Institute for Molecular Bioscience, The University of Queensland, Brisbane 4072, Queensland, Australia.
BMC Bioinformatics. 2010 Apr 9;11:179. doi: 10.1186/1471-2105-11-179.
Position-specific priors have been shown to be a flexible and elegant way to extend the power of Gibbs sampler-based motif discovery algorithms. Information of many types-including sequence conservation, nucleosome positioning, and negative examples-can be converted into a prior over the location of motif sites, which then guides the sequence motif discovery algorithm. This approach has been shown to confer many of the benefits of conservation-based and discriminative motif discovery approaches on Gibbs sampler-based motif discovery methods, but has not previously been studied with methods based on expectation maximization (EM).
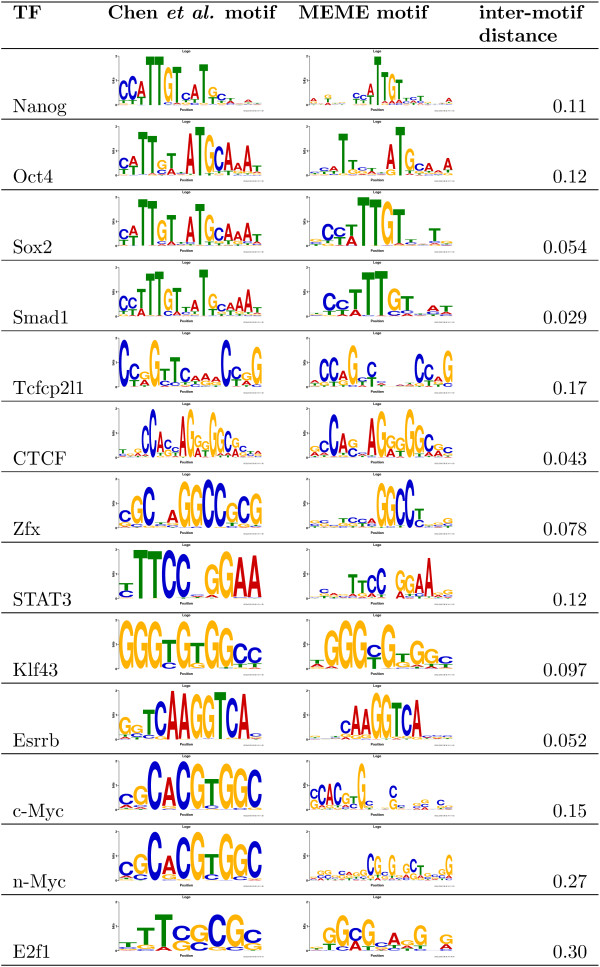
We extend the popular EM-based MEME algorithm to utilize position-specific priors and demonstrate their effectiveness for discovering transcription factor (TF) motifs in yeast and mouse DNA sequences. Utilizing a discriminative, conservation-based prior dramatically improves MEME's ability to discover motifs in 156 yeast TF ChIP-chip datasets, more than doubling the number of datasets where it finds the correct motif. On these datasets, MEME using the prior has a higher success rate than eight other conservation-based motif discovery approaches. We also show that the same type of prior improves the accuracy of motifs discovered by MEME in mouse TF ChIP-seq data, and that the motifs tend to be of slightly higher quality those found by a Gibbs sampling algorithm using the same prior.
We conclude that using position-specific priors can substantially increase the power of EM-based motif discovery algorithms such as MEME algorithm.
已证实,位置特异性先验可以灵活而优雅地扩展基于 Gibbs 抽样器的基序发现算法的能力。包括序列保守性、核小体定位和负例在内的多种信息可以转换为基序位点位置的先验,从而指导序列基序发现算法。这种方法已被证明可将基于保守性和判别性基序发现方法的许多优势赋予基于 Gibbs 抽样器的基序发现方法,但尚未与基于期望最大化 (EM) 的方法一起进行研究。
我们扩展了流行的基于 EM 的 MEME 算法以利用位置特异性先验,并证明了它们在酵母和小鼠 DNA 序列中发现转录因子 (TF) 基序的有效性。利用判别性、基于保守性的先验,显著提高了 MEME 在 156 个酵母 TF ChIP-chip 数据集发现基序的能力,使其在发现正确基序的数据集数量上增加了一倍以上。在这些数据集上,使用先验的 MEME 具有比其他八种基于保守性的基序发现方法更高的成功率。我们还表明,相同类型的先验可提高 MEME 在小鼠 TF ChIP-seq 数据中发现的基序的准确性,并且与使用相同先验的 Gibbs 抽样算法发现的基序相比,所发现的基序的质量略高。
我们得出结论,使用位置特异性先验可以大大提高基于 EM 的基序发现算法(如 MEME 算法)的能力。