregated estimates in line with the overall level of per capita consumption.
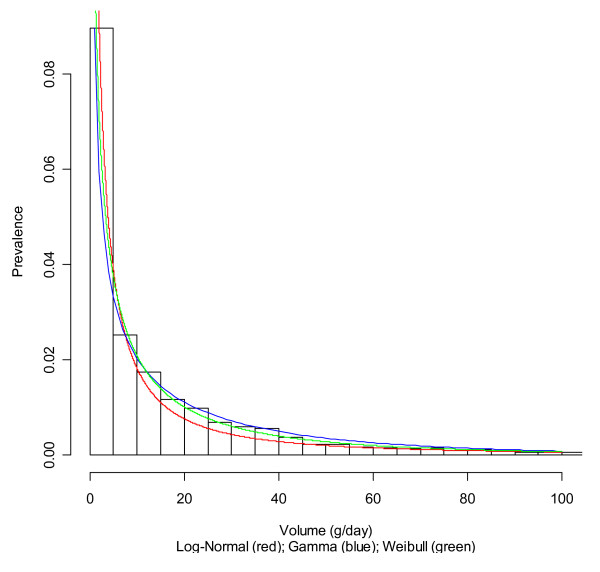
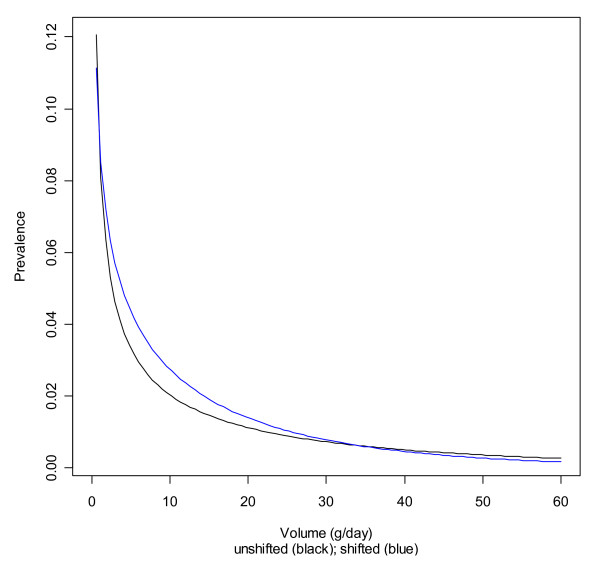
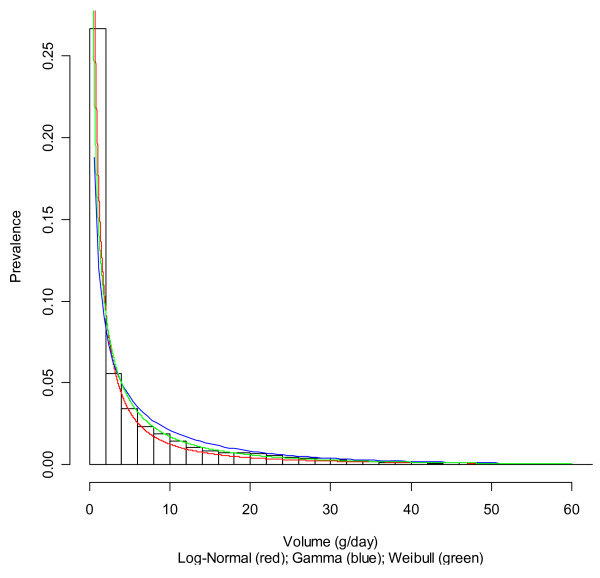
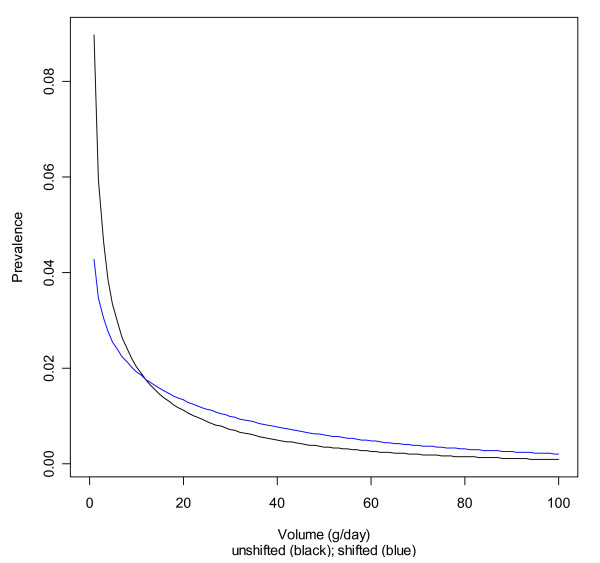
A modeling approach was applied to the US using data from a large and representative survey, the National Epidemiologic Survey on Alcohol and Related Conditions. Different distributions (log-normal, gamma, Weibull) were used to model consumption among drinkers in subgroups defined by sex, age, and ethnicity. The gamma distribution was used to shift the fitted distributions in line with the overall volume as derived from per capita estimates. Implications for alcohol-attributable fractions were presented, using liver cirrhosis as an example.
The triangulation of survey data with aggregated per capita consumption data proved feasible and allowed for modeling of alcohol exposure disaggregated by sex, age, and ethnicity. These models can be used in combination with risk relations for burden of disease calculations. Sensitivity analyses showed that the gamma distribution chosen yielded very similar results in terms of fit and alcohol-attributable mortality as the other tested distributions.
Modeling alcohol consumption via the gamma distribution was feasible. To further refine this approach, research should focus on the main assumptions underlying the approach to explore differences between volume estimates derived from surveys and per capita consumption figures.
饮酒是全球疾病负担的一个主要风险因素,暴露总量是主要的潜在维度。有两种主要的酒精暴露量数据来源:调查和人均消费,分别来自税收等常规统计数据。由于这两种来源都存在重大问题,本文提出了一种方法,即将这两种来源的信息通过三角测量法整合为符合人均消费水平的细分估计值。
该方法应用于美国,使用了来自大型代表性调查——国家酒精和相关条件流行病学调查的数据。对数正态分布、伽马分布和威布尔分布被用于对按性别、年龄和种族划分的饮酒者亚组进行消费建模。伽马分布用于根据人均估计值得出的总体体积来调整拟合分布。本文以肝硬化为例,介绍了酒精归因分数的影响。
调查数据与汇总的人均消费数据的三角测量证明是可行的,并允许按性别、年龄和种族对酒精暴露进行细分建模。这些模型可与疾病负担计算中的风险关系结合使用。敏感性分析表明,所选的伽马分布在拟合度和归因于酒精的死亡率方面与其他测试的分布非常相似。
通过伽马分布对酒精消费进行建模是可行的。为了进一步完善这种方法,研究应侧重于探索调查和人均消费数据之间差异的方法的主要假设。